第一步 Data 收集數據:Clean / Prepare / Manipulate Data
第二步 Features 找出關鍵特徵
第二步 Training 訓練並驗證,找出最佳結果
例如
在現有手中的資料Data中,找X / Y對應
若應⽤於辨識動物, 我們期待
輸入X:  就會知道輸出(辨識)時 f(X) = 貓的圖片(Y)
就會知道輸出(辨識)時 f(X) = 貓的圖片(Y)
若應⽤於語⾳辨識, 我們期待
輸入X: 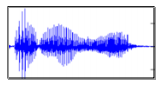 就會知道輸出(辨識)時f(X) = ⼤家好 (Y)
就會知道輸出(辨識)時f(X) = ⼤家好 (Y)
可應⽤於預測明天天氣如何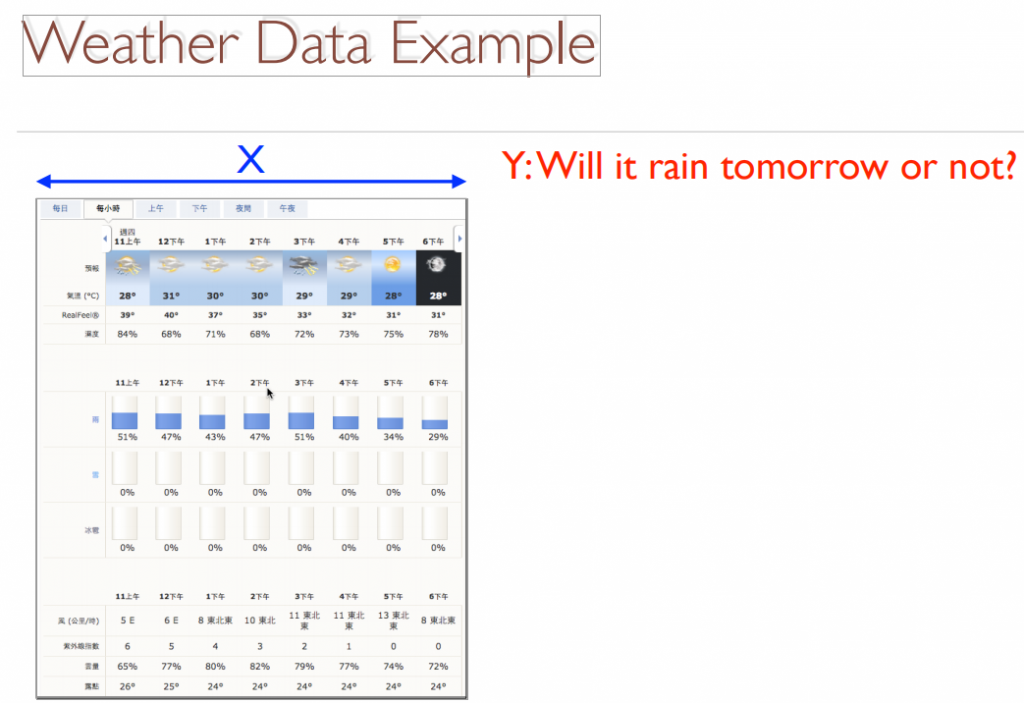
可應⽤於辨識交通工具
可應⽤於辨識spam mail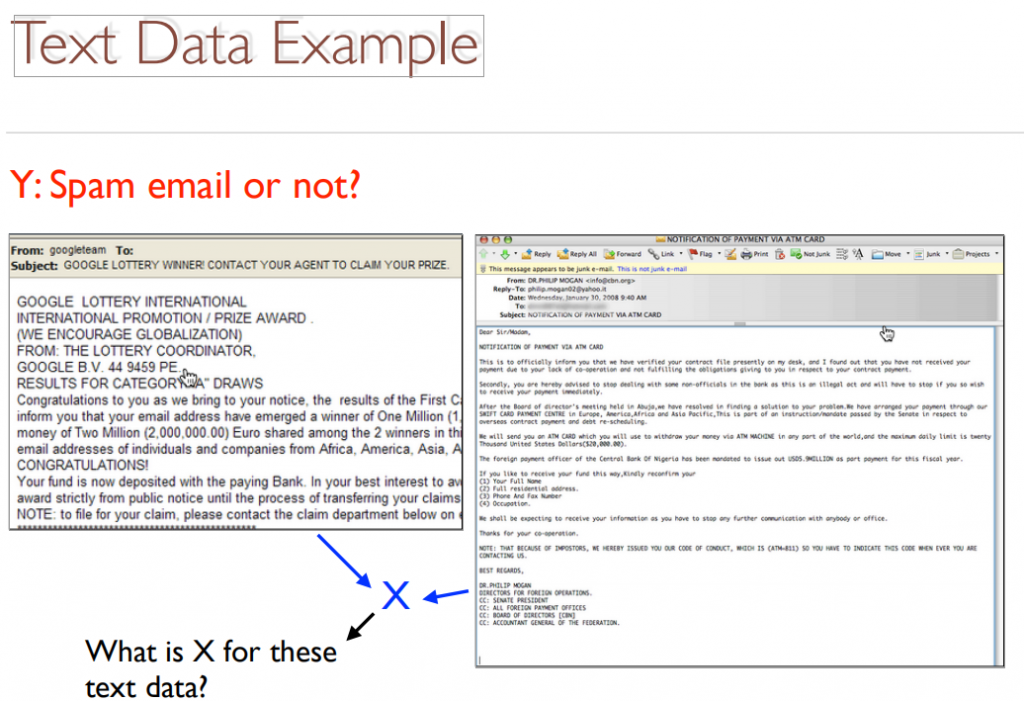
收集數據是一件不容易卻是關鍵的第一件事情,很不幸的,收集數據是一件很浪費時間的事情,有時候收集數據也是一件反反覆覆的事情,收集不好可能需要再從來,因為
所以收集數據的"人"或稱"專家"(domain know-how)很重要,必須對目的很了解,知道哪邊可以收集數據,能夠整理成乾淨的數據,給下一步順利地進行,否則容易失敗,預測錯誤,甚至有時候必須要再回來收集數據,重頭再來一次。

