混和式索引...?
沒錯 ! 太炫了ㄅ XD
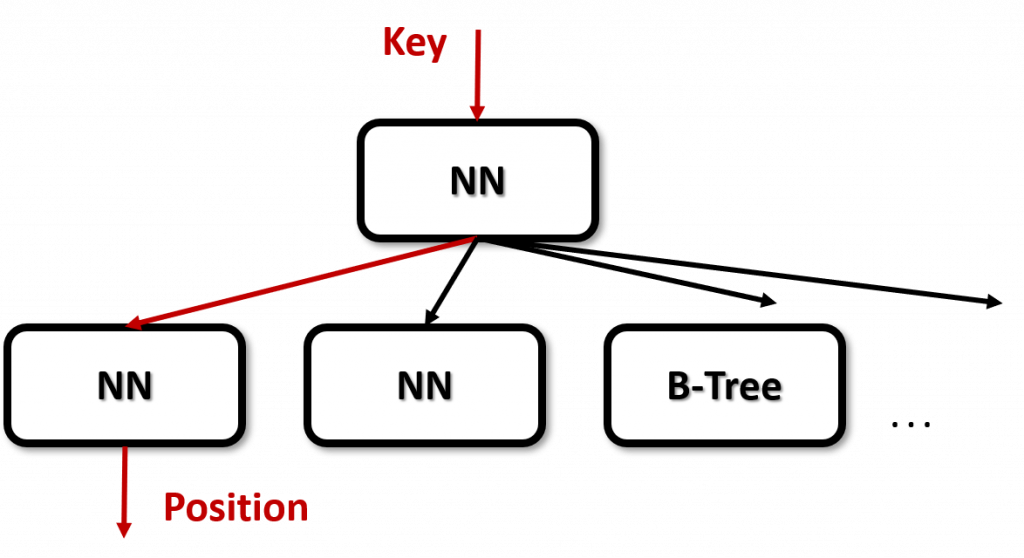
Hybrid Indexes主要是延伸自RMI,由不同的Models組合而成。
在最上層的Model使用簡單的深度神經網絡是最好的選擇,學習大量、複雜分布的資料型態。
最下層的Model則是使用簡單的線性回歸最適合,減少過多的空間、執行時間。
甚至對於最下層的Model相較難以學習的資料分布,可以改成B-Trees。
本篇paper只專注於兩種型態的模型:
0~2 層全連接層的簡單神經網絡(每層神經元數量 <= 32) + ReLU激勵函數
B-Trees
在訓練前,我們必須先定義好整索引架構,總共幾層,每層的Models。
Hybrid Indexes 訓練演算法如下:
這裡解釋一下,如何計算Model的誤差,可以回顧一下 【Day 7 - 不精準的問題】
在這裡我們會計算出 Model 的 absolute min-/max- error,如果絕對值的最大誤差 > 預設的閾值,該Model就切換成B-Tree。
Hybrid的整體架構圖會像下方這張圖: