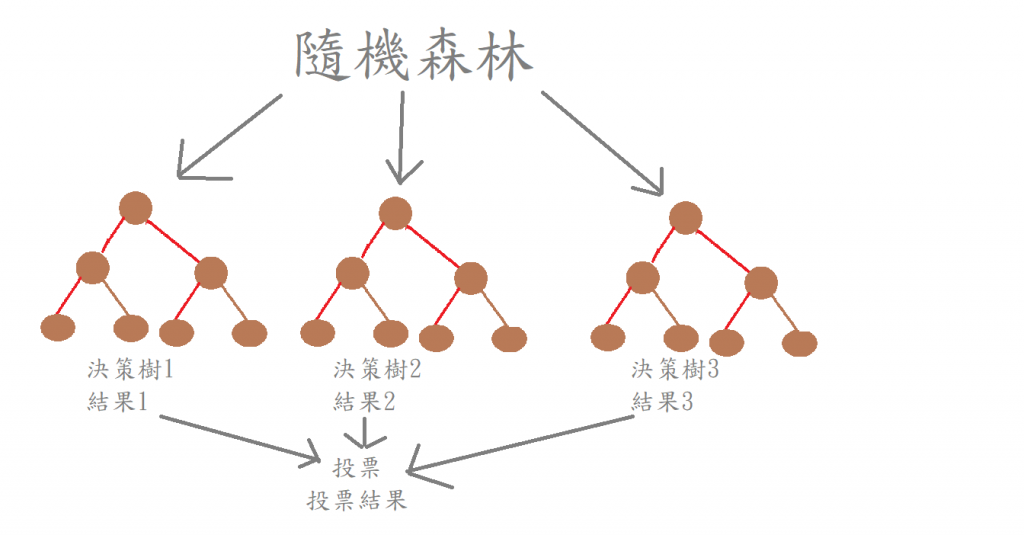
隨機決策樹為隨機生成許多決策樹,
利用取袋法來取出選中的決策樹,
而每棵樹的都具有執行結果,
每棵樹依據執行結果來投票,
得票最高的就是最終輸出結果。
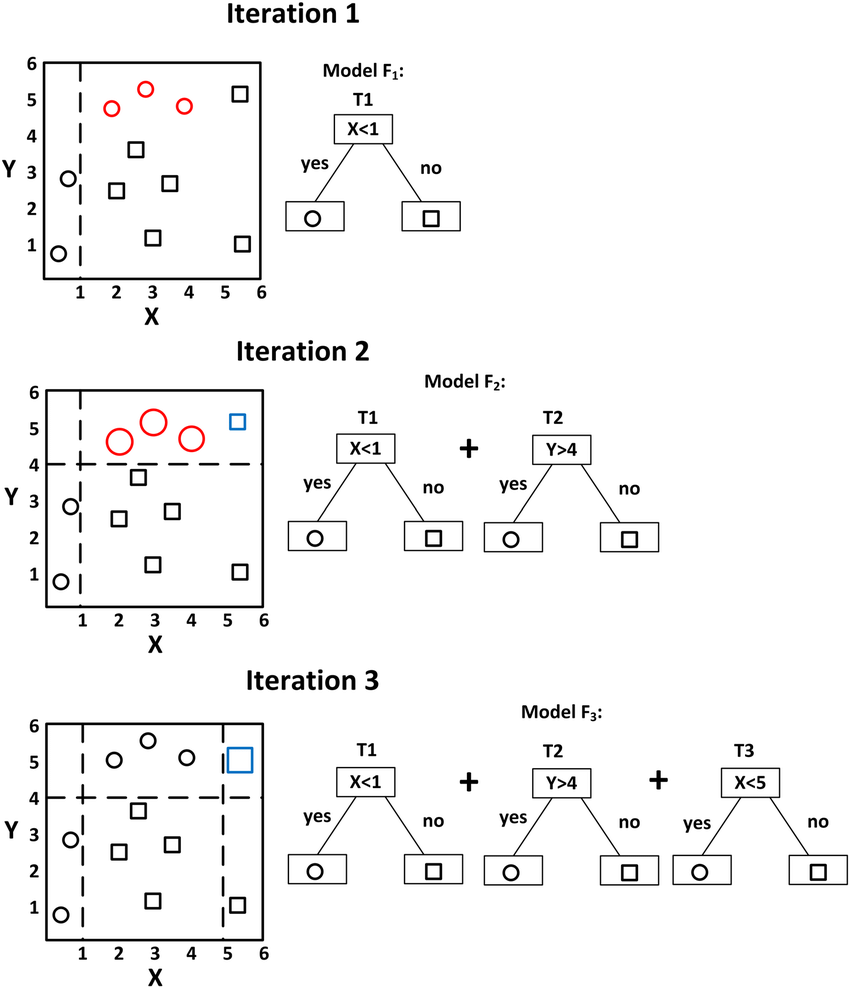
而本篇使用的是Gradient Boosting,
利用上一顆樹的執行結果,
將錯誤劃分的個體資訊加以優化,
加強劃分的邊界。
可以搜尋 Gradient Boosted進行參考。
決策樹森林可以解決分類、迴歸及排名的問題,
今天來介紹解決排名的使用方式。
參考攻略colab:
https://www.tensorflow.org/decision_forests/tutorials/beginner_colab
