在 Day 15 - 說明 YOLO 相關設定 以及 Day 16 - 進行影像辨識訓練完成了 YOLO 自訂資料集的訓練,在 Day 34 - 實作 S3 驅動 Lambda 函數進行 Yolo 物件辨識 與 Day 36 - 使用 Container 建立 Amazon SageMaker 端點 分別用不同的方法來進行 YOLO 推估的任務。
彼此之間的關係如下圖所示,使用者透過 API Gateway 上傳 (PUT) 圖片到 儲存貯體 A,這個事件會驅動 AWS Lambda 函數,此時,AWS Lambda 函數 會根據事先訓練好的 YOLO 模型,對於該圖片進行 YOLO 推估 (Inference),接著以 IAM 角色 B 的身分,將偵測到物件畫出方塊框後,存到 儲存貯體 B,而使用者就可以看到處理後的結果。
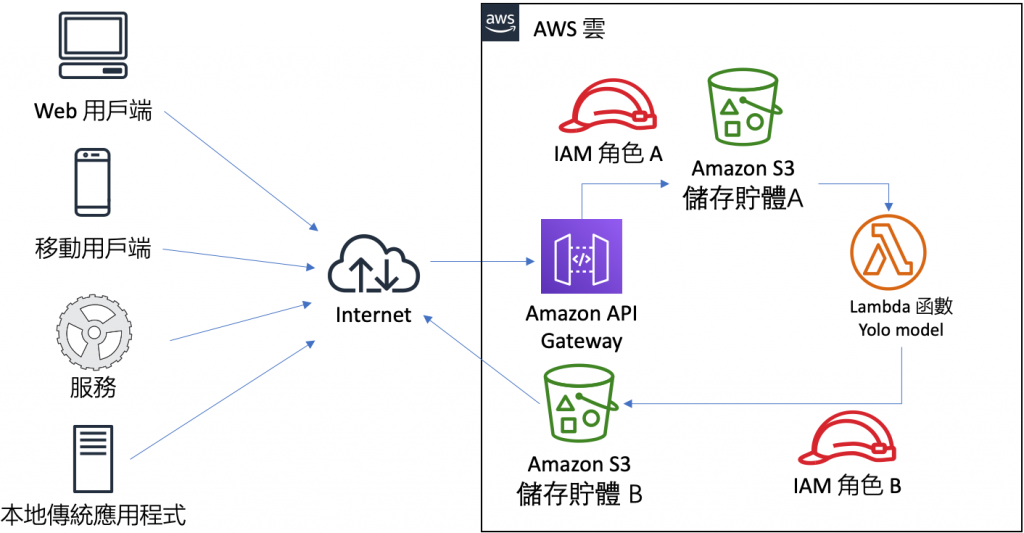
圖 1、S3 驅動 Lambda 函數進行 YOLO 辨識架構圖
Simple Inference Scripts for YOLO with OpenCV 這份專案中提供了一個使用 OpenCV 來進行 YOLO 推論的案例,現在我們就試著將這個案例佈署到 AWS Lambda 進行測試,需要的前期準備工作如下:
步驟 1. 上傳 YOLO 相關檔案到 S3
