上次我們提到原始文本往往夾帶大量無意義的字符,於是我們利用了正則表達式來清理資料。然而此時的文本由大量的語句所構成,各個語句中又帶有複雜的文法結構(例如倒裝修詞、時態差異、關係代名詞、分詞構句、形容詞的前後位修式等)和各種對於電腦來說晦澀難懂的資訊(例如華麗的詞藻),尚未能進行分析與處理。因此我們仍需要將清理過後的文字資料進一步拆解成電腦可以處理的最小單位。以英文而言,詞(word)可以被視為一種最小單位,詞與詞之間有著明顯的分隔,而中文的字(character)不一定能單獨表示其在文本中所呈現的意義,很難區隔出可處理的最小單位。本篇的自然語言處理技巧圍繞在以英文為代表的屈折語(fusional language: 為印歐語系中普遍的語言,如法文、德文、西班牙文等拼音文字),可藉由詞與詞之間的空格找出最小單位,而暫不涉及以中文為代表的孤立語(isolating language)或以日文、韓文為代表的黏著語(agglutinative language)。
由於中文詞集是一個開放集合,不存在任何一個詞典或方法可以盡列所有的中文詞。當處理不同領域的文件時,領域相關的特殊詞彙或專有名詞,常常造成分詞系統因為參考詞彙的不足而產生錯誤的切分。
文字出處:http://ckipsvr.iis.sinica.edu.tw/
讓我們直接來瞧瞧以下這篇短文:
"When you start coding, it makes you feel smart in itself, like you're in the Matrix [film]," says Janine Luk, a 26 year-old software engineer who works in London. Born in Hong Kong, she started her career in yacht marketing in the south of France but found it's "a bit repetitive and superficial". So, she started teaching herself to code after work, followed by a 15-week coding boot camp.
文字出處:Why coders love the AI that could put them out of a job| BBC Business
在 Python 的實踐上,我們使用自然語言處理工具箱 NLTK (Natural Language Processing Toolkit) 來協助我們進行處理任務。第一步我們欲將以上的字串拆分成多個句子,此步驟稱之為斷句(Sentence Segmentation)。句號(.)是判斷句子結束很好的依據,但仍有些例外-省略用的句號,如 Mr. Williams、 Ph.D. 等。 好消息是, NLTK工具箱當中的 tokenize 模組,已經定義好了函式 sent_tokenize() 用來實現斷句:
from nltk.tokenize import sent_tokenize
raw_text = '''"When you start coding, it makes you feel smart in itself, like you're in the Matrix [film]," says Janine Luk, a 26 year-old software engineer who works in London. Born in Hong Kong, she started her career in yacht marketing in the south of France but found is's "a bit repetitive and superficial". So, she started teaching herself to code after work, followed by a 15-week coding boot camp.'''
# removing double quotes
text = re.sub(r"\"", '', raw_text)
# breaking text into sentences
text_sentences = sent_tokenize(text)
# printing out sentences
for i, sent in enumerate(text_sentences):
print("Sentence {}: {}".format(i + 1, sent), end = "\n\n")
我們將拆解的句子一一條列出來:
接下來我們進一步將句子拆分成更小的單位-單詞。值得注意的是,在英文當中單詞通常被認為能夠表示意義的最小單位-詞條(Token),將字串拆分成詞條的過程就是斷詞(word segementation),又稱記號化(Tokenisation)。此詞我們引入另一個拆分函式 word_tokenize() :
from nltk.tokenize import word_tokenize
for i, sent in enumerate(text_sentences):
print("Sentence {}: {}".format(i + 1, sent))
tokens = word_tokenize(sent)
print(tokens, end = "\n\n")
經過斷詞之後,我們檢視最短的第三句中的詞條:
由於詞條可以是單詞、標點符號(可以注意 NLTK 的 word_tokenize() 將之也視為詞條)、數字、有著特殊意義的符號(如 $ 、 € 、 ¥ 等貨幣符號),斷詞的方法並不唯一。我們亦可以根據需求設計其他的 tokenisers ,詳見本文最下方的連結 [2]。
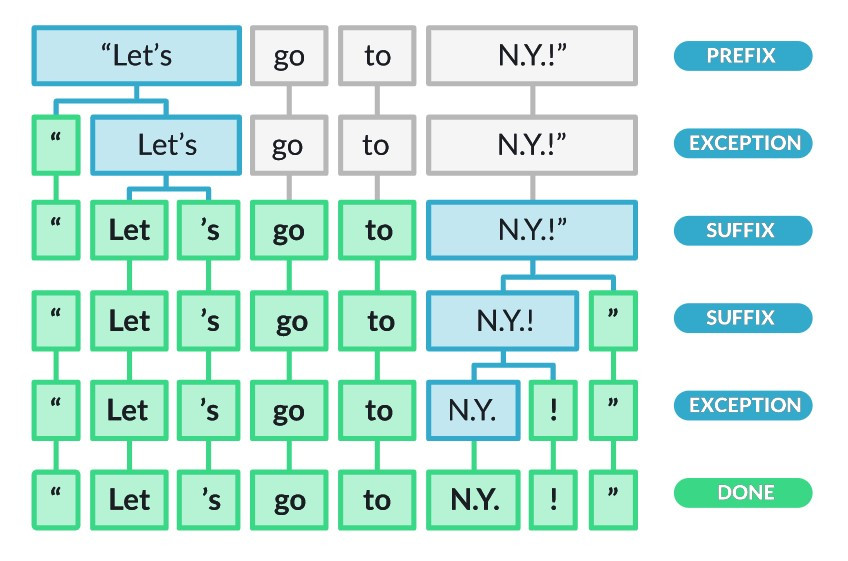
Tokeniser 的設計依賴於語言的選擇
圖片出處:spaCy 101: Everything you need to know
關於預處理就先介紹到這邊,明天我們將介紹文字的正規化!
默默祈禱疫苗的副作用不要太強
Gute Nacht!


 iThome鐵人賽
iThome鐵人賽