
俗話說:「知己知彼,百戰百勝」,這句話同樣也適合用在資料科學上,
我們必須對資料的背景非常熟悉,才能夠設計出適合的演算法。
今天,讓我介紹這系列文用到的人臉表情資料集:Facial Expression Recognition 2013 (FER2013)。
FER2013資料集來自一個西元2013年,
國際機器學習大會(International Conference on Machine Learning, ICML)舉辦的競賽,
如今,ICML已成為國際頂級學術會議,ICML和NeurIPS以及ICLR三分天下,
掌握機器學習的前瞻技術。
請大家先去Kaggle下載資料:(載點)
我們只需要下載fer2013.tar.gz就好。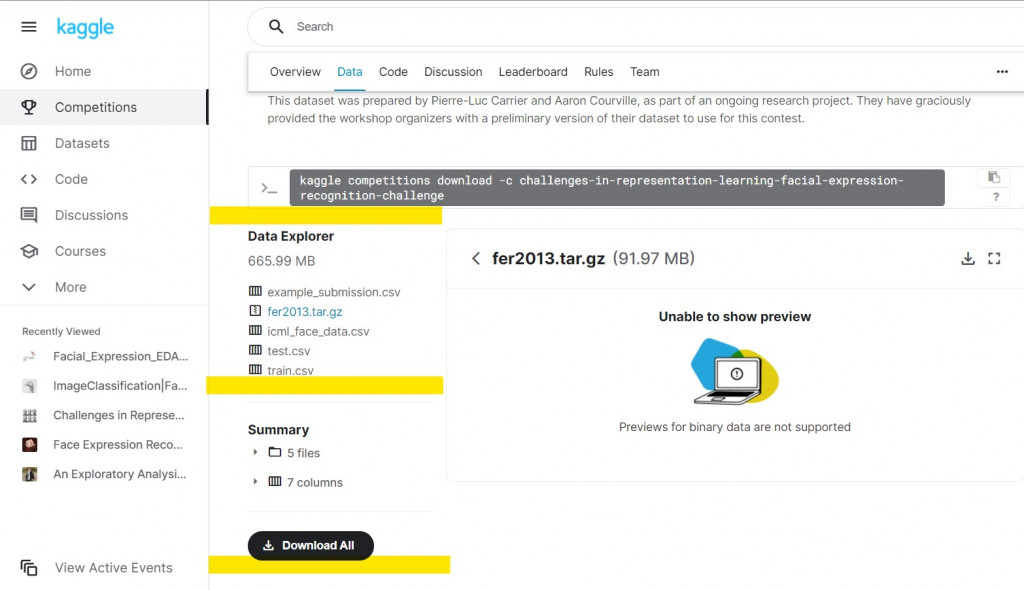
將fer2013.tar.gz解壓縮後,留下fer2013.csv就好。
資料中每張照片已經存成48x48的pixel,展開後儲存在fer2013.csv中。
表情共有7類:0=Angry、1=Disgust、2=Fear、3=Happy、4=Sad、5=Surprise、6=Neutral。
圖片範例來源
我相信在座各位都玩過MNIST或是CIFAR資料集,accuracy隨隨便便衝上0.9不是問題。
你們一定心想:不過就是一個影像分類的問題,隨便疊出一個CNN模型不就解決了嗎?
我將用下面一張表來說明(未來有機會再介紹各個模型架構:
| 模型 | 首發年分 | ImageNet test top-5 error |
|---|---|---|
| AlexNet | 2012 | 15.32% |
| VGG | 2014 | 6.8% |
| GoogleNet | 2014 | 6.67% |
| ResNet | 2015 | 3.57% |
| ResNeXt | 2016 | 3.03% |
| SENet | 2017 | 2.25% |
| MobileNet-224 | 2017 | 10.5% |
| EfficientNet-B7 | 2019 | 2.9% |
順帶一提,在2015年的ImageNet影像辨識大賽上,ResNet的top-5錯誤率僅有3.57%,優於人類的5%。
有人說這是機器打敗人類的證明,
但我覺得這只能說明機器在1000個特定類別中打敗了人類,
世界上還有數不清的類別是機器沒辦法辨識的。
不過,從此開始我們終於可以放心讓機器在特定領域中幫助人類做影像辨識了。
回到正題,這個FER2013比賽時間點是2013年4月12日,
當時的模型發展到AlexNet,這是只有8層深度的網路。
並且筆記型電腦的GPU大概只有到GeForce GT 630M等級的。
更不用說Tensorflow在2015年才發布0.1版本。
在當時,這個FER2013的任務可一點都不簡單!
冠軍的準確率也只有到71.16% (說不定我接下來做的更差)
下圖為當年private test的準確率排行榜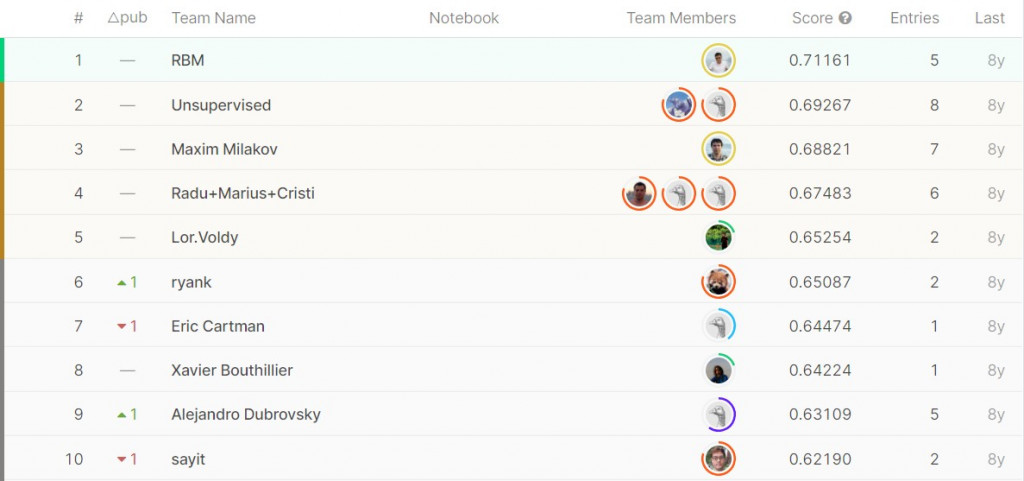
介紹完FER2013後,對於自己能做出來的信心大大的降低了。
希望我能打敗當年的冠軍XD

 iThome鐵人賽
iThome鐵人賽