因為 AWS Lambda 函數的大小限制為 256 MB,所以需要把 YOLO 的權重檔 (yolov3.backup) 以及待推論的圖片 (02-frame-608x608-0090.jpg) 存到 S3 中,如下圖所示。
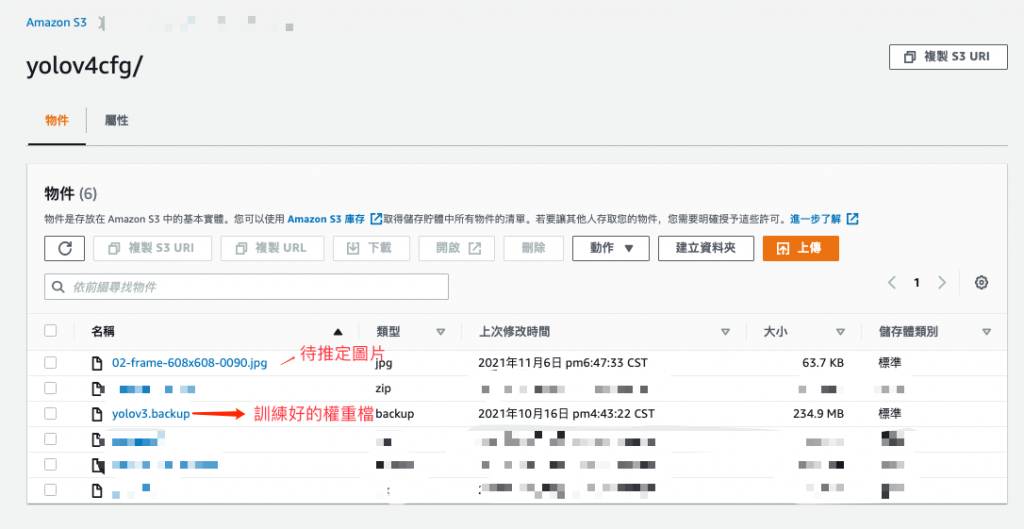
圖 2、上傳 YOLO 相關檔案到 S3
步驟 2. 建立 IAM 角色
建立一個 IAM 角色,允許執行 AWS Lambda,並有存取 S3 的許可。進入 IAM 管理控制台,選擇新增角色,接下來如下圖所示,選擇 Lambda 的使用案例後點擊 下一個:許可 按鈕。
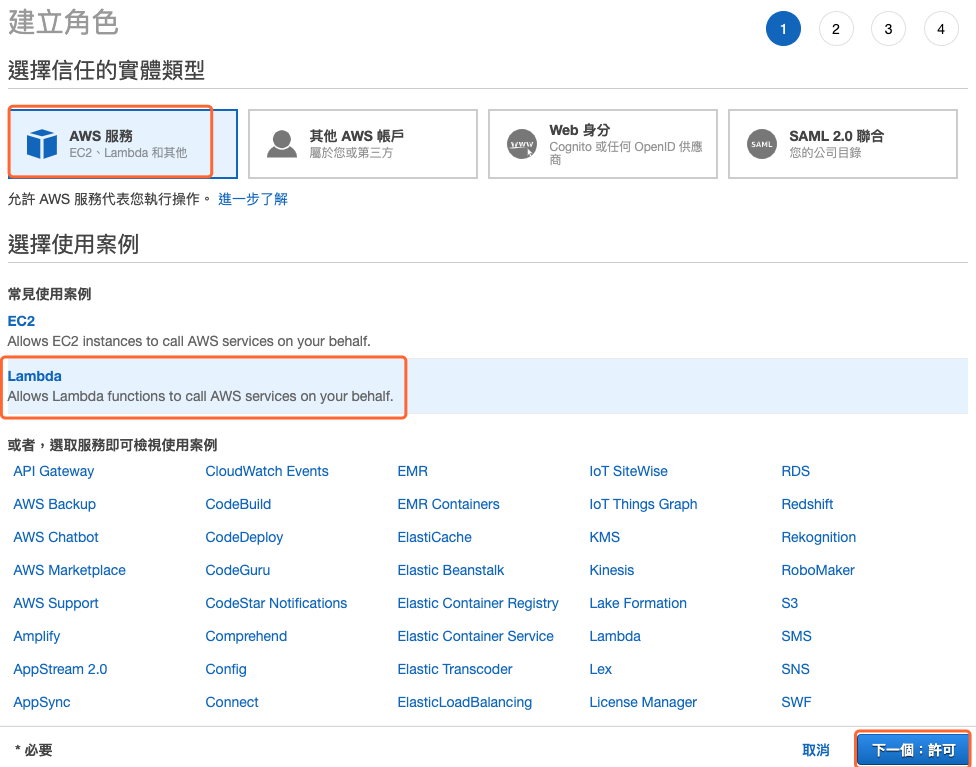
圖 3、建立一個角色選擇 Lambda 的使用案例
在搜尋文字框中輸入 basic 找到 AWSLambdaBasicExecutionRole 進行連接,這將允許這個角色有寫入 CloudWatch 記錄檔的全縣,方便程式除錯之用,如下圖所示。
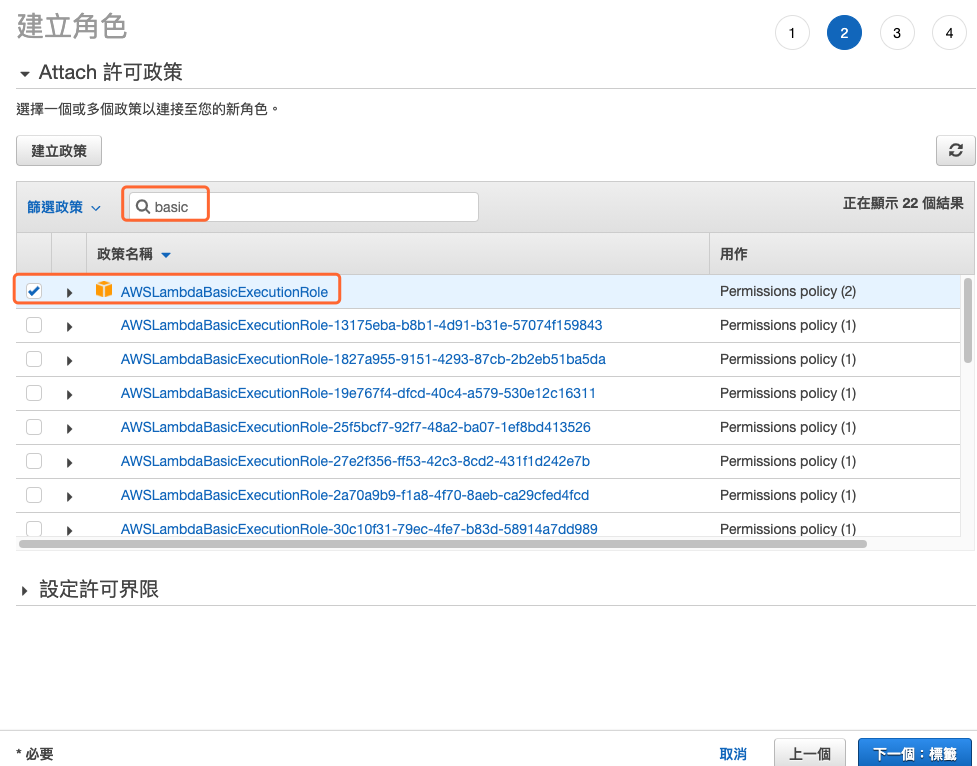
圖 4、連接基礎的 CloudWatch 除錯用的許可政策
最後確定先前的設定後並輸入角色名稱後,就可以建立角色,如下圖所示。
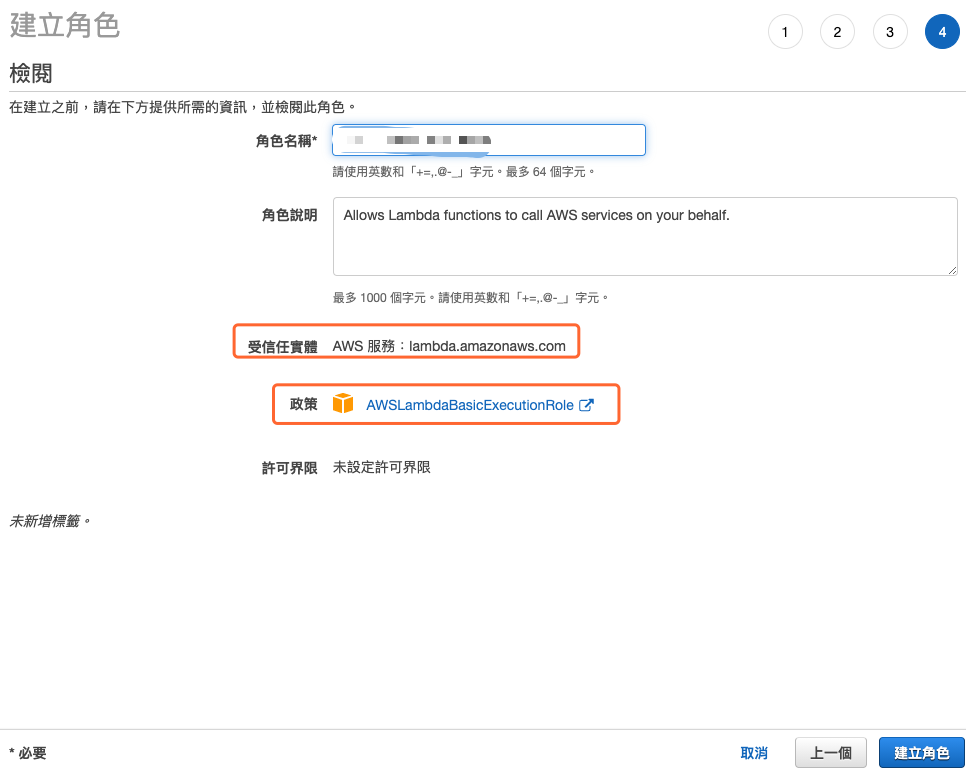
圖 5、檢閱設定並建立角色
編輯一個新的政策,內容如下圖所示,給定讀取 (GetObject) 儲存貯體 A 與寫入物件 (PutObject) 與權限 (PutObjectAcl) 到儲存貯體 B。