colab中上部分有分類及迴歸的使用方法,
而我們從訓練排名模型的章節開始:
安裝套件
wurlitzer是幫助把訓練時的日誌資訊詳細的印出,
自己創建模型時,不一定需要這個功能:
載入套件
下載排名資料的LETOR3資料集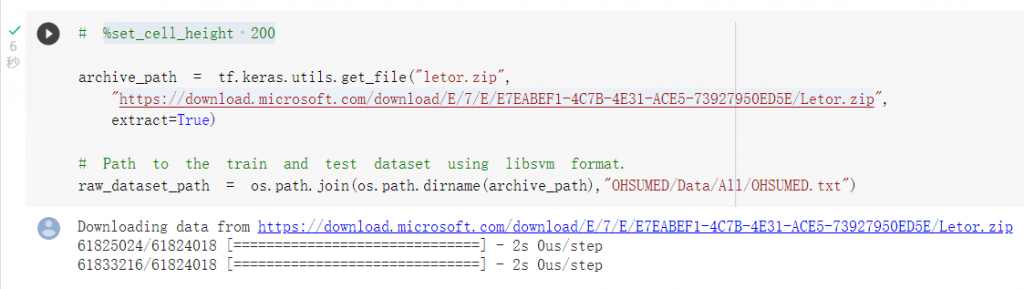
進行清洗並查看資料結構: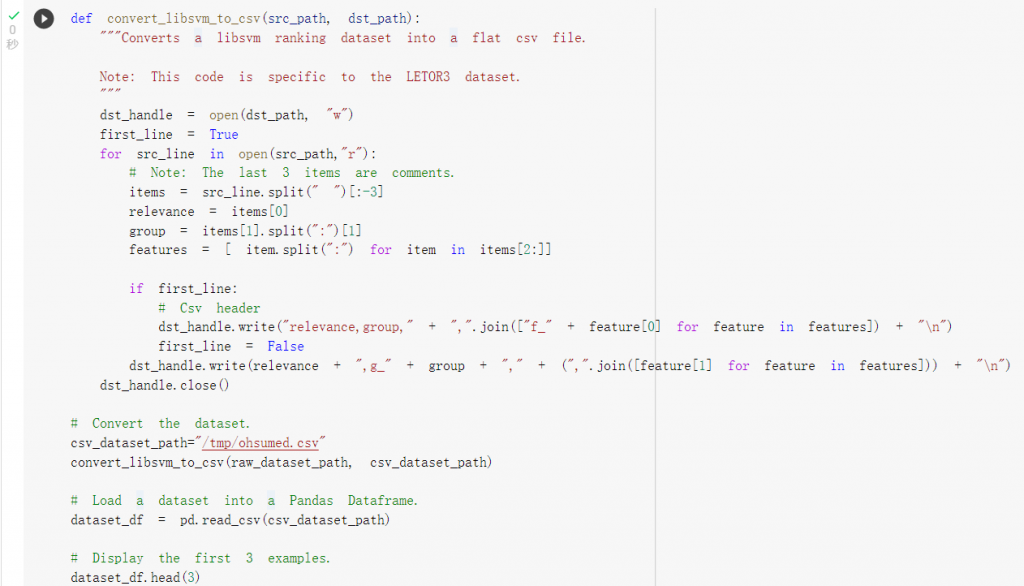
可以發現relevance為標籤(label),
0代表越不相關或是越不重要,
而數字越大代表越相關或是重要。
切分訓練集及測試集: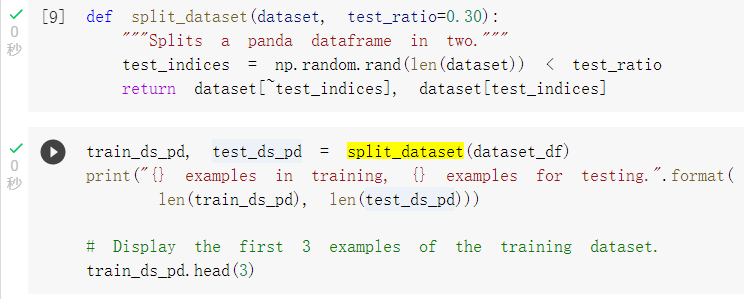
載入決策樹資料集並且進行訓練: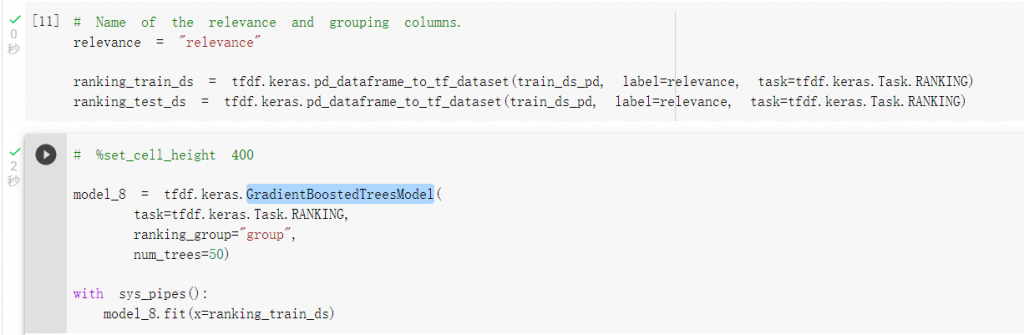
那最後我們可以對照預測結果來劃分階級: