好酒沉甕底,精彩在最後;只是要付出一點點代價。
前面提到過,使用OpenCV & Dlib來做人臉偵測,大概可以分為四種方式:
今天說這個
今天要介紹第四種方式。
習慣上我喜歡稱呼這個方法叫Dlib神經網路檢測,
同樣對應昨天提到的OpenCV神經網路檢測方法,這個方法實際上也是使用已訓練的模型來做預測。雖然運算花費時間最長,但準確率是這四個方法中最高的。
那會很難使用嗎?
跟著一起實作你就知道了!
face_detection目錄下新增一個Python檔案dlib_mmod.py
# 匯入必要套件
import time
from bz2 import decompress
from os import remove
from os.path import exists
from urllib.request import urlretrieve
import cv2
import dlib
import imutils
import numpy as np
from imutils.face_utils import rect_to_bb
from imutils.video import WebcamVideoStream
def main():
# 下載模型檔案(.bz2)與解壓縮
model_name = "mmod_human_face_detector.dat"
if not exists(model_name):
urlretrieve(f"https://github.com/davisking/dlib-models/raw/master/mmod_human_face_detector.dat.bz2",
model_name + ".bz2")
with open(model_name, "wb") as new_file, open(model_name + ".bz2", "rb") as file:
data = decompress(file.read())
new_file.write(data)
remove(model_name + ".bz2")
# 初始化模型
detector = dlib.cnn_face_detection_model_v1(model_name)
# 啟動WebCam
vs = WebcamVideoStream().start()
time.sleep(2.0)
start = time.time()
fps = vs.stream.get(cv2.CAP_PROP_FPS)
print("Frames per second using cv2.CAP_PROP_FPS : {0}".format(fps))
while True:
# 取得當前的frame,變更比例為寬300,並且轉成RGB圖片
frame = vs.read()
img = frame.copy()
img = imutils.resize(img, width=300)
rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 取得frame的大小(高,寬)
ratio = frame.shape[1] / img.shape[1]
# 偵測人臉,將辨識結果轉為(x, y, w, h)的bounding box
results = detector(rgb, 0)
boxes = [rect_to_bb(r.rect) for r in results]
# loop所有預測結果
for box in boxes:
# 計算bounding box(邊界框)與準確率 - 取得(左上X,左上Y,右下X,右下Y)的值 (記得轉換回原始frame的大小)
box = np.array(box) * ratio
(x, y, w, h) = box.astype("int")
# 畫出邊界框
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 標示FPS
end = time.time()
cv2.putText(frame, f"FPS: {str(int(1 / (end - start)))}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7,
(0, 0, 255), 2)
start = end
# 顯示影像
cv2.imshow("Frame", frame)
# 判斷是否案下"q";跳離迴圈
key = cv2.waitKey(1) & 0xff
if key == ord('q'):
break
if __name__ == '__main__':
main()
python face_detection/dlib_mmod.py,跑出來的範例結果會是這樣: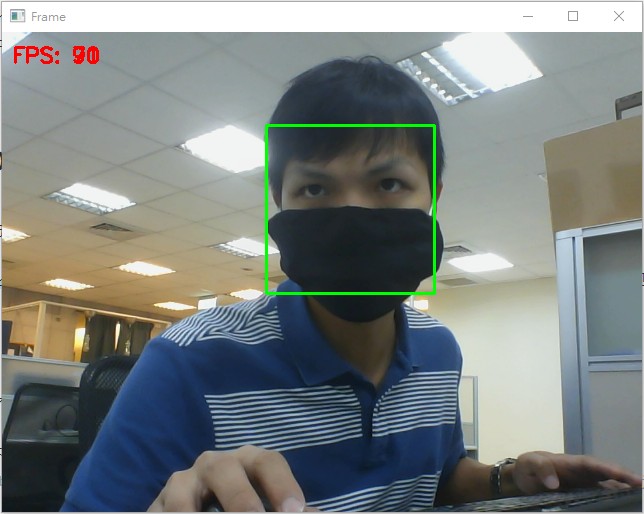
如何,程式碼不難吧?
可以看到,dlib中人臉偵測的兩種方式Dlib特徵檢測與Dlib神經網路檢測的做法除了在載入模型的函數不同以外,幾乎一模一樣。
如果你還記得Day3最後面提到的:
辨識準確率越高通常會需要花費更多運算時間 (指相同的硬體設備下);如果你會用顯示卡(GPU)資源來做ML請直接選第四個 (Dlib max-margin object detector (MMOD))
如果你安裝Dlib是按照Day9的作法透過PyCharm的Install Packages安裝的,實際跑上面的範例你會發現:畫面延遲非常的嚴重,fps幾乎是0。這個原因是因為Dlib神經網路檢測作法需要花費較長的時間,只有在GPU支援的情況下才有可能跑出類似我上面範例結果的情況 (預設安裝的版本是不支援GPU運算的)。
那要如何做?
簡單描述一下:
python setup.py install編譯與安裝支援GPU的Dlib詳細的做法有興趣的邦友可以參考這篇,或是有問題也可以留言,我會盡可能幫上你的忙。
使用Dlib神經網路檢測也同樣可以直偵測出戴口罩的人臉;到這裡你應該要有一個直覺:使用神經網路模型做的人臉偵測,通常都不需要完整的人臉或是臉部不需要面對鏡頭就可以辨識
這裡辨識結果的fps僅供參考 (我是在有GPU資源下才能跑出這樣的結果,使用的是GTX 1660),但也說明了使用神經網路模型通常都會需要GPU的資源才有辦法順暢運行
參考程式碼在這
關於這四個方法,明天我會再做一個總結。
保持一篇文章只有一個重點。
See you next day!
版主大大,請問一下,我照文章上面的方式去操作,雖然鏡頭能打開,但FPS顯示為0,而且畫面很卡,請問這樣是正常的嗎?

