繼續來討論語意相似度,今天我們將深入探討如何實現 word embedding 。也就是說,我們要將單詞轉為向量(維度可自行決定),並且確保意義相仿的單詞在經過向量表示之後也會互相靠近,而相反使用情境天差地遠的單詞再向量化之後則會有較遠的距離。
在 word embeddings 模型學習的過程中一般並不會提供已經標註好類別的資料,因此被認為屬於非監督式學習(unsupervised learning)的範疇。Word2vec 是用來生成 word embeddings 最常見的一類演算法,藉由類神經網絡作為架構來學習語料庫中單詞的意義關聯性。 根據分佈假說,經常共同出現在上下文的字詞意義上也會較為接近,Word2vec 會將它們的詞向量分成同一類的詞群組( word clusters )。同一集群內的向量彼此靠近,隸屬不同集群的向量則彼此相距較遠。根據訓練資料的設計,Word2vec可分為連續詞袋模型(continuous bag-of-words, CBoW)以及跳躍式模型(skip-gram model, SG)兩種設計架構。
Word2vec 將意義相近的單詞被分類在同一集群:
圖片來源:TowardsDataScience
我們先建立一個僅包含四句短文的小型語料庫,並且建立其詞彙表:
# Create our text corpus of 4 sentences
doc_1 = "he is a king"
doc_2 = "she is a queen"
doc_3 = "he is a man"
doc_4 = "she is a woman"
simple_corpus = [doc_1, doc_2, doc_3, doc_4]
# Build its vocabulary of unique words (fea)
joined_docs = ' '.join(simple_corpus)
tokens = joined_docs.split()
vocab = dict()
index = 0
for token in tokens:
# leave the words that already exist in vocab
if token in vocab:
continue
else:
vocab[token] = index
index += 1
print(vocab) # {'he': 0, 'is': 1, 'a': 2, 'king': 3, 'she': 4, 'queen': 5, 'man': 6, 'woman': 7}
我們得到了詞彙表總共有8個相異單詞,以及各個單詞的編號。
第一種模型的設計架構為 continuous bag-of-words (CBoW) ,其將語料庫中的每個單詞當作 target word ,並且藉由上下文( context words )來預測 target word。這個動作藉由指定好長度的 sliding window 掃遍整個語料庫來完成,以建立訓練資料集。訓練資料集是由特徵與標籤成對所構成,每一筆資料則為(context word, target word)。
CBoW 模型觀察上下文來預測中間的單詞:
藉由sliding window遍歷語料庫中的每個單詞以建立訓練資料:
圖片來源:Practical Natural Language Processing by Sowmya Vajjala et al.
現在,指定 context length k 為2,也就是上下文的採計範圍,此時window size=2k+1 即為5。接著我們以 CBoW 演算法建立訓練資料集:
# Build a CBoW (contex, target) generator
from sklearn.feature_extraction.text import CountVectorizer
# set context_length
context_length = 2
# function to get cbows
def get_cbow_datapairs(tokens, context_length):
cbows = list()
