第二個範例將以心血管疾病的Dataset進行說明如何執行training、tracking與serving. 這個範例來源為這裡.
第Day1 的示意圖表示如下:
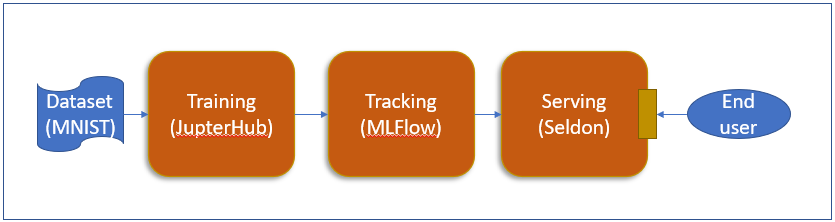
範例程式可以從github下載
在cardio_train.csv裡面的欄位包含:
訓練完成後, 執行推論時,使用者需要提供age、gender、height、weight、ap_hi、ap_lo、cholesterol、gluc、smoke、alco、active資料, 系統將會回傳該人員罹患心血管疾病的機率.
執行訓練時會使用XGBoost(eXtreme Gradient Boosting)進行模型的訓練, 關於XGBoost的介紹可以參考wikipedia
會使用這個範例進行說明的原因下如:
下一篇我們就來說明這份推估心血管疾病機率的notebook內容
https://www.kaggle.com/sulianova/cardiovascular-disease-dataset
https://zh.wikipedia.org/wiki/XGBoost

