前面我們介紹了如何使用探索性分析(EDA)來觀察資料的型態,也學會用圖表來找出這些資料的潛在訊息,今天我們就要開始對資料進行處理,不囉唆我們直接進正文。
缺失值(Missing Value)指的是在蒐集數據的過程中發生人為或機器上的疏失,導致資料缺失的情況。
根據缺失的特性,缺失值的種類可以分為以下幾種: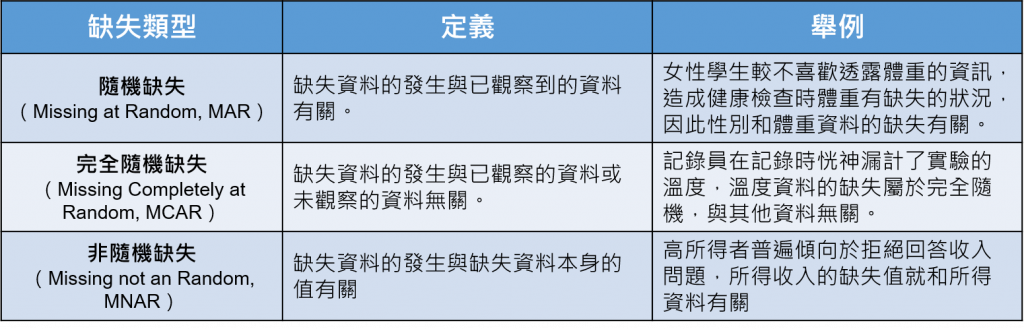
在現實生活中,我們所獲得的資料發生缺失值的情況是相當正常的,那為什麼我們需要處理缺失資料呢?最直觀的答案就是我們不處理的話,演算法是無法正常運作的。
缺失值的處理方法為刪除與補值,需依照資料的特性選擇較合適的處理:
直接刪除有缺失值的資料樣本
▲優點:
做法簡單
▲缺點:
可能會遺失重要資訊
若刪除資料與其他變數有關,會影響整體資料
▲以一個固定值去填補,例如全部補0
▲依照時間順序去補值(跟時間序列有關的資料)
▲依照現有資料的平均值、中位數、眾數...等去補值
▲透過機器學習的預測方法去補值
下面我們將使用"Titanic生存預測"這個資料來做示範,讓大家也能一起動手嘗試。
這是個典型的資料集,幾乎每個初學者都會透過這個資料集進行第一個專案練習,此資料分析目的在於透過鐵達尼號船上一些船課的資料來預測乘客最後是否生還,對於初學者來說非常容易上手。

import pandas as pd
import numpy as np
train_df = pd.read_csv('train.csv')
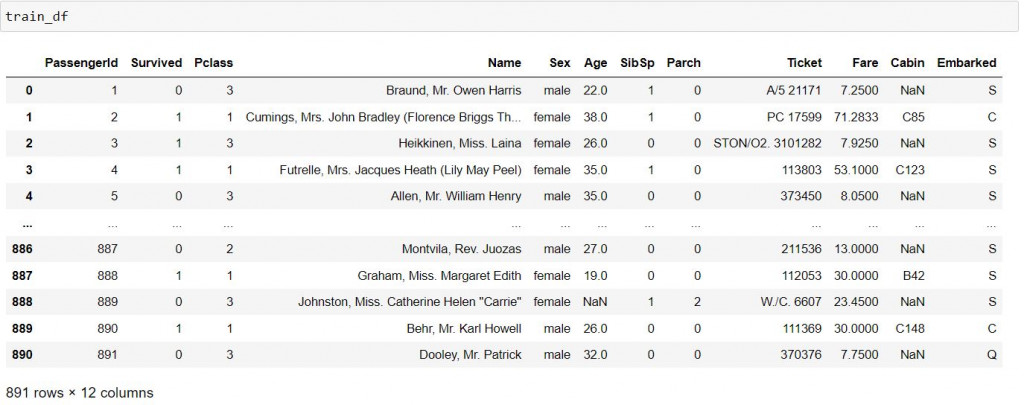
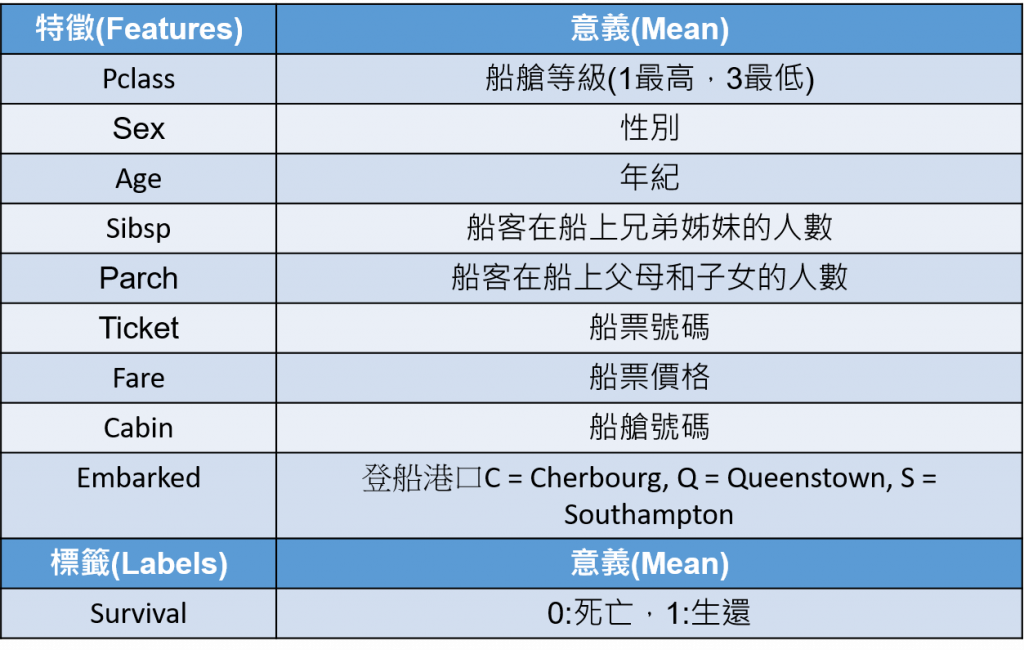
train_df.insull().sum()
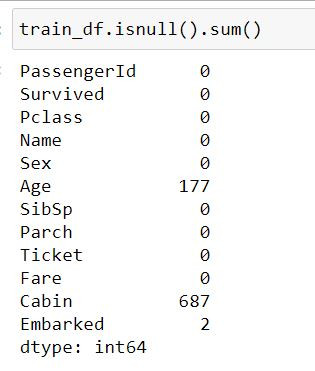
def Missing_Counts( Data, NoMissing=True ) :
missing = Data.isnull().sum()
if NoMissing==False :
missing = missing[ missing>0 ]
missing.sort_values( ascending=False, inplace=True )
Missing_Count = pd.DataFrame( { 'Column Name':missing.index, 'Missing Count':missing.values } )
Missing_Count[ 'Percentage(%)' ] = Missing_Count['Missing Count'].apply( lambda x: '{:.2%}'.format(x/Data.shape[0] ))
return Missing_Count
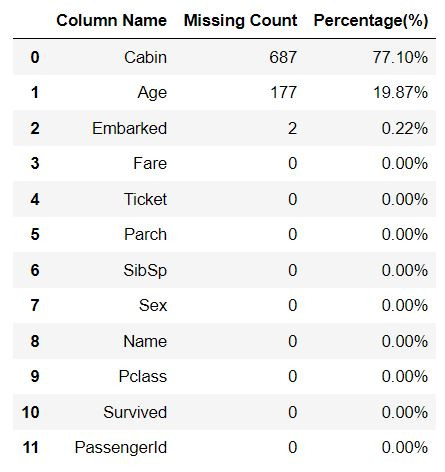
Missing_Counts(train_df)
train_df=train_df.dropna(subset=["Embarked"]) #subset參數裡面放要刪除缺失值的特徵
刪除兩筆資料後,總資料數下降為889筆。接著我們處理缺失將近77%的Cabin資料。
train_df['Cabin'].unique()

像這種屬於完全隨機缺失的資料不太好進行補值,假如刪除的話也會遺失過多資訊,因此我的作法是自行給定一個值"No_Cabin"代表缺失船艙號碼的乘客來進行補植。
train_df['Cabin']=train_df['Cabin'].fillna("No_Cabin")
年齡的處理就比較麻煩了,缺失了將近20%的資料外,年齡會受其他變數的影響,例如年紀較小的人可能會有家長陪同(Parch),逃生時可能會優先,存活機率也相對大。因此我們需要比對其他變數對年齡的影響來做補值。
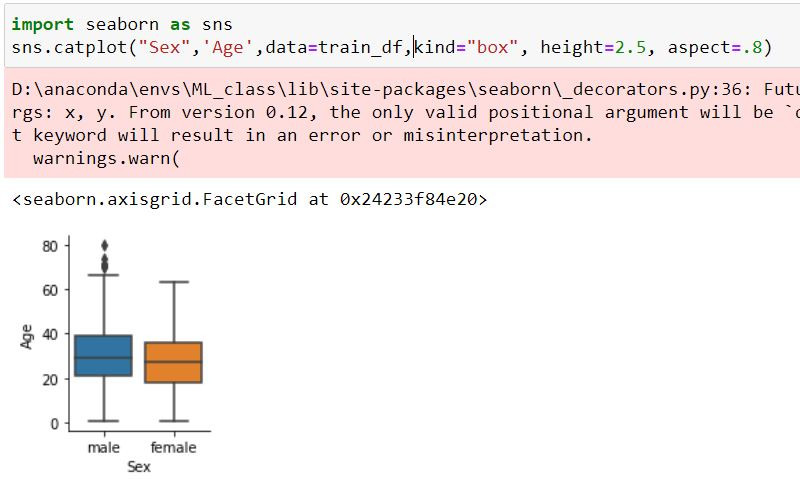
可以發現不論男女在各年齡層都有族群存在,Sex不太能做為補值參考
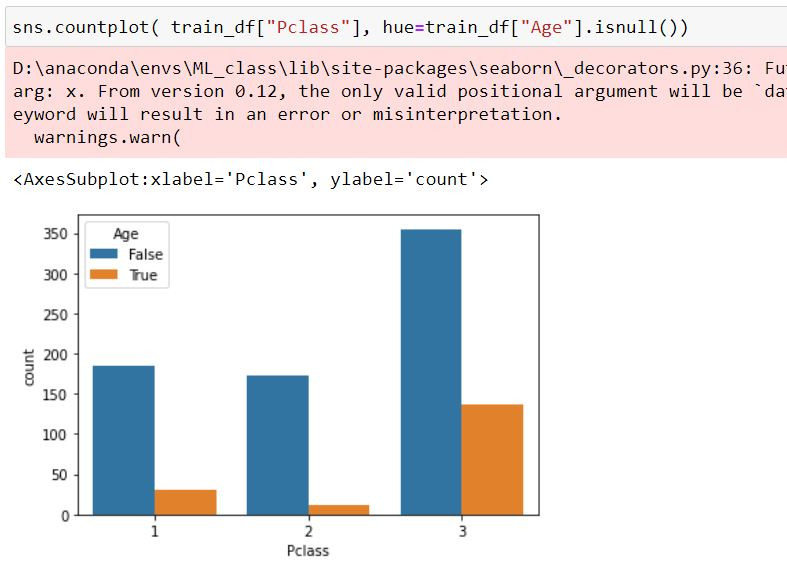
發現大部分的缺失狀況都是出現在3等艙中
index_survived = (train_df["Age"].isnull()==False)&(train_df["Survived"]==1)
index_died = (train_df["Age"].isnull()==False)&(train_df["Survived"]==0)
sns.distplot( train_df.loc[index_survived ,'Age'], bins=20, color='blue', label='Survived' )
sns.distplot( train_df.loc[index_died ,'Age'], bins=20, color='red', label='Survived' )
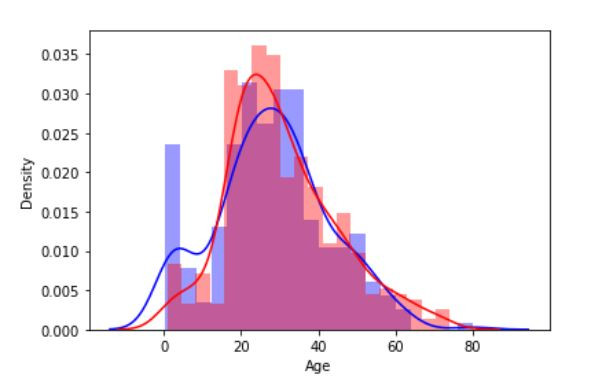
可以看到有較明顯生存率的年齡分布是10歲以下、17歲、26歲左右的年齡(藍色較高的)
外國人的稱謂和職業、年紀多少會有點關係,因此我們先處理Name這個欄位,將姓氏取出,命名為新的特徵"Title"
train_df['Title'] = train_df.Name.str.split(', ', expand=True)[1]
train_df['Title'] = train_df.Title.str.split('.', expand=True)[0]
train_df['Title'].unique()

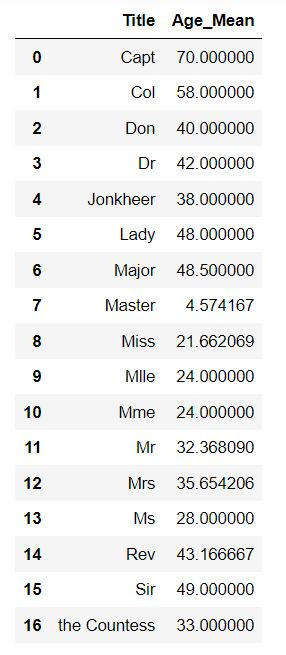
# 計算每個 Title 的年齡平均值
Age_Mean = train_df[['Title','Age']].groupby( by=['Title'] ).mean()
Age_Mean.columns = ['Age_Mean']
Age_Mean.reset_index( inplace=True )
display( Age_Mean )
train_df=train_df.reset_index() #重整index
train_df["Age"].isnull()
for i in range(len(train_df["Age"].isnull())):
if train_df["Age"].isnull()[i]==True:
for j in range(len(Age_Mean.Title)):
if train_df["Title"][i]==Age_Mean.Title[j]:
train_df["Age"][i]=Age_Mean.Age_Mean[j]
今天我們介紹了缺失值的原因、類別以及一些簡單的處理方法,其實這些都算是皮毛而已,缺失值填補的學問可是非常大的,有興趣的朋友可以找一些Paper來看,小編想說的是,缺失值的填補沒有一種方法是絕對的,我們也很難去驗證我們填補的值是否正確(畢竟資料就遺失了,對照不了),所以我們只能透過分析相關性,用比較合理的方法去還原本來的資料,最後希望大家都有從中受益啦!