今天我們看看如何改進模型的性能,從之前的圖片觀察到那些預測失敗的圖,有些是真的寫得很醜,有些還是很好辨識的,來看看能不能讓那些還能被辨識的圖預測成功,在資料的預處理中,我們將圖片拉成了一個長條,這次我們將更換模型使用的層,讓圖片像素相對位置的資訊得到更好的利用。
這次新增的卷積層,是深度學習在處理圖片方面的問題時常會使用到的層,通常會搭配池化層一起使用,之後視情況再接之前看到過的感知層,這種模型稱為卷積神經網路Convolutional Neural Network-CNN。
這裡不手動建立輸入層,而是做為隱藏層的一個參數,Keras會幫我們處理,預處理時跳過拉成一維的動作。
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
from tensorflow.keras.utils import to_categorical
x_train = x_train.reshape(*x_train.shape, 1) / 255
x_test = x_test.reshape(*x_test.shape, 1) / 255
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
from tensorflow.keras.layers import Conv2D, Dense, Flatten, MaxPool2D
from tensorflow.keras.models import Sequential
model = Sequential()
model.add(
Conv2D(
filters = 64,
input_shape = (28, 28, 1),
kernel_size = (3, 3),
strides = (1, 1),
activation = 'relu'
)
)
model.add(
MaxPool2D(
pool_size = (2, 2)
)
)
model.add(
Conv2D(
filters = 64,
kernel_size = (3, 3),
strides = (1, 1),
activation = 'relu'
)
)
model.add(
MaxPool2D(
pool_size = (2, 2)
)
)
model.add(
Flatten()
)
model.add(
Dense(
units = 10,
activation = 'softmax'
)
)
model.compile(
optimizer = 'adam',
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 64) 640
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1600) 0
_________________________________________________________________
dense (Dense) (None, 10) 16010
=================================================================
Total params: 53,578
Trainable params: 53,578
Non-trainable params: 0
_________________________________________________________________
訓練完進行驗證,可以發現此模型在測試集上的準確度大約提升了1.3~1.8%的幅度,來看看混淆矩陣跟辨識錯誤的圖片。
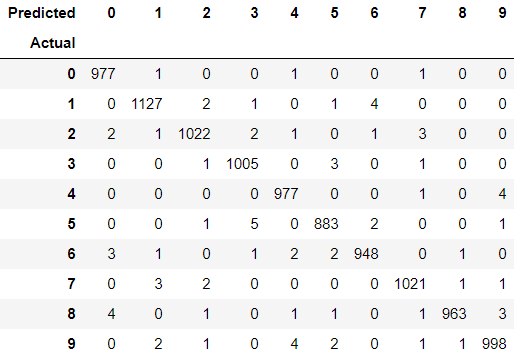
如果之前搭建模型的時候各位有試著加入更多隱藏層或提升神經元數量,會發現權重的數量增加得很快,但是正確率的提升也很難到1%,這次做的模型改動,比原先的增加了5%的權重,就有不錯的效果,可以發現比起堆疊權重的數量,更有效率的組織模型是更好的方法。