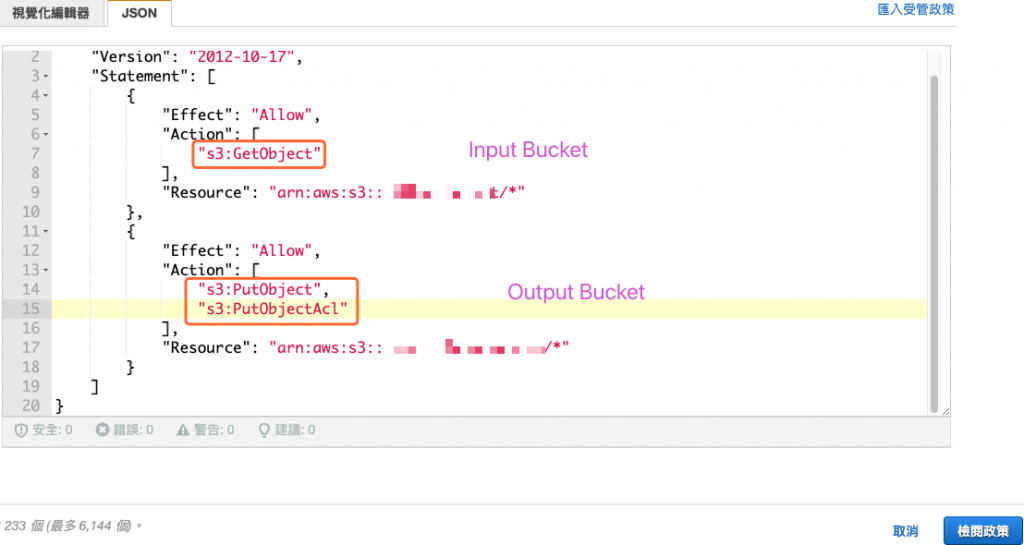
圖 6、新增政策
接著到角色設定畫面,將新建政策連接到角色上,如下圖所示。
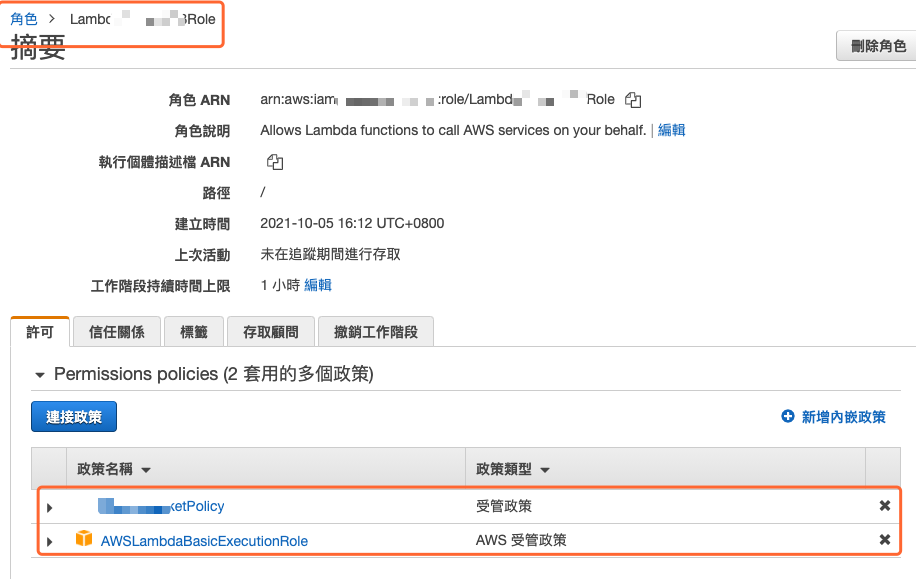
圖 7、將新增的政策連接到先前的角色
步驟 3. 建立 AWS Lambda 函數
進入 AWS Lambda 管理控制台,選擇建立 Lambda 函數,設定內容如下圖所示。比較需要注意的是執行時間務必選擇 Python 3.7,因為要使用 OpenCV 函式庫層,而執行角色要也要記得選擇上一個步驟設定的角色。
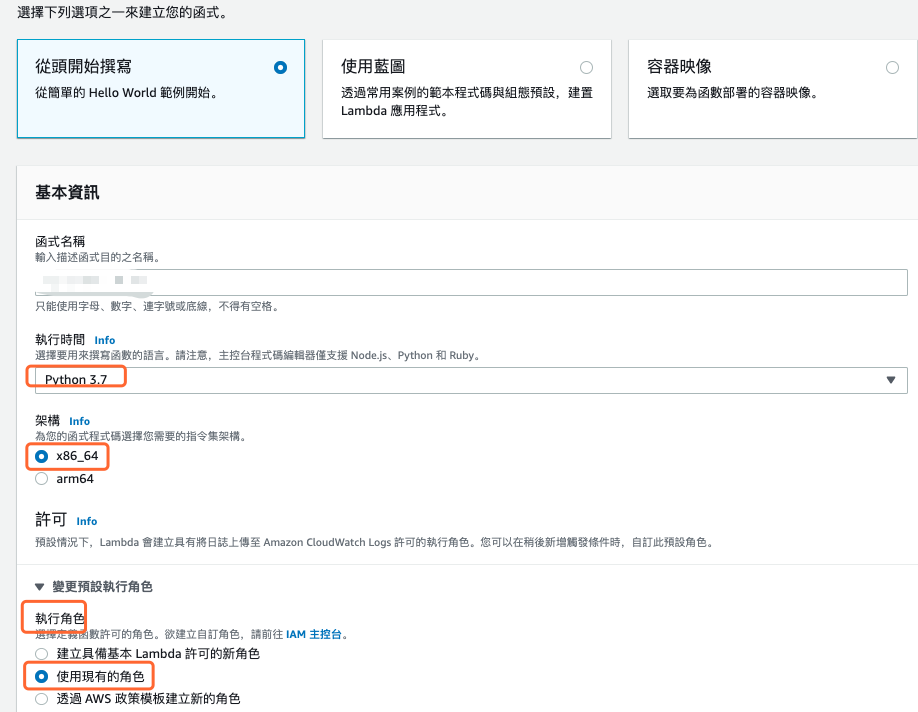
圖 8、建立 Lambda 函數設定畫面
在 Lambda 函數中點擊 組態 頁籤,接著點擊 環境變量,新增三個環境變量,如下所示:
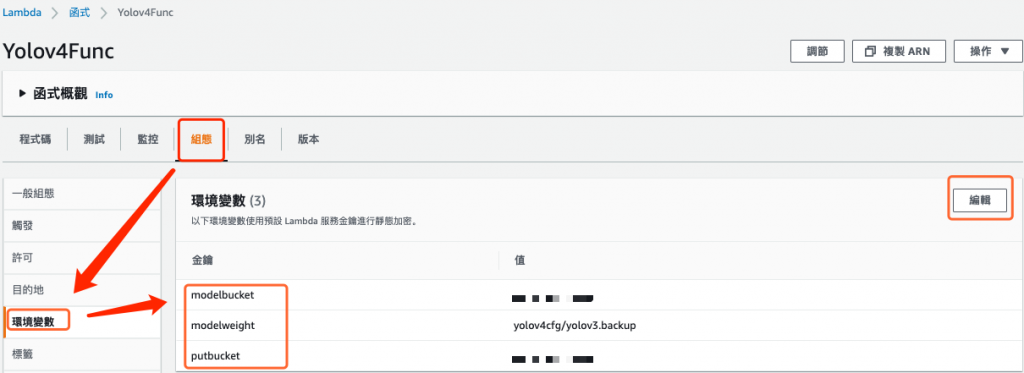
圖 9、新增 Lambda 函數組態中的環境變量
步驟 4.在 AWS Lambda 建立 OpenCV 層
建立 Lambda 函數後,選擇進入 AWS Lambda 函數的設定畫面,在畫面的最底端,為本函數 新建 Layer,如下圖所示。
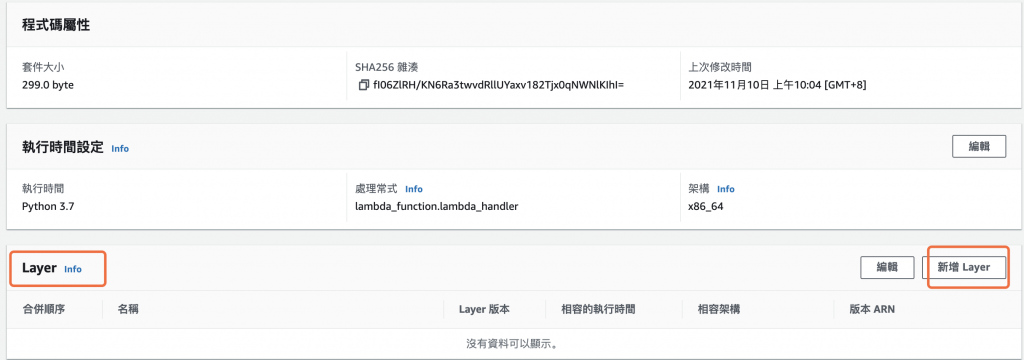
圖 10、為 Lambda 函數新增 Layer
