一. self-attention的編碼方式
昨天說明了注意力主要是要明確算出input與output之間相關的資訊量,那怎麼算呢,這邊我會說明現在最常使用的self-attention的方法。
self-attention其實就是會將每個詞會將其他詞的資訊考慮進去,也就是在對某一個詞的做編碼時,將整個句子的上下文語境考慮進去,以李孟的這篇文章[1]提到的例子來說明:
句子1: 胖虎叫大雄去買漫畫,回來慢了就打他
句子2: 妹妹說胖虎是「胖子」,他聽了很不開心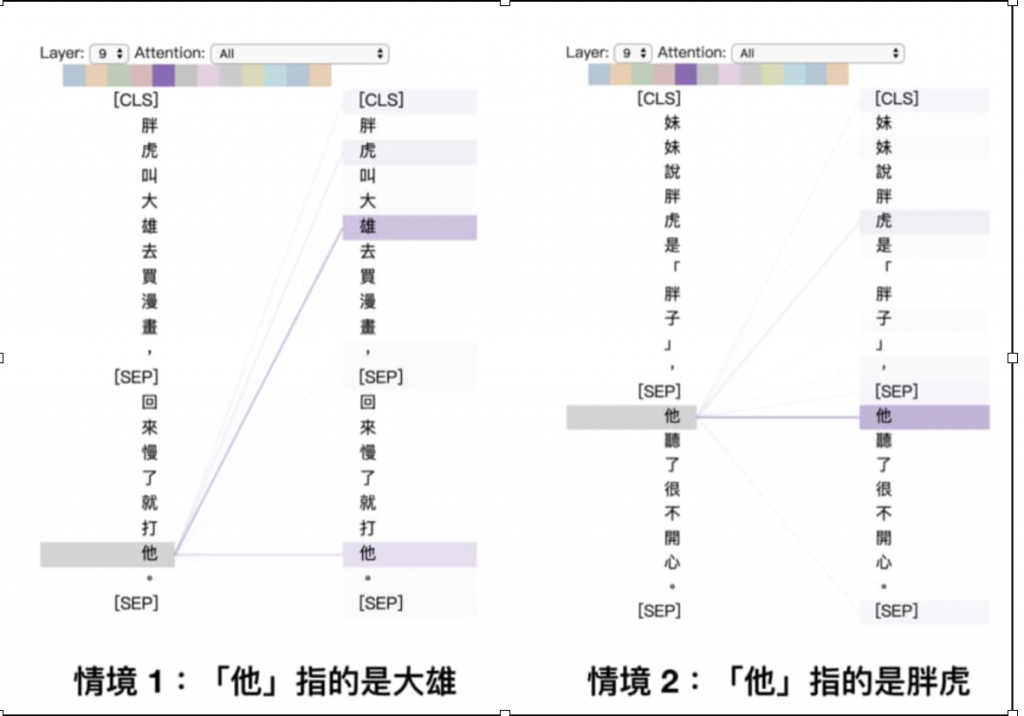
這2個他代表的人不同,第一個句子他應該要接收較多的'大雄'這個資訊,第二個句子他應該要接收較多的'胖虎'這個資訊,藉由這樣去計算每個詞與每個詞之間的相關程度,最後就可以encdoe出一個適合這個句子的編碼囉~~
二. 計算方式
目的: 得到一個可以代表句子文章且考慮上下文的編碼向量
這邊我會用這個網站[2]的圖來解說~這網站寫的其實非常詳細了,各位也可以詳讀全,需要有三個矩陣來計算: Queries、Keys與Values,假設現在有一個句子叫做'Thinking Machines':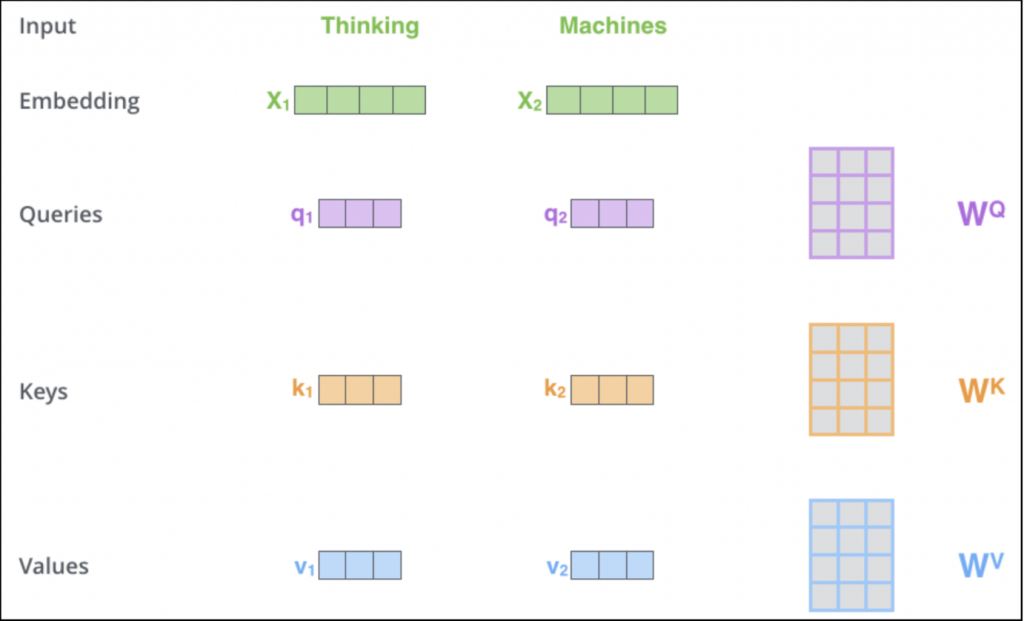
