2014 年,正值 word vectors 和 RNN 帶起 NLP 與 deep learning 結合的熱潮,Google 發表了 Seq2Seq 的架構,也就是能夠輸入一個序列,產生另一個序列的 model。
2016 年,建立在 LSTM 和 Seq2Seq 之上,Google NMT (Neural Machine Translation) 正式發表,也讓原本屢受揶揄的 Google 翻譯,大舉提升翻譯準確率與自然度,也讓人窺探到 deep learning 的力量。
Machine translation 是很有歷史性的難題。Google 翻譯是怎麼一步步從最初的 statistical machine translation,一舉打掉重練建立 NMT,並透過 transfer learning 有效率的進行多語言的翻譯?讓我們先從 machine translation 介紹起。
Machine translation 最早可以溯源自九世紀,但一直到二十世紀以前多半還是偏向密碼學的解法,二十世紀電腦出現以後較為自動化的翻譯才比較適合稱為 machine translation。
Machine translation 可以大致分為三種解法:rule-based、statistical machine translation (SMT)、neural machine translation (NMT)。
想像一個剛開始學英文的人,會怎麼把中文翻譯成英文?多半是逐字逐字翻,偶爾加點常見的文法規則在裡頭。
Rule-based system 也是從這個方向起步。大概方法是根據字典逐字轉換,接著再用一些 common grammatical rule 稍微喬一下順序。
這麼 naive 的方法,成果想當然是不太自然的翻譯(very thank you)。缺點包括需要專家來建立 dictionary 和 grammar rules、一些不在字典裡的詞沒有對應的翻譯(特別是 named entity,人名地名組織名等等),基本上呆板的從表面進行翻譯。
不過表面翻譯還是能符合某些需求,例如戰爭時利用 machine translation 翻譯俄文,也大致能從知道他們的意圖,在當時還算堪用。
二十一世紀開始發展了建立在 probability 和 statistics 之上的 statistical machine translation。就像是英文的學習者被丟到美國街頭,藉由大量接觸英文,也能悟出一些沒學過的語法和沒看過的字。
SMT 基本概念是從 training data 裡的統計資訊,學習到 的機率分佈,s 是 source sentence,t 是 target sentence。
Google 也在 2007 年開始發展基於 SMT 的翻譯系統,主要訓練在聯合國和歐洲議會的翻譯文件上。所以小時候有點滑稽的 Google 翻譯結果,都是 SMT 的心血啊。雖然成果上大大超越了 rule-based system,但不足的地方還是很多,特別是文法相差太多的語言會學得比較差。
最後是 2016 年,Google 一舉拋棄發展了十年的 SMT 系統,訓練出了基於 neural network 的 NMT 系統。而事實證明這是非常睿智的改變,成果像是從英文學習者大躍進到雙語母語者啊!
記得前篇我們提到 RNN 是在做 encoding 這件事嗎?以人腦來說 encoding 等同於把文字內化後的理解。而在 NMT 中,會先 encode source text,替他剝除外皮(文法、專屬於這個語言的特性),轉換成單純基於文字理解的 internal representation。再將他附上 target language 的外皮,decode 成 target text。
而這也是雙語母語者翻譯時的腦內流程。他們一看到文字,大概不會逐字記下來再由前往後翻譯,而是馬上理解後以另一種語言傳達出去。這樣的翻譯,不只更流暢精準,甚至 internal representation 因為並不專屬於任何語言,還可以用來做 transfer learning —— 將一個任務中的所學,轉換到另一個任務中做應用。這也是後來更進階的 zero-shot translation 達成的事。
(Sutskever et al., 2014) Sequence to Sequence Learning with Neural Networks
最初版的 Google NMT 是基於一個叫 Seq2Seq 的架構。這個架構在做的事就是上面提到的:將 source text encode 成 internal representation,再 decode 成 target text。
架構如下:

—— Seq2Seq 架構。[3]
左邊的部分在做 encoding,而 <EOS> 代表 end of string,這樣 model 才知道句子結束了。句子結束的同時,model 就從剛剛學好的 internal representation 開始 decode,依序預測 output 的每ㄧ個字,直到預測出 <EOS> 結束。而在 decoding 的部分,每次的 input 會是前一次的預測,model 才知道預測到哪裡了。
可以看出 Seq2Seq 的架構非常簡潔有效,甚至不用把 encoder 和 decoder 分開訓練,直接訓練一個 end-to-end model。
在 paper [3] 中提到實作時還有三個提升 performance 的技巧:
這邊再簡單介紹一個做文字生成時很常用到的 decoding 方法,也是 Seq2Seq 裡使用的 —— beam search。
簡單來說,在根據預測的 probability distribution 生成一個字的時候,最簡單的方法是取 probabilty 最大的字。但他的缺點就是,一旦生成了一個字,到後面後悔了想拿掉卻沒辦法。
舉例來說,翻譯一個中文句子:他用一個派砸我。英文翻譯如果在每步挑選最可能的結果,那可能會是這樣:he uses a pie to hit me。當 model 翻譯到後來發現,咦不對啊應該先翻後面比較順,也來不及了。
Beam search 的概念就是,每步不只生成一種結果,而是每步挑選 k 個最好的可能,並從這 k 個支線再繼續發展下去。如此一來錯過最佳解的機會也能有效降低:

—— Beam search 每步選 k = 2 個可能發展下去。[1]
注意每步的 score 不是根據當下 output 這個字的 probability 計算,而是整個 source text 翻譯成現在 partial result 的 probability:
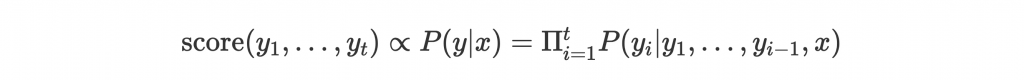
實作時會取 log probability 方便計算,並根據長度 normalize。
Paper 中的 model 訓練在 WMT'14 English to French dataset,並把結果跟 baseline SMT system 比較。除了 BLEU score 從 33.3 提高到 36.5,在長句子和低頻率字方面的 performance 更是顯著提升:

—— Seq2Seq machine translation 在長句子和低頻率字方面的 performance。[3]
BLEU score 是常用在 machine translation 的 metrics,基本上是拿機器翻譯跟幾組人類翻譯比較,看有多少組字 match。
另外還做了 internal representation 的視覺化,可以看出 model 在學習的是文字隱含的意義:

—— Internal representations learned。[3]
以一個最基本的 NMT system 跟一個很成熟的 SMT system 比較,能有如此表現差距足以看出發展潛力。
上面的 Seq2Seq 是一個簡單的開始,而 2016 年發表的 Google NMT 與之架構大致雷同,但做了一些改進:
Residual connection [4] 是指在某個 layer 和前面的 layer 添加 connection,gradient 才能更有效往前層流動:
—— Model 裡的 residual connection。Attention [5] 則是很常加入改善 performance 的技巧,讓 model 學會在 output 時知道要把注意力放在 input 的哪個地方。下一篇會完整介紹。
這些改進讓 BLEU score 提高到了 41.16,而運算效率也有所提升。
Google NMT 提出後也陸續做了很多改進。其中一個是這篇 zero-shot translation,讓不同 language pair 間的 translation 甚至不需要特別訓練,就能從現有的訓練結果 infer。

—— 不同 language pair 的訓練結果轉換。
以上圖為例,假設已經有個訓練好的 Japanese <-> English 和 Korean <-> English translation model,那麼用這兩個 model 訓練好的 parameter,可以直接取得 Japanese <-> Korean 的 translation model。這種把在一個 model 的學習成果拿來直接應用在別的 model,就是 transfer learning。而這種 infer 的 model 從來沒看過 Japanese <-> Korean 的翻譯,卻能學會怎麼翻譯,也叫做 zero-shot learning。

—— Sentence embedding 視覺化。
上圖則是 74 組三個語言意思相同的句子,在 translation 過程中得到的 sentence embedding(他們稱為 context vector)視覺化的結果。同一個顏色代表同一組句子。可以看到同樣意思不同語言的 embedding 都能聚集在一起,也印證了 transfer learning 能成功的原因。
運用 zero-shot learning 大幅減少了所需的 parallel corpora(成對的 corpus)和訓練資源,也是現在 multilingual Google NMT 的基礎。
Google NMT 之後也多次做了改進,例如改採 transformer model、加入 adversarial example 做 training 改善穩定性等等。有興趣的可以讀讀看延伸閱讀的連結。
Google 也很貼心的提供了 NMT 的 TensorFlow tutorial,對深度理解他們的架構也很有幫助!



 iThome鐵人賽
iThome鐵人賽