進入新增 Layer 畫面後,選擇層來源為 自訂 Layer,接著選擇先前建立的 opencv45 函式庫層,如下圖所示。
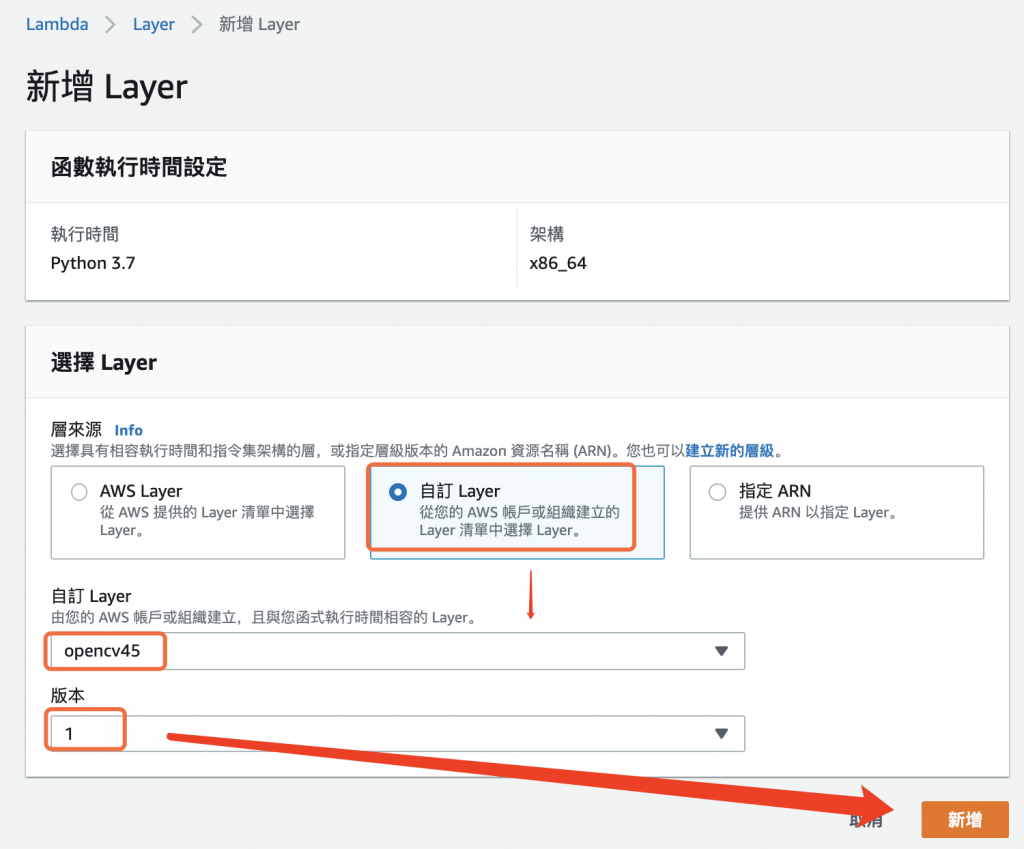
圖 11、選擇 opencv45 函式庫層
步驟 5. 撰寫 AWS Lambda 函數並完成測試
需要先建立一個目錄 cfg,在目錄內新增一個檔案 yolov3.cfg ,這個檔案的內容可以參考 Day 15 - 說明 YOLO 相關設定,而主要的推論程式為 service.py,內容如下
service.py
from __future__ import print_function
import urllib.request
import os
import subprocess
import boto3
import time
import cv2
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
LIB_DIR = os.path.join(SCRIPT_DIR, 'lib')
s3_client = boto3.client('s3')
modelbucket = os.environ['modelbucket']
modelweight = os.environ['modelweight']
modelcfg = 'cfg/yolov3.cfg'
# 從 s3 下載檔案
def downloadFromS3(strBucket,strKey,strFile):
s3_client.download_file(strBucket, strKey, strFile)
strWeightFile = '/tmp/' + modelweight.replace('/', '')
downloadFromS3(modelbucket,modelweight,strWeightFile)
print(strWeightFile)
# 繪製物件方塊框
def draw_image(image_path, output_path, pridicts):
cv2image = cv2.imread(image_path)
for k in range(len(pridicts[0])):
x, y, w, h = pridicts[2][k]
cv2.putText(cv2image, "{:.4f}".format(pridicts[1][k][0]), (x, y-6), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 1, cv2.LINE_AA)
cv2.rectangle(cv2image, (int(x),int(y)), (int(x+w),int(y+w)), (0,255,0), 2)
cv2.imwrite(output_path, cv2image)
# yolo 推論函數
def yolo_infer(weight, cfg, pic):
frame = cv2.imread(pic)
model = cv2.dnn.readNet(weight,cfg)
net = cv2.dnn_DetectionModel(model)
net.setInputSize(608, 608)
net.setInputScale(1.0 / 255)
net.setInputSwapRB(True)
classes, confidences, boxes = net.detect(frame, confThreshold=0.1, nmsThreshold=0.4)
return classes,confidences,boxes
# lambda 程式進入口
def handler(event, context):
for record in event['Records']:
inputbucket = record['s3']['bucket']['name']
outputbucket = os.environ['putbucket']
key = record['s3']['object']['key']
imgfilepath = '/tmp/inputimage.jpg'
downloadFromS3(inputbucket,key,imgfilepath)
prev_time = time.time()
result = yolo_infer(strWeightFile, modelcfg, imgfilepath)
