本章開始歸納出幾個K8s特性可以提升AI效能並以Spark計算圓周率Pi示範。原文寫於2019如無法執行請閱讀官方文件
Namespace 的概念,很多程式語言都有Namespace(命名空間)的概念比如在C++中我們可以透過不同的Namespace(命名空間)創造兩個相同名子的變數Variable,Namespace在K8s也是類似的用法,比如我們可以創造一個命名空間叫做Intern 一個叫做Employee,就可以在各自Namespace(命名空間)跑各自的Spark不會衝突不用排隊不用考慮FIFO, Priority,另外我們也可以給予兩個命名空間不同的計算資源CPU/GPU,這樣就算全公司都擠在同一個雲平台也不會產生實習生的程式排擠到資深人員的工作。
首先啟動一組GKE群集共有5個節點每個節點4CPU, 3.6MEM,因為Saprk官方預設有啟動Anti-affinity機制,畢竟Spark就是個分散式計算引擎當然要一次開5個node來玩玩才有趣,至於預設為何要開啟Anti-affinity後面文章會解說。
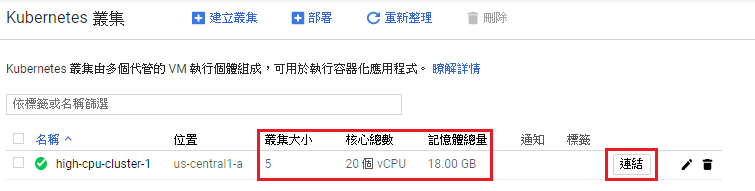
接著點上圖中的"連結"會SSH連線到GKE Master,並執行以下指令創造兩個namespace。
kubectl create namespace spark-intern
kubectl create namespace spark-employee

接著在下kubectl get namespaces,我們就可以看到剛剛創建的Namespace(命名空間)

接著我們幫它配置資源使用量,下面這段程式碼用cat>> filename << EOF包起來,直接複製貼上不用vi
cat >> StaffResource.yaml << EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quotas
namespace: spark-intern
spec:
hard:
requests.cpu: "3"
requests.memory: 4Gi
limits.cpu: "3"
requests.memory: 4Gi
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quotas
namespace: spark-employee
spec:
hard:
pods: "5"
requests.cpu: "10"
requests.memory: 16Gi
limits.cpu: "10"
requests.memory: 16Gi
EOF
接著下kubectl create -f StaffResource.yaml運行yaml檔

接著我們要在兩個Namespace(命名空間)跑Spark官方的spark-pi程式,來看看兩者是否真的有同時處理沒有衝突,並且是否有依照我們所設定的資源數量進行運算,在這之前先幫spark開啟對應的權限serviceaccount與clusterrolebinding即K8s群集控制權。
kubectl create serviceaccount spark-intern -n spark-intern
kubectl create clusterrolebinding spark-intern --clusterrole=edit --serviceaccount=spark-intern:spark-intern -n spark-intern
kubectl create serviceaccount spark-employee --namespace=spark-employee
kubectl create clusterrolebinding spark-employee --clusterrole=edit --serviceaccount=spark-employee:spark-employee --namespace=spark-employee

接著下載Spark程式,解壓縮進入資料夾
wget http://apache.mirrors.lucidnetworks.net/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
sudo tar -xzf spark-2.4.4-bin-hadoop2.7.tgz
cd spark-2.4.4-bin-hadoop2.7
接著再找出K8s Master的IP,填入bin/spark-submit的--master參數後
K8sMaster="k8s://$(kubectl cluster-info | grep -n "Kubernetes master" | cut -f 6,6 -d " ")"
echo $K8sMaster

再來我們要來執行Saprk-pi任務,記得將echo $K8sMaster得到的字串取代bin/spark-submit的--master參數,這裡我們啟動兩個Terminal分開執行
bin/spark-submit \
--master <K8sMasterIP ex: k8s://https://35.200.234.221> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.driver.limit.cores=1 \
--conf spark.kubernetes.executor.request.cores=10m \
--conf spark.kubernetes.executor.limit.cores=50m \
--conf spark.kubernetes.namespace=spark-intern \
--conf spark.kubernetes.container.image=ted00132/spark:v1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-intern \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.3.jar
bin/spark-submit \
--master <K8sMasterIP ex: k8s://https://35.200.234.221>\
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.driver.limit.cores=1 \
--conf spark.kubernetes.executor.request.cores=100m \
--conf spark.kubernetes.executor.limit.cores=500m \
--conf spark.kubernetes.namespace=spark-employee \
--conf spark.kubernetes.container.image=ted00132/spark:v1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-employee \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.3.jar
接著用kubectl get pod --all-namespaces或kubectl get pod -n spark-intern或kubectl get pod -n spark-employee,就可以看到POD進程運行的狀況

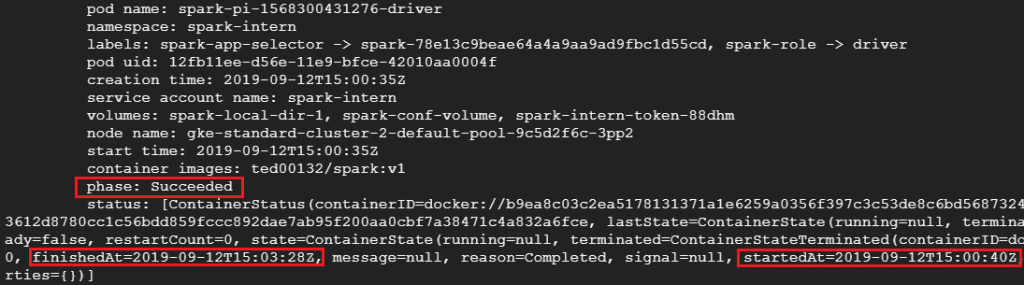
接著我們可以看到兩組相同的Spark-pi程序分別在不同的namespaces命名空間執行並且依照我們給予的配額與POD/Spark-Executor數進行分散式運算,根據下圖我們可以看出spark-intern中的Spark花了3分28秒才解出pi而spark-employee中的spark只花了25秒就解出pi;這跟我們給予的CPU配額與POD/Spark-Executor數呈現正相關,喜歡追根究底的朋友可以用以下指令看POD/Spark-Executor實際的配置
kubectl describe pod <pod-name or spark-executor-name> -n <namespace-name>
實際的配置會跟我們再bin/spark-submit輸入的幾個 --conf參數一樣,並受到StaffResource.yaml所設定的配額限制,有興趣的朋友可以試試不同參數!最後附上執行結果圖。