RNN 是 deep learning 中最簡單能有效訓練 NLP model 的架構。不過在 attention 機制和以他為主建立的 transformer 架構被提出以後,NLP 的各項任務在 state-of-the-art performance 都有了大躍進。讓我們來看看 attention 究竟是什麼魔術。
Seq2Seq 架構有兩個問題:一是整個 input 被 encode 成一個 context vector,但 input 的不同部分其實有不同程度的重要性,例如 how is your weekend 裡,weekend 肯定比 is 對於理解來得重要。二是在產生 output 時,不同 timestep 會跟不同部分的 input 有關,例如在翻譯時,output 前面大多時候跟 input 前面最有關。
Attention 機制就是在幫助 RNN 的 output 找到值得注意的地方,產生更相關的結果。
具體來說的作法很多,只要能達成目的都稱為 attention。這邊介紹 Bahdanau [4] 提供的一個框架:

—— Attention 機制。[5]
圖中的 Seq2Seq 是建立在 bidirectional LSTM 上,而上半部是 attention score 的計算。
在每個 decoding timestep 會對每個 input timestep 計算 attention score,並用它來計算 weighted output。大概分為幾步:
最後拿 decoder hidden state 和這個 context vector 一起進行預測,如此一來不同 decoder timestep 可以注意到 input 跟自己最相關的部分,並做出更適合的預測了。
在做 attention 的同時,其實也可以看成在做 alignment。也因此 translation model 加入 attention 再適合不過,因為 translation 本身也可以看作是在找 source text 跟 target text 的 alignment。同時 attention 很適合用來視覺化訓練的成果,從他計算的 score 就可以看出每一部分的對應是不是合理:

—— Attention 幫助視覺化 translation 結果。[6]
事實上 attention 機制不只適合用在 Seq2Seq 甚至 NLP 裡,他可以是很廣泛的應用,例如 computer vision 裡做 dog classification 可以注意圖片中哪部分是狗值得注意,或是做 image captioning 可以找出 caption 跟圖片的對應。
(Vaswani et al., 2017) Attention Is All You Need
Attention 其實還有一項能力。因為他會在 input 各個 timestep 計算 attention score,所以即使是很久以前的 input 也能有效利用,改善一般 RNN 對於久遠以前的 input 比較不能有效學習的問題。
那既然 attention 具備這些能力,那是不是其實根本不需要 RNN 我們也有另一種辦法處理時間序列?全部基於 attention 的架構 transformer 就這麼誕生了。
拔掉 RNN 最大的好處就是可以更有效運用 parallel computation。原因是 RNN 每一輪的計算都 depend on 前面的計算,所以不同 timestep 的運算沒辦法同時運行。有了 transformer 以後,他的架構更有利於 parallel computation,所以除了 model performance 之外也大大提升了運算速度。
接下來就來認識一下 transformer 吧。
他的架構對新手來說有點可怕,有很多陌生的名詞:

—— Transformer model architecture。
左半邊等同 Seq2Seq 的 encoder,右半是 decoder。灰色的 block 會重複 N 次,每個 block 的 output 是下個 block 的 input。
Encoder 和 decoder 的每個 block 包含這幾步:
每一步後都加 residual(Add)和 normalization(Norm)。
Residual 在前一篇有簡單介紹,就是那一根看起來像 shortcut 的。
我們先來理解 self-attention 是什麼,以及 positional encoding 又是什麼。
沒有 RNN 由前往後一一訪視序列的每個 timestep 找出他們之間的關係,要怎麼取得一個序列的 encoding 呢?
前面介紹到 Seq2Seq 中 attention 可以找出 output 和 input 的互動關係,而 self-attention 就是用類似手法但由 input 或 output 自己對自己找出互動關係,形成 encoding。

—— Attention visualization of self-attention。
圖中兩個序列都是同一個,每個 timestep 在做 self-attention 後會找出和其他 timestep 之間的重要性。
具體方法跟前面介紹的 attention 本質上相同,每個 timestep 找出和其他每一步的 attention score 作為 weight,並算出 weighted average 當作 input 在該 timestep 的 attention output。
那這些 attention 具體是怎麼做的呢?

