需要配置一台電腦來處理接下來所有的服務,因為這是深度學習的應用,所以需要使用到 GPU,而 GPU 的配置十分繁瑣,而透過 AWS EC2 來配置的話,只要選擇好對應的個體類型與 AMI (Amazon Machine Image),可以很快的完成主機的配置。關於 EC2 的詳細操作,可參考先前的Amazon Elastic Compute Cloud (EC2),在這裡只簡單的把畫面擷取下來。
首先要確認隨選的個體(instance)是否有足夠的數量可供使用,因為通常一些比較特別的個體類型,預設未必會提供,需要向 Support Center 發出請求案例 (case),才可以得到可配置的數量,下圖為新加坡地區 EC2 控制台的操作畫面,點擊左邊功能導覽列的限制,就會在右手邊出現所有 AWS 的限制,輸入 instance 進行過濾,就可以得到所有個體的相關限制,我們可以看到隨需 G instance 的限制為 768 vCPU。
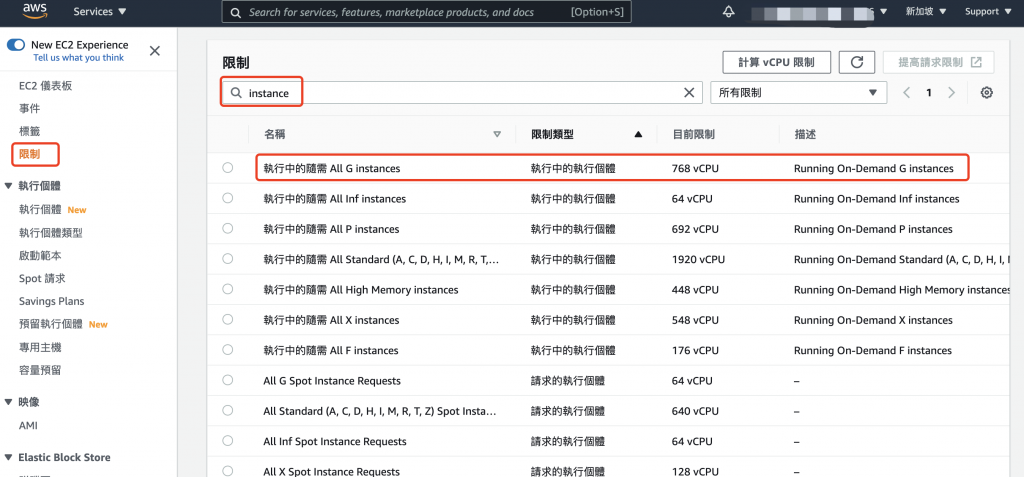
圖 1、檢視 EC2 中個體的限制
接下來就可以開始配置一台擁有 GPU 的 EC2,點擊左邊功能導覽列的執行個體,接著在主畫面中點擊啟動執行個體,進入 Step 1: Choose an Amazon Machine Image (AMI),在搜索文字方塊中輸入 deep learning ,進行過濾。會出現很多符合這個關鍵字的 AMI,拉到畫面最下方點擊 143 results in AWS Marketplace 如下圖所示,因為客製化的 AMI 很多是要另外收費的,也就是你用ami要收費,運行ami的個體也要收費,使用 AWS 自己設計的 AMI 通常是不收費的,不過,重點是透過這個步驟你可以看到這個ami的詳細介紹。
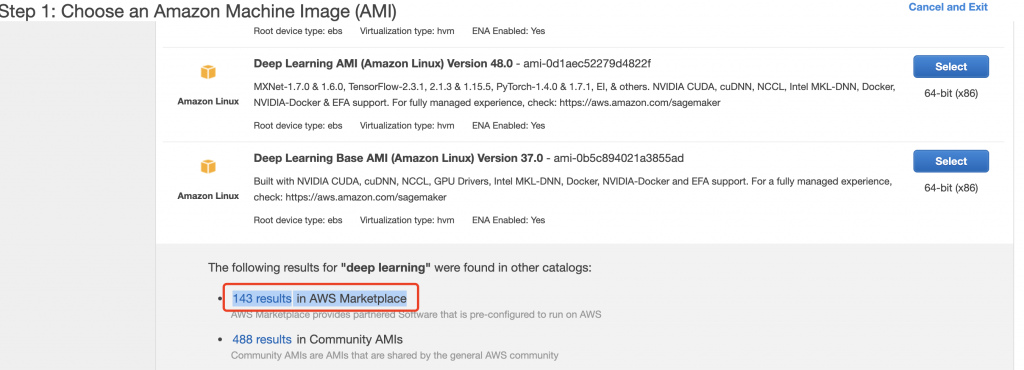
圖 2、檢視在 AWS 市集中符合 deep learning 的 AMI
在下圖中可以看到這個 AMI 所安裝的作業系統- Amazon Linux 2,已經安裝的深度學習套件-TensorFlow, MXNet, PyTorch, and tools like TensorBoard, TensorFlow Serving, and Multi Model Server.跟相關的gpu套件-NVIDIA CUDA, cuDNN, and Intel MKL-DNN。點擊最下方的AWS Deep Learning AMI (Amazon Linux 2) product detail page on AWS Marketplace可以看到整個 ami 的詳細介紹以及如何在這個 ami 下進行操作。
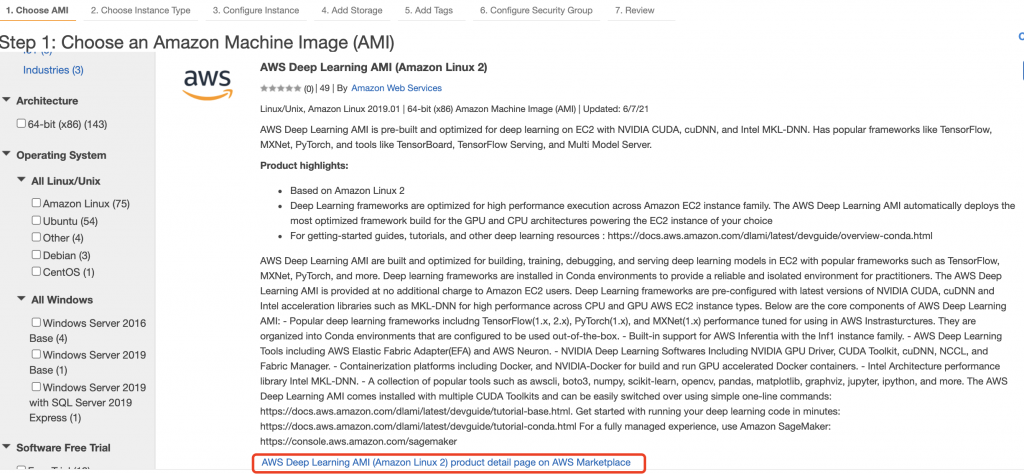
圖 3、檢視在 AWS Deep Learning AMI 的内容
下圖為 AWS Deep Learning AMI (Amazon Linux 2) 這個鏡像的定價畫面,通常鏡像供應商(Vendor)會提出一個建議的個體,以這個鏡像而言,它推薦的是 p3.2xlarge 這個個體類型,但在新加坡地區的定價是每小時 4.234 美元,在考量成本的情況下,選擇 g4dn.2xlarge ,每小時 1.052 美元。
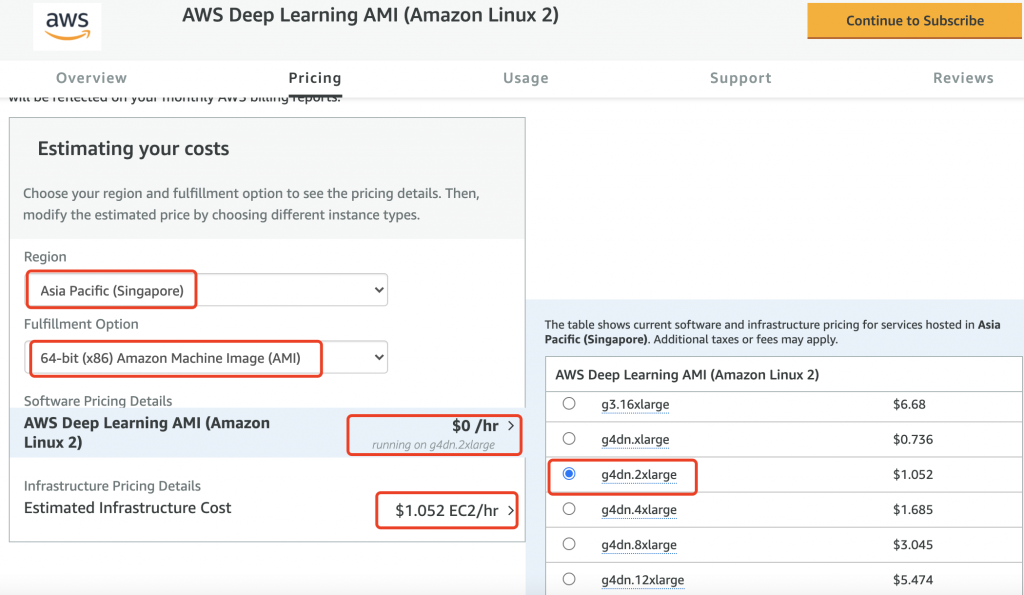
圖 4、計算符合需求的最佳的定價
G4dn 執行個體旨在協助加速機器學習推論和圖形密集型工作負載,具有以下特色:
而 g4dn.2xlarge 這個個體的規格是 1 GPU,8 vCPU,32 (GB)記憶體,16 (GB)GPU 記憶體,225執行個體儲存體 (GB)。
接下來的配置如下:
Choose AMI: AWS Deep Learning AMI (Amazon Linux 2) version:49 (64-bit x86)
Choose Instance Type: g4dn.2xlarge
Configure Instance:
Add Storage: 200 因為預設已經安裝很多套件,所以建議改為 200G 比較夠用。
Add Tags: 可加可不加,通常是用在Cloud watch觀察比較方便,我們先不加。
Configure Security Group: 為提供安全保障,限制進來的連線,因為我們是建置 Web 伺服器,所以打開埠號 22 與 80 。
Review: 看一下前述的所有設定,確定無誤後就直接按下 Launch
Key pair 設定: 因為安全考量,AWS要求使用者務必要用密鑰對( key pair )的方式來進行連線,因此在啟動 EC2 前會要求建立或選擇密鑰對,下載下來的密鑰對鑰一定要好好保存,遺失後是沒辦法再重新下載的。
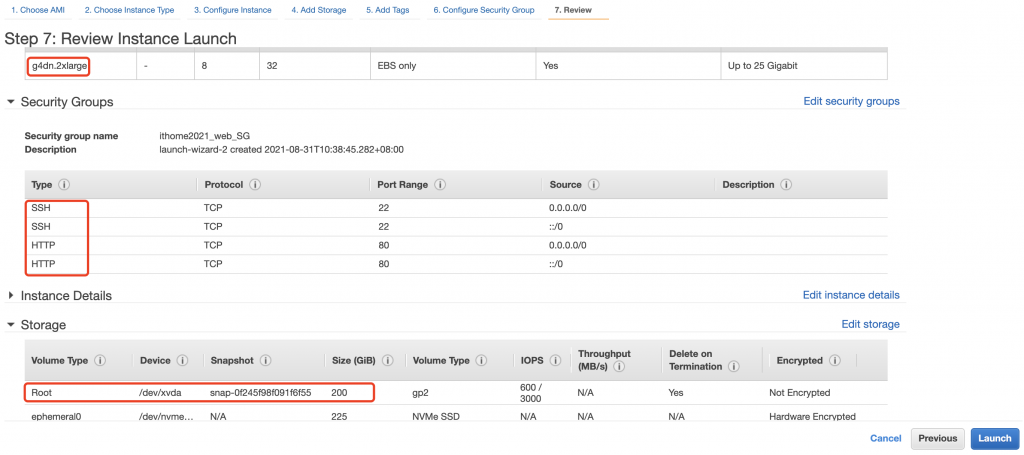
圖 5、AWS EC2 配置檢視
參考資料
老師我看到這裡有需要用到 GPU 的資源...
我能請教說老師沒有考慮用 Google Colab 或是 Kaggle 去執行嗎?
還是因為這個是互動式,所以才需要架一個 API Server 去儲存結果的嗎?((我猜
如果效能差一點點,應該就多等一點點時間而已,對嗎?
主要是這個專案是在做全端式的整合,而非只是辨識模型的訓練,所以要考慮如何接收要辨識的圖片,如何傳要辨識的圖片,辨識模型只是其中一個元件而已,你可以在任何地方進行模型訓練,但最終還是得找一個地方部署,供他人用最簡單的方式使用。
是,我後面看完就知道為什麼要全端啦,謝謝老師!

