AWS Data Pipeline 是一種 Web 服務,可協助您以指定的間隔,可靠地在不同 AWS 運算與儲存服務以及內部部署資料來源之間處理和移動資料。使用 AWS Data Pipeline,您可以時常從資料的存放處直接存取、大規模轉換和處理這些資料,並將結果有效率地傳輸到 Amazon S3、Amazon RDS、Amazon DynamoDB 和 Amazon EMR 等 AWS 服務。
AWS Data Pipeline 可協助您輕鬆地建立容錯、可重複且高可用性的複雜資料處理工作負載。您不用擔心如何確保資源可用性、管理內部任務相依性、發生暫時性故障或逾時問題時重試個別任務,或建立故障通知系統等事項。AWS Data Pipeline 還可讓您移動和處理之前在內部部署獨立資料區塊中鎖定的資料。
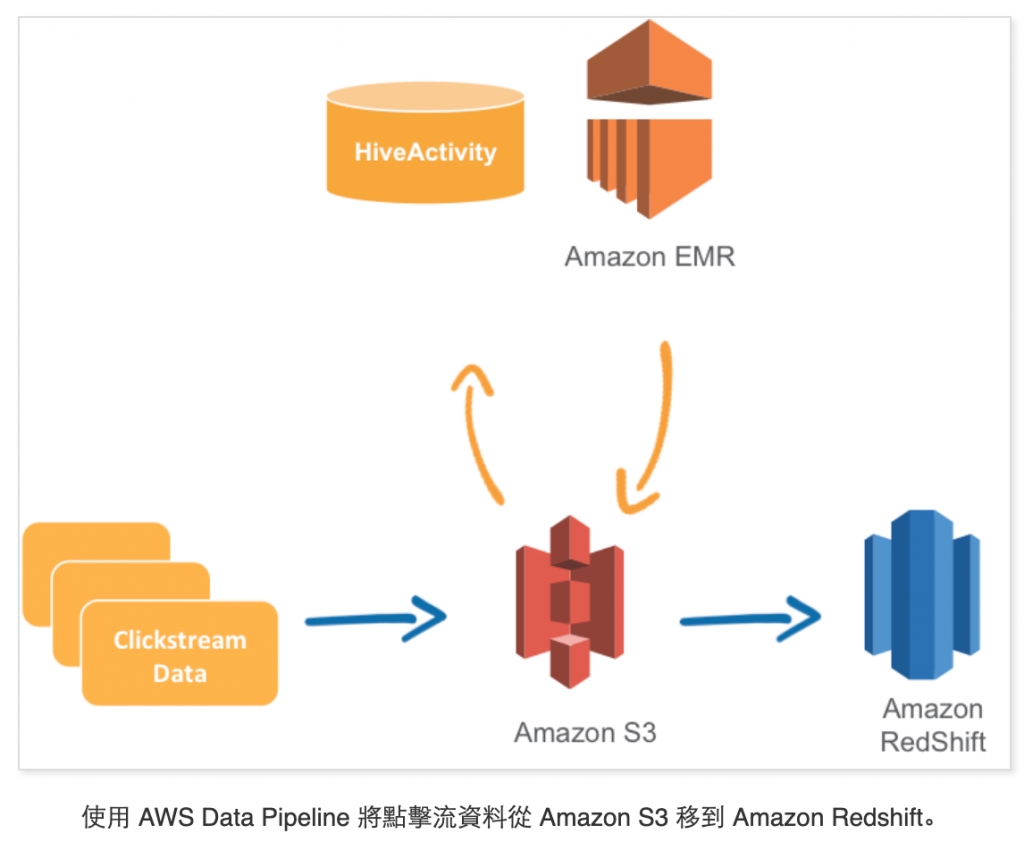
您也可以定義先決條件,檢查資料是否可用,再啟動特定活動。在上述範例中,您可以在 S3DataNode 設定先決條件,檢查日誌檔是否可用,再啟動 HiveActivity。
AWS Data Pipeline 處理:

