昨天講到關於RMI的架構,今天會詳細地介紹關於RMI是如何執行與分配資料,搭配公式來解說,讓大家更深入地瞭解~~
題外話 - 大概等到本篇論文講到一個段落,才會開始實作喔><
抱歉各位,一堆屁話,請多多包涵 !
: 代表 Model 輸入的 key 值為 x。
: 表示position,範圍[0,N)。
: 代表層數,第
層。
: 代表第
層總共的Model數量。
: 表示第幾個Model。
舉例: 就表示第
層的第k個Model
上方的公式為RMI的重點,不斷地執行上面的公式,直到選擇至最後一層的Model,最後預測出位置。
迭代地訓練每層的每個Model,以平方差來計算平均誤差。
嗯嗯嗯...很像就這樣講完了XD
等等..那資料是如何分配至下一層的呢??
我們繼續看下去 ~
我們來放大看看執行RMI的公式~燈燈燈燈燈 ! (從口袋拿出放大燈)
放大燈 !!!
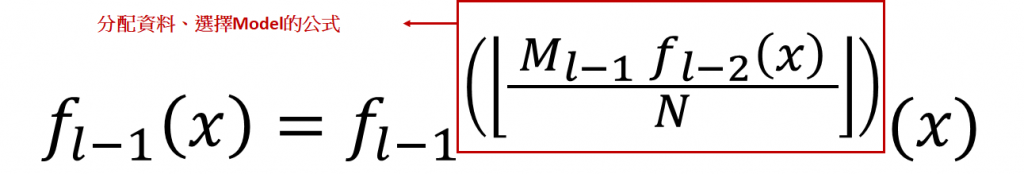
紅框就是分配資料的公式,Model訓練完後,依據其 預測的位置 除以所有的資料數量 ,在乘以 下一層的Model總數 ,來分配給下一層的Model。
這個公式的想法就是: Key值根據Model預測出的位置分布,決定被分配至下一層的哪一個Model
Ex: 當Key值被預測出的位置比較後面,那就由較後面的Model來負責訓練。
我的表達很像真的很爛...但我盡力了XD
簡單來說,RMI架構的設計,是為了使大量的Keys依據迭代的Model訓練並將分布相較集中的Key值聚集在一起,由不同Model訓練預測。
想一想~
方法一、使用單一個Model訓練所有的資料並預測
方法二、使用RMI架構,將資料分配至好幾堆,分別由不同的Model訓練
方法二當然比較好呀,因為方法二就是為了彌補方法一的缺陷所設計的麻 XD


