https://github.com/PacktPublishing/Machine-Learning-Algorithms
首先導入套件,上面的是用來算數學的;下面的是用來畫畫的,並且幫它們取綽號(np & plt)。
import numpy as np
import matplotlib.pyplot as plt
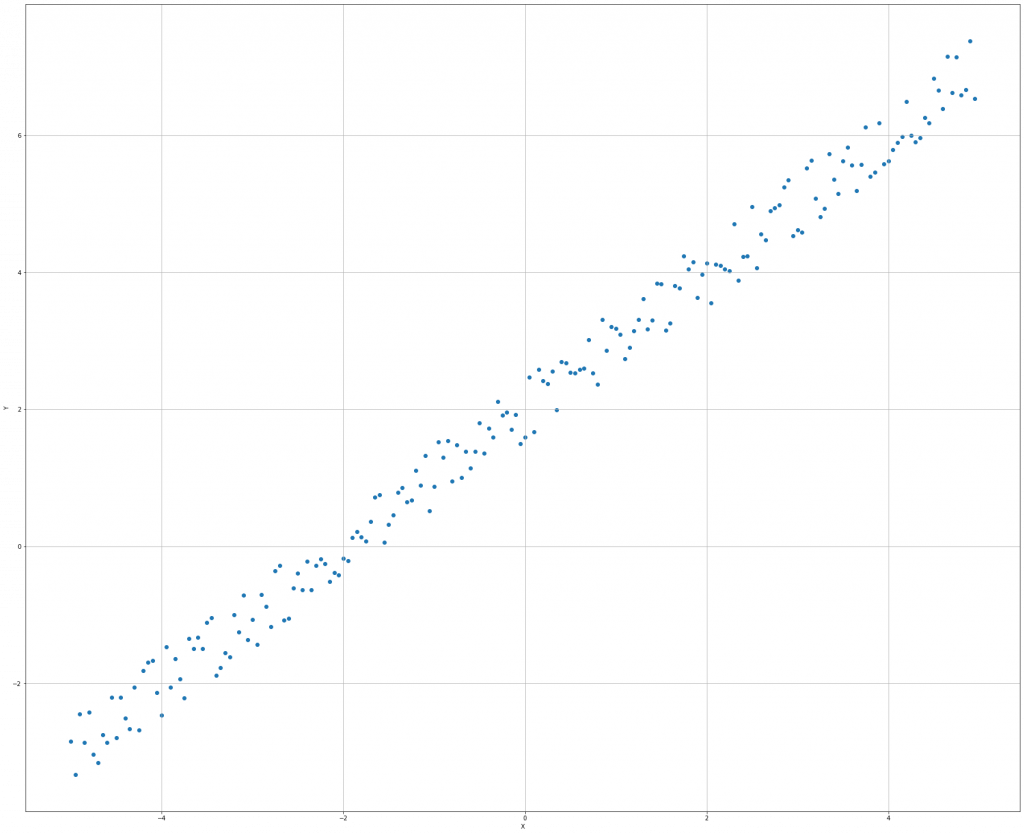
再來,用seed()隨機產生整數的亂數後,使用最小平方差公式,定義損失函數。
np.random.seed(1000) def loss(v): e = 0.0 for i in range(nb_samples): e += np.square(v[0] + v[1]*X[i] - Y[i]) return 0.5 * e
接著,定義梯度下降法函數。
def gradient(v): g = np.zeros(shape=2) for i in range(nb_samples): g[0] += (v[0] + v[1]*X[i] - Y[i]) g[1] += ((v[0] + v[1]*X[i] - Y[i]) * X[i]) return g
最後,從scipy套件導入minimize最優化函數,就可以印出二維線性回歸圖了。
from scipy.optimize import minimize result = minimize(fun=loss, x0=np.array([0.0, 0.0]), jac=gradient, method='L-BFGS-B')
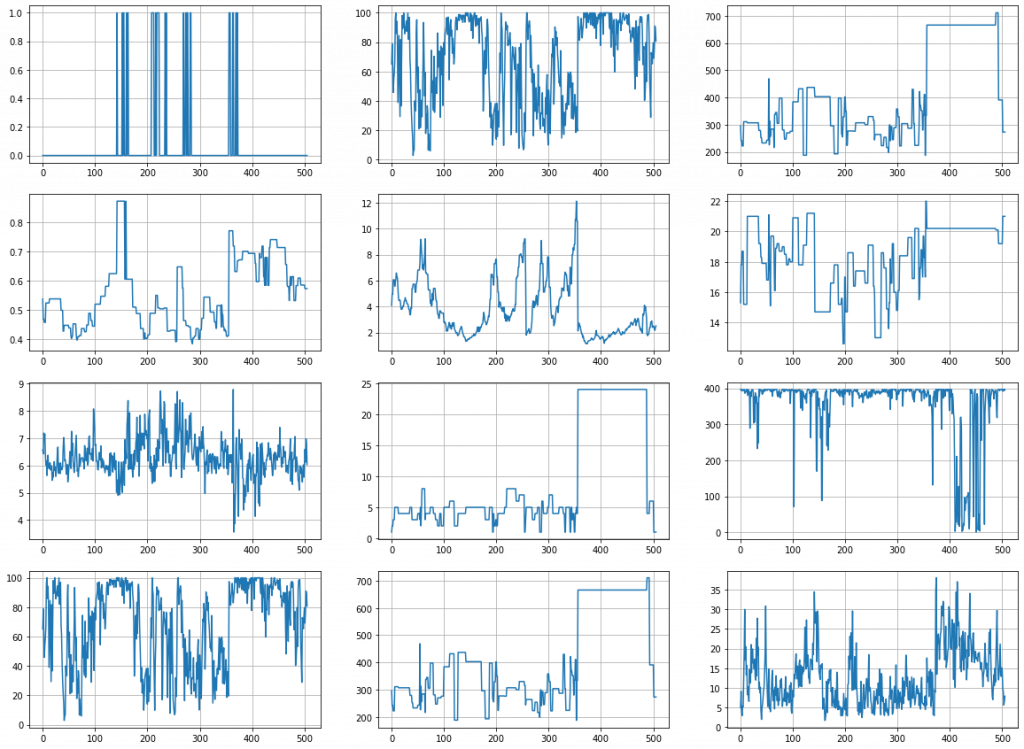
首先導入boston範例,將它印出看看長怎樣。
from sklearn.datasets import load_boston def show_dataset(data): fig, ax = plt.subplots(4, 3, figsize=(20, 15)) for i in range(4): for j in range(3): ax[i, j].plot(data.data[:, i + (j + 1) * 3]) ax[i, j].grid() plt.show() boston = load_boston() show_dataset(boston)
因為原始資料太少,所以把資料拆成訓練用跟測試用來交叉驗證,就是把資料切成K等分,K-1等分用來訓練模型,就會迭代K次,最後,建模並訓練模型。
from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split, cross_val_score X_train, X_test, Y_train, Y_test = train_test_split(boston.data, boston.target, test_size=0.1) lr = LinearRegression(normalize=True) lr.fit(X_train, Y_train)
再來,使用scikit-learn內建score()評估模型,計算準確率。
print('Score %.3f' % lr.score(X_test, Y_test)) // Score 0.693
接著,運用cross_val_score()選擇評分測試方式,這裡用負均方差。
from sklearn.model_selection import train_test_split, cross_val_score scores = cross_val_score(lr, boston.data, boston.target, cv=7, scoring='neg_mean_squared_error') print('CV Negative mean squared errors mean: %.3f' % scores.mean()) // CV Negative mean squared errors mean: -37.287 print('CV Negative mean squared errors std: %.3f' % scores.std()) // CV Negative mean squared errors std: 46.790
最後,計算實際結果與樣本之間的差,越靠近1越好、越靠近0越不好。
r2_scores = cross_val_score(lr, boston.data, boston.target, cv=10, scoring='r2') print('CV R2 score: %.3f' % r2_scores.mean()) // CV R2 score: 0.203


 iThome鐵人賽
iThome鐵人賽