print('predicting time: ' , (time.time() - prev_time))
tmpkey = key.replace('/', '')
upload_path = '/tmp/process-{}'.format(tmpkey)
draw_image(imgfilepath, upload_path, result)
s3_client.upload_file(upload_path, outputbucket, key,ExtraArgs={'ACL': 'public-read','ContentType':'image/jpeg'})
return 0
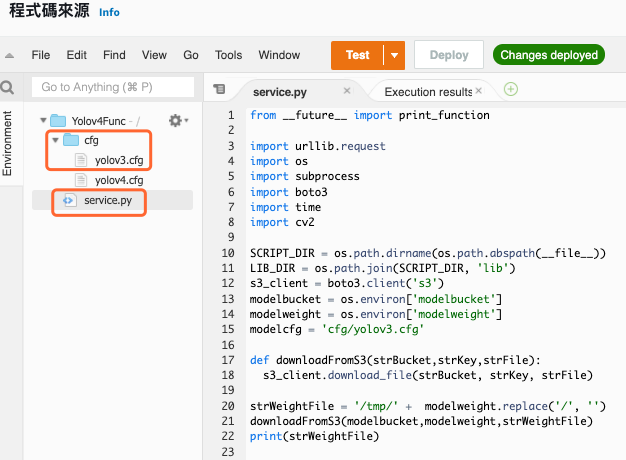
圖 12、AWS Lambda 程式碼
建立新測試事件,事件範本選擇 hello-world,事件名稱輸入 fromS3Bucket,內容所下圖所示,這是用來模擬當 S3 觸發 Lambda 函數後所傳過來的參數內容,記得將 [INPUT_BUCKET] 改成實際的輸入儲存貯體名稱,而[INPUT_OBJECT]要確保有這個檔案。
{
"Records": [
{
"s3": {
"bucket": {
"name": "[INPUT_BUCKET]",
"arn": "arn:aws:s3:::[INPUT_BUCKET]"
},
"object": {