—— Scaled dot-product attention。
計算 attention output 需要三種 input:Q (Query)、K (Key)、V (Value)。Q 是你要計算誰的 attention output,(K, V) 是 Q 對誰做 attention,K 是這個對象和 Q 計算 attention score 的元素,V 則是這個對象的原始值。
例如我們在做 Seq2Seq attention 計算 output A 在 time t 對 input B 的 attention output,那:
- Q = A 在 t 的 hidden state
- K = B 每個 timestep 的 hidden state
- V = B 每個 timestep 的 hidden state
因為我們會用 Q 和 K 計算 attention score 當作 weights,然後拿這些 weights 和 V 計算 weighted average 作為 attention output。
在 encoder 第一步和 decoder 第一步因為是計算 input 對自身的 self-attention,Q、K、V 都來自 input。
在 decoder 第二步則是計算 output 對 input 的 attention,所以 Q 來自 output、K 和 V 則是整個 input 的 embedding,也就是 encoder output。
理解 Q、K、V 後,回到圖中。先不要管 mask 的話,整體會等於:
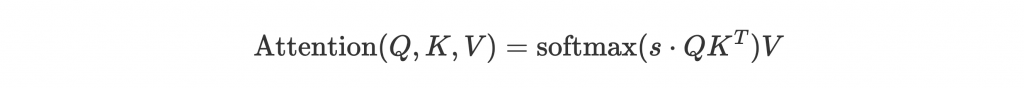
基本上等於前面介紹的 attention 步驟,只是 input 細分成 Q、K、V 罷了。s 是 scale,paper 中等於 ,
是 K 的 dimension。這麼做的原因是如果
太大,
可能會太大,softmax 後的值會被推往 gradient 小的地方,增加訓練難度,所以用 s 來避免
過大。
最後回到中間 optional 的 mask。因為在 decoder 第一步中,每個 timestep t 不需要跟後面的 timestep 做 self-attention,所以用 mask 來遮住 t 以後的 timestep。

—— Multi-head attention。
為了讓 self-attention 不只一種互動方法,我們一次學習更多種互動,這就是 multi-head。
同樣的 input 和步驟我們同時做 h 次,但每個 head 中 Q、K、V 都會先進入每個 head 專屬的 linear layer 、
、
,
,才能讓每個 head 訓練出不同的東西。
最後 concat 把所有 head 合起來,再透過一層 linear layer 讓 head 之間互動,得到最後的 attention output。
來看一下 multi-head 的效果:

—— Multi-head attention visualization。
綠跟紅是不同的兩個 head,可以看出他們在學習不一樣的關係。
介紹完 attention,有沒有感覺少了什麼東西?咦,如果在 self-attention 只是計算每個字和句中其他字的關係,好像這些字怎麼打散都會學到一樣的東西?
沒錯,因為 transformer 不像 RNN 照順序,而是同時對每個字 encode,我們需要先把每個字的 position 資訊嵌入序列中。Positional encoding 就是在做這件事。
做法很多,基本上就是一個數學函式,input 是 position,output 是 vector,可以和原本的 embedding 相加。有興趣可以參考 paper。
結果大概是這樣:

—— Positional encoding output。[3]
每一 row 是 position i 的 output vector,大小為 embedding size。可以看出不同 position 會有該位置的特徵。
終於介紹完了。Transformer 新東西和細節很多,但理解每一步後回去看大架構重新順過一遍流程,就能比較熟悉了。
最後來看看他在 machine translation 的 performance。
BLEU score 方面,在 English-French translation 中再次以 41.8 打破了之前 state-of-the-art performance 41.29。同時 training cost 方面,減少了大約每秒 100~1000 倍的計算量。
還記得兩天前介紹的中文文本生成 project 嗎?剛好我們直接用它的架構,換掉 RNN 試試看 transformer 會帶來什麼結果。這邊的 code 大部分參考 PyTorch tutorial。
因為是做 text generation,整個 model 會和上面介紹的 machine translation 不同。Machine translation 需要整個 input 的 embedding 預測一整句 output,但 text generation 每句 input 只需要預測一個字。
具體來說 model 裡 LSTM 改成 TransformerEncoder,因為只需要一個 output 就沒有 transformer decoder 的部分。除此之外,encoder 的 input 每一句假設長度為 seq_len,還可以切成 seq_len 個子句,一次訓練多一點。最後出來的 encoder output 接 fully-connected layer 預測下一個字。
import math
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self, n_vocab, embedding_dim, hidden_dim, nhead=8, num_layers=6, dropout=0.2):
super(Net, self).__init__()
self.src_mask = None
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(n_vocab, embedding_dim)
self.pos_encoder = PositionalEncoding(embedding_dim)
encoder_layers = nn.TransformerEncoderLayer(embedding_dim, nhead, dim_feedforward=hidden_dim, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers)
self.hidden2out = nn.Linear(embedding_dim, n_vocab)
def _generate_square_subsequent_mask(self, sz):
# Each row i in mask will have column [0, i] set to 1, [i+1, sz) set to -inf
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def forward(self, src):
src = src.t()
# For each input subsequence, create a mask to mask out future sequences
if self.src_mask is None or self.src_mask.size(0) != len(src):
mask = self._generate_square_subsequent_mask(len(src))
self.src_mask = mask
embeddings = self.embeddings(src) # seq_len x batch_size x embed_dim
x = self.pos_encoder(embeddings)
out = self.transformer_encoder(x, self.src_mask)
out = self.hidden2out(out)
return out
PositionEncoding 是自己定義的,直接拿了 PyTorch tutorial 裡的用。
這邊用了 mask 將長度 seq_len 的 input 切成 seq_len 個子句,大概長這樣:[1], [1, 2], [1, 2, 3], ..., [1, ..., seq_len]。也就是 mask 會是一個 seq_len x seq_len 的 matrix,左下三角形是 $1$ 代表選取,右上三角形是 。假設
seq_len = 4,那 mask 就是:
[1, −∞, −∞, −∞]
[1, 1, −∞, −∞]
[1, 1, 1, −∞]
[1, 1, 1, 1]
我們試著 train 120 epochs,得到 training loss:

—— Average training loss over epochs。
Test loss 是 4.88。
來稍微看一下生成:
是一个农业化解放,而不可以翻较的因为吴全部联系。
从旧农民取公了阑尾地的繁主生物和扎、社会主义国胜利、
农民主义和反团结,是在社会主义国发展下的就是革命时间,
使自我们在的战胜利将革命战争。反对于革命过穷性,
一个问题而且也是一个阶级机关的实践。如果你有一切反动派,
要这样的时候曾经过大多对了团结。他们实际做得闻,
再很多么做了,帮助他们总停止可以周武器。
,我们。君子不如自己头躬身使自己的办法去做奴隶呢?
君子是耻;不正确的政的儿子不会去了解一点,我们所谓旧缺点才能力。
自大的书记住在社会中,逐中的功许多数量环境内和睦靠着群众前进境。
何一个被平前途,就很少了维起来的成了划明,反映境又有仁德的人最能力的力量。
党的人请教条件一面,不但坚决不能奏全部分配问题,民才合作社会主义一切实质,
实行政治工作调查,两个两个大官和政务,还不能劝谏和一般地懂得到这种。
一个农大概只有这样做一些地奋情形公允地同了建立于,达到群众讲明不更,
睡和欺诈不管一个农业中去作了。课并且使这是过去起这样的一个工作。
这样的人,谨慎地回去他的人好,说明智慧的颜回做了。他做,但他开了,你就不能够了。
乍看之下和 LSTM 的版本差不多。成功捕捉一些經典詞:"社會主義"、"反動"、"君子"、"仁德",也有些合文法的句子:"自大的書記住在社會中"、"實行政治工作調查",甚至也有很多荒謬的句子:"反對於革命過窮性"、"君子是耻"等等。
但值得一提的是訓練非常非常快速。LSTM 達到這樣的效果訓練了 30 epochs 花費將近六小時,但 transformer 只花了 26 分鐘就訓練了 120 epochs。Parameters 數量 transformer 大概是 3/2 倍,不過如果有心調校讓他們大小差不多也訓練到差不多程度,時間上的差距還是顯而易見。
其他沒放上來的部分,有興趣可以直接看 GitHub:pyliaorachel/knock-knock-deep-learning。
捨棄 RNN 靠著 attention 建立起的 transformer,不只 performance 更勝以往,還能藉著 parallel computation 大幅減少訓練時間,也因此近幾年的 model 大部分都移往了 transformer。
Google 再次貼心的提供了 Transformer 的原始碼,有興趣或有疑問都可以參考。


 iThome鐵人賽
iThome鐵人賽