上次我們斷開了英文文本的鎖鏈,將龐大的字串拆解成成為詞條的小單元。語言中仍有時態變化、單複數型態、甚至是口語等複雜甚至隨機的因素不利於後續的文字處理,因此我們透過一系列的流程將詞條的變形一一還原。

圖片來源:https://imgflip.com/tag/normalization
英文的單詞(或小單位)具有以下常見的變形:
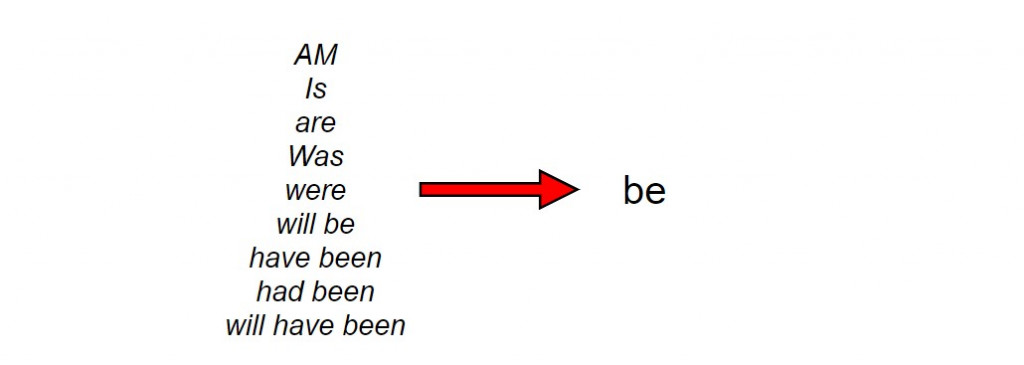
對詞條的歸一化,將意義相同的諸多變化形態一視同仁,有助於減少資料處理的負擔,這個過程稱之為正規化(normalisation)。
Why do we need text normalization?
When we normalize text, we attempt to reduce its randomness, bringing it closer to a predefined “standard”. This helps us to reduce the amount of different information that the computer has to deal with, and therefore improves efficiency.本文出處:Text Normalization for Natural Language Processing (NLP)
首先我們去除大小寫的差異,按照慣例將所有文字轉成小寫:
tokenised = ["The", "spectators", "all", "stood", "and", "sang", "the", "national", "anthem"]
# lowercasing each token
tokens_lower = [token.lower() for token in tokenised] # ['the', 'spectators', 'all', 'stood', 'and', 'sang', 'the', 'national', 'anthem']
在語言學中,詞幹(word stem)表示一個單詞中最基本且核心的形式,例如 friendships 就是由 friendship 與詞綴 -s 所組成, friendship 就是其詞幹;而 friendship 則是由 friend 與詞綴 -ship 所構成,此時 friend 則是其詞幹。因此詞幹的提取基於不同理念或不同演算法,有時會得到不同的結果。我們以常見的 Porter Stemming Algorithm、 Lancaster Stemming Algorithm 以及 Snowball Stemming Algorithm 說明,從而比較它們的差異。
# importing stemmer classes
from nltk.stem import PorterStemmer, LancasterStemmer, SnowballStemmer
tokens = ["the", "spectators", "all", "stood", "and", "sang", "the", "national", "anthem"]
# stemming
port = PorterStemmer()
stemmed_port = [port.stem(token) for token in tokens]
lanc = LancasterStemmer()
stemmed_lanc = [lanc.stem(token) for token in tokens]
snow = SnowballStemmer("english")
stemmed_snow = [snow.stem(token) for token in tokens]
# showing stemmed results
print("Porter: {}".format(stemmed_port))
print("Lancaster: {}".format(stemmed_lanc))
print("Snowball: {}".format(stemmed_snow))

很顯然,萃取詞幹並未能滿足我們減少詞形變化(inflection)的需求,因此我們轉而找尋更能代表單詞基本形式-詞位(lemma),例如 sings、 singing、 sang、 sung 共享同一個詞位 sing。以下我們將借用 NLTK.stem 模組中收錄的 WordNetLemmatizer 類別找出詞位,WordNet為普林斯頓大學所建立的免費公開詞彙資料庫。
from nltk.stem import WordNetLemmatizer
tokens = ["the", "spectators", "all", "stood", "and", "sang", "the", "national", "anthem"]
lemmatiser = WordNetLemmatizer()
lemmatised = [lemmatiser.lemmatize(token) for token in tokens]
print("lemmatised: {}".format(lemmatised))
執行結果為:
Oops! 效果依然差強人意。我們加入一個法寶,就能夠將詞形變出來。至於該法寶是什麼,我們留到下集再介紹。
"""
code snippets
"""
lemmatised_magic = [lemmatiser.lemmatize(token, get_part_of_speech(token)) for token in tokens]
print("lemmatised_magic: {}".format(lemmatised_magic))

Voilà! 原形畢露了!
在文句中有些單詞並對於詞義的傳達並無太大的作用,如 a/ an、 the 、 is/ are等,被稱之為停用詞( stop words)。如何去除停用詞呢?請稍安勿躁往下看:
from nltk.corpus import stopwords
nltk.download("stopwords")
# defining stopwords in English
stop_words = set(stopwords.words("english"))
# removing stop words
words_no_stop = [word for word in lemmatised if word not in stop_words]
print("stop words removed: {}".format(words_no_stop))
檢視結果:
我想今天所談及的正規化處裡技巧中,最令人費解的就是 Stemming 與 Lemmatisation 的差別了。下圖呈現兩者之比較:
詞幹提取與詞形還原的差異
圖片來源:DEVOPEDIA
當我們在搜尋引擎上輸入關鍵字,並不需要輸入與搜尋結果百分百吻合的語句,也能立即找出我們要的資訊,文本的正則化功不可沒:
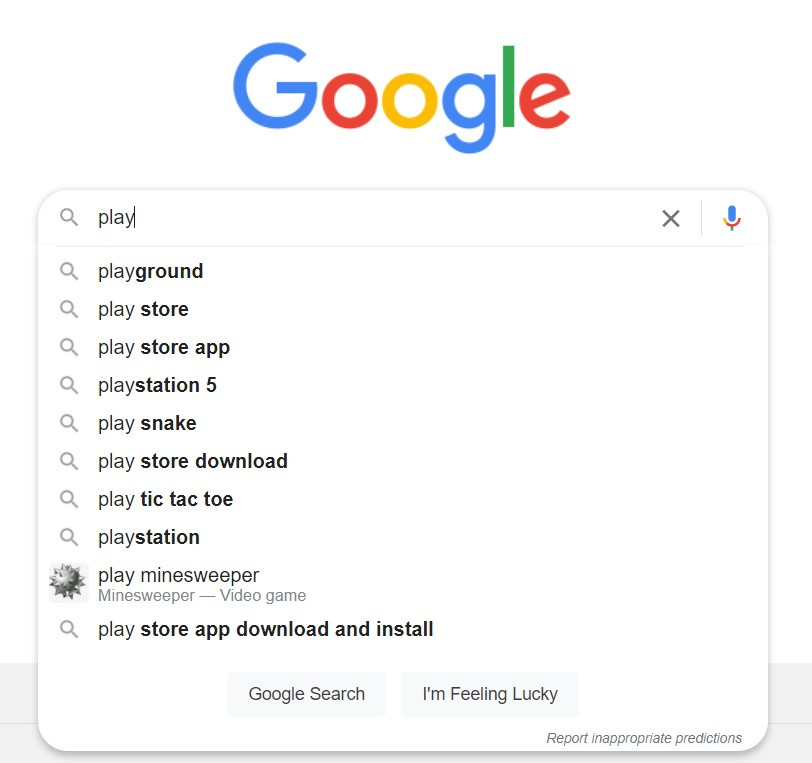
今天的介紹就到此,また明日!


 iThome鐵人賽
iThome鐵人賽