for i, target in enumerate(tokens):
if i < context_length:
pass
elif i < len(tokens) - context_length:
context = tokens[i - context_length : i] + tokens[i + 1 : i + context_length + 1]
vectoriser = CountVectorizer()
vectoriser.fit_transform(context)
context_no_order = vectoriser.get_feature_names()
cbows.append((context_no_order, target))
return cbows
# generate data pairs
cbows = get_cbow_datapairs(tokens, context_length)
# prints out dataset
for cbow in cbows:
print("Context: {} -> Target: {}".format(cbow[0], cbow[1]))

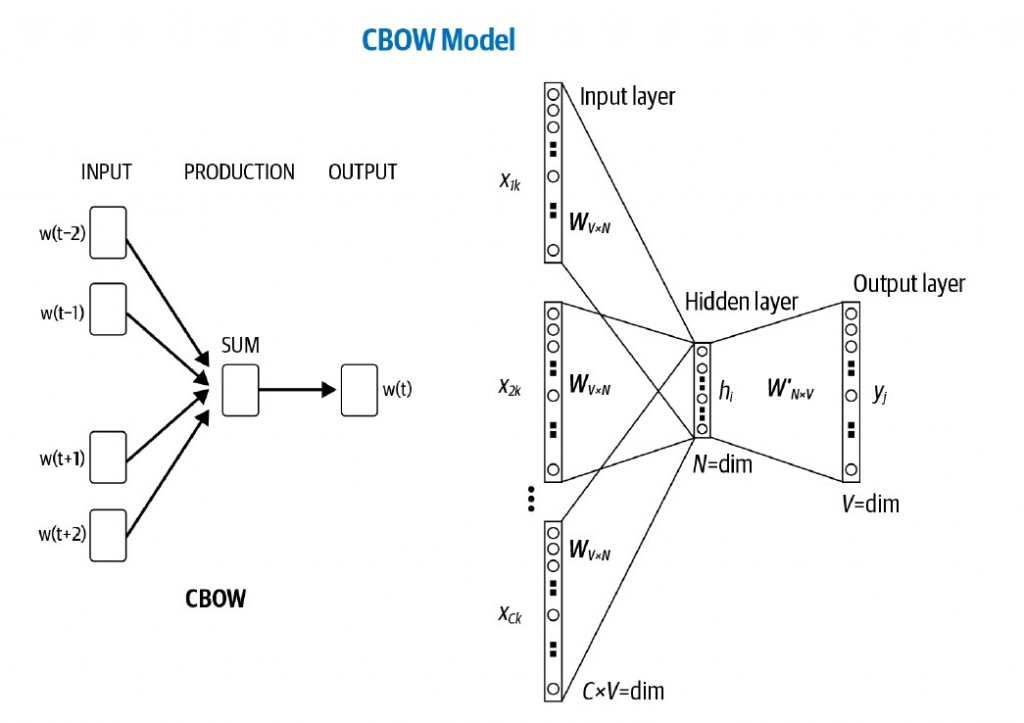
接下來就是建構神經網絡的時刻了! Word2vec 的神經網絡並不深,其僅有一個隱藏層和一個輸出層,是一種淺層神經網絡(shallow neural network)。輸入層節點的數量是由詞彙數量所決定(在我們的例子中 V=8),而我們可以根據要表示向量的維度來指定隱藏層的節點數(例如N=2就是將單詞表示為二維平面向量(x,y)),而輸出層的節點數則也是詞彙數量V(用意是將上下文單詞劃歸其target word的類別,而我們洽有V個target words)。
Context words 先是根據其在詞彙表裡的順序編號,進行one-hot編碼為V維向量,加總之後再輸入神經網絡,因此context words 的順序並不重要。
CBoW神經網路的結構:
圖片來源:Practical Natural Language Processing by Sowmya Vajjala et al.
# Build the CBOW model architecture
import tensorflow.keras.backend as K
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, Lambda
V = len(vocab)
N = 2
cbow = Sequential(name = "our CBoW model")
# input layer of 8 nodes
cbow.add(Embedding(input_dim = V, output_dim = N, input_length = context_length * 2))
# single hidden layer of 2 nodes
cbow.add(Lambda(lambda x: K.mean(x, axis = 1), output_shape = (N, )))
# output layer of again 8 nodes, "softmax" is used for classification
cbow.add(Dense(V, activation = "softmax"))
cbow.compile(loss = "categorical_crossentropy", optimizer = "adam")
# view model summary
print(cbow.summary())
檢視一下我們的模型結構: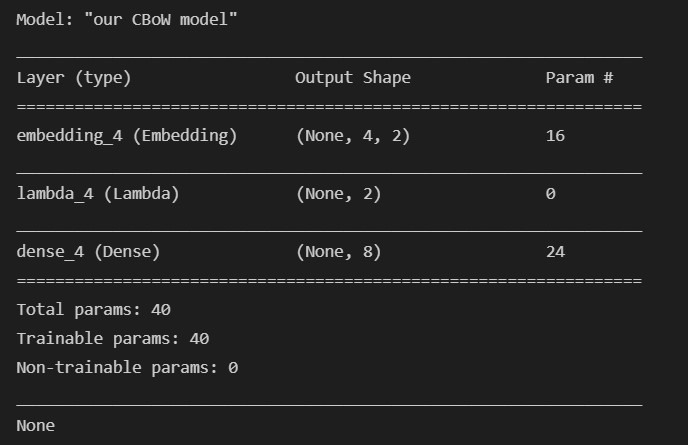
又即將到了午夜時分,今天本來想要一口氣講完Skip-Gram結構看來也只能留到明天了。明天我們延續CBoW的實作,並讓剛建立好的CBoW network進行單詞相似度的學習,產生屬於自己的二維 word embeddings 。明天再會,小夥伴們!




 iThome鐵人賽
iThome鐵人賽