一. Sequence to Sequence
在說明transformer之前,先介紹一下何謂Sequence to Sequence的模型。Sequence to Sequqnce 簡寫為 Seq2Seq, 於2014時 Yoshua Bengio 團隊的paper有提到這樣的一個架構,主要是處理機器翻譯的問題。
各位可以看成Seq2Seq的input與output只要是sequence的形式其實就可以使用這樣的model,通常架構會是有一個encoder與一個decoder組成,encoder可以當作是機器正在消化input的資訊,再由decoder轉化成另一種序列的形式,大致如下圖: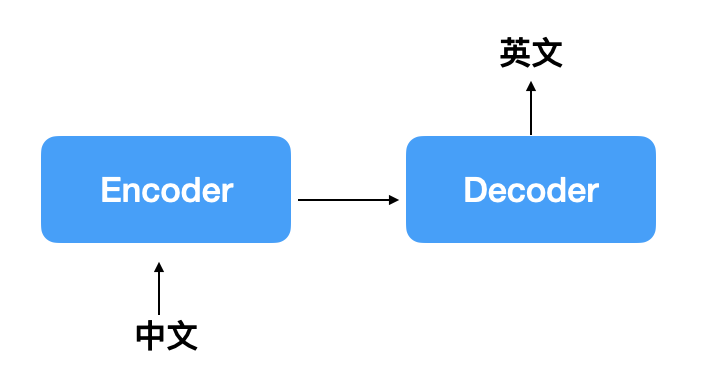
通常encoder可以是CNN或RNN,如果是CNN通常會是看圖說故事的任務,如果是RNN有可能是機器翻譯、摘要提取等,這裡列出我之前在網路上到的任務[1]:
二. 注意力機制
但如果只是一般的Seq2Seq 模型,其實產生的效果有限,當輸入資訊過長時,會lost掉一些訊息,為了解決這樣的問題,發展了注意力的機制。
注意力機制其實就是讓神經網路在計算時可以了解這個input的單元與哪一個output單元的關係比較相關,愈相關的應該要在輸出這個單元時多參考這個input,以圖片舉例來說,下圖白點的地方就是注意力較大的地方,像左上一現在注意力在動物上面時,可以準確輸出動物這個特徵,圖片來源如[2]:
又以機器翻譯為例,'我'應該會有較多的注意力放在'I'這個單詞上,'有'應該會有較多的注意力放在'had'這個單詞上:
這樣可以讓seq2seq的model更能知道哪些output可以參考input的哪些資訊,而Bahdanau 和 Bengio 在2014年也確實發表了一篇基於注意力機制的機器翻譯的paper: “Neural Machine Translation by Jointly Learning to Align and Translate”,效果確實有明顯的提升
今天概略說明了seq2seq的模型與為何有注意力機制,明天會開始介紹transformer與bert的核心: self-attention
參考資訊
[1] http://zake7749.github.io/2017/09/28/Sequence-to-Sequence-tutorial/
[2] https://zhuanlan.zhihu.com/p/31547842