"key": "[INPUT_OBJECT]"
}
}
}
]
}
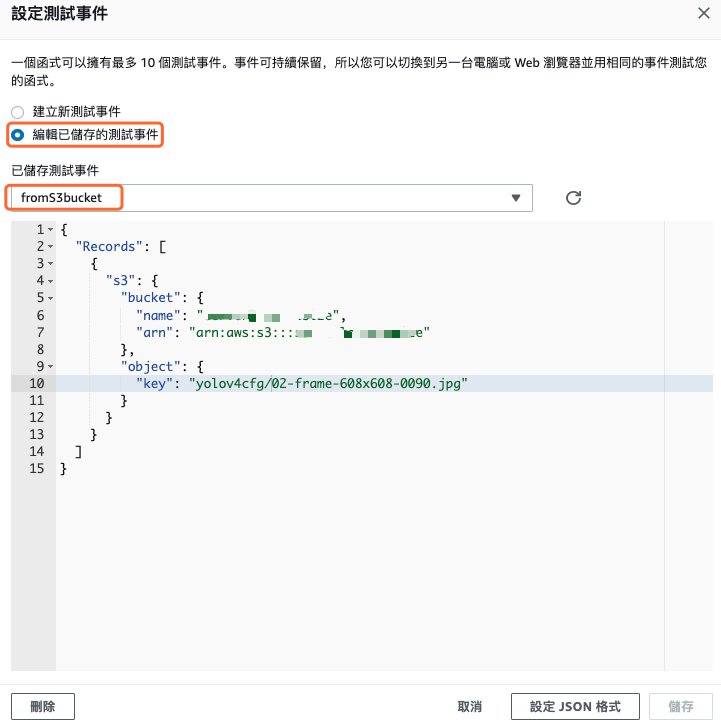
圖 13、設定 Lambda 函數測試事件
拉到畫面下方,修改 執行時間設定,將 處理常式 指定為 service.handler,如下圖所示。
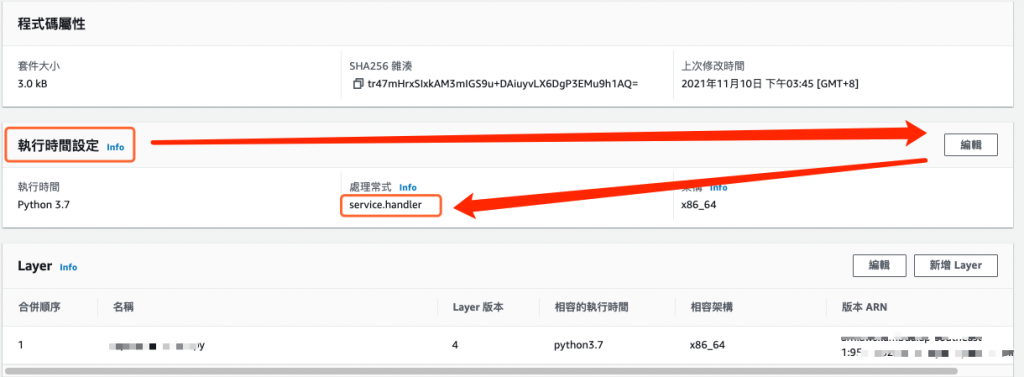
圖 14、修改執行時間設定中的處理常式
最後點擊 Test 進行測試,得到的結果如下圖所示,推論時間約 1.75 秒,所需記憶體為 990 MB。
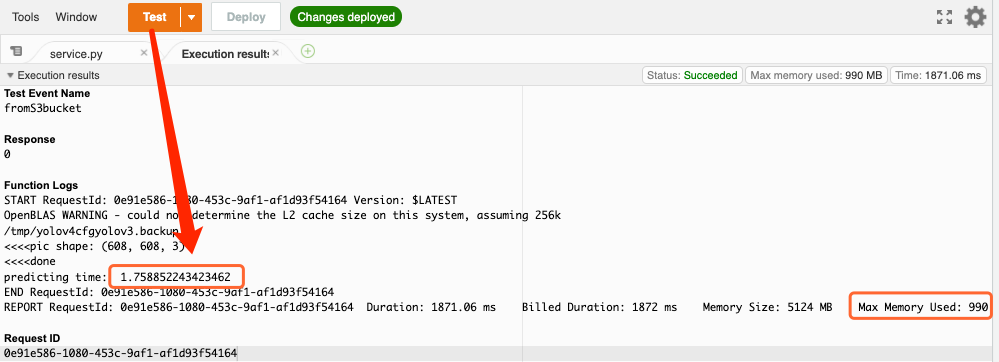
圖 15、使用 OpenCV 進行 YOLO 推論
因此,這似乎是一個可以接受的解決方案,表 1.列出目前為止的所有 YOLO 辨識部署解決方案。
表 1、 使用 EC2/Lambda/SageMaker 進行 YOLO 辨識比較
| 使用 EC2 | 使用 Lambda (darknet) | 使用 SageMaker | 使用 Lambda (OpenCV) | |
|---|---|---|---|---|
| 成本(USD) | 0.736/hour | 0 | 1.0304/hour | 0 |
| 時間(秒) | ~ 0.1 秒 | > 60 秒 | 1秒 左右 | 1-3 秒 |
| 可用性 | 較差 | AWS 托管 | AWS 托管 | AWS 托管 |