那要怎麼利用這三個矩陣來得到Queries, Keys, Values及其意義:
• 利用訓練三個矩陣WQ、WK及WV
• Q: query,需要查詢的問題,ex: 第一個詞(q1)想知道他在這個句子所佔的資訊為何
• K: key,等著被查的答案群,q會跟所有k做計算
• V: value,實際的特徵訊息
如下圖,我們將thinking(x1)與machines(x2)疊起來,隨機產生三個矩陣(WQ、WK及WV,這三個矩陣是在train的時候會調整的):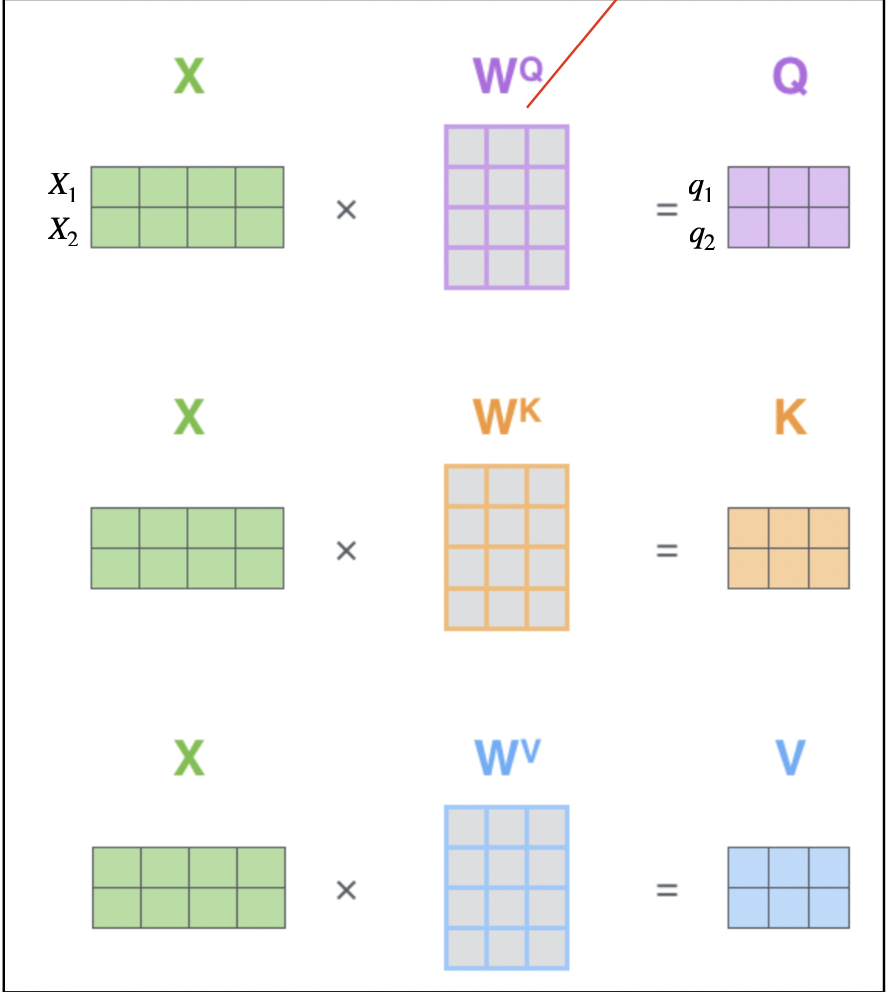
計算流程:
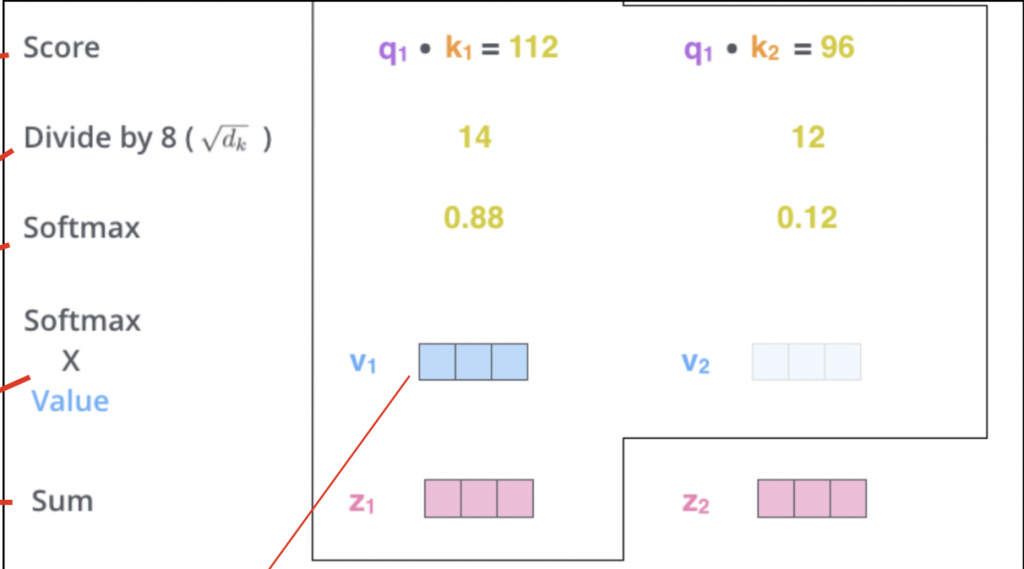
--
以上大致就是self-attention的計算方式,transformer與bert裡面都是這個東西而已XD
參考資訊
[1] https://leemeng.tw/attack_on_bert_transfer_learning_in_nlp.html
[2] https://jalammar.github.io/illustrated-transformer/

