
說到tinyML不得不說起「TinyML Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers」一書的作者Pete Warden,他應該是最早將這個概念整理成書的作者(2020/1/7 初版),並且在Youtube上也有多段影音教學影片(如文末參考連結【TinyML Playlist】)。目前這本書也有中文譯本在台發售,碁峯於2020/7/31出版,書名「tinyML TensorFlow Lite機器學習 應用Arduino與低耗電微控制器」,如Fig. 12-1所示。

Fig. 12-1 TinyML經典入門書及作者Pete Warden。(OmniXRI整理繪製, 2021/9/26)
「TinyML」中文版書中對兩位作者的介紹:
Pete Warden 是行動及嵌入式TensorFlow的技術主管,也是TensorFlow團隊的創始成員之一。他曾經是Jetpac的CTO和創始人,該公司在2014年被Google收購。
Daniel Situnayake 是Google的首席開發布道師,並且協助運作tinyML聚會小組。他也是Tiny Farms的共同創辦人,Tiny Farms是美國第一家大規模自動生產昆蟲蛋白的公司。
相信可能很多人第一次接觸tinyML應該都是跟著這本書來實作和練習,但說實在的,步驟有點多,有很多開發環境要設置,所以對於新手會有些吃力,因為除了AI部份外,還有MCU部份要處理。好在AI的世界進步速度頗快,才過了一年多,就有了不少改進,簡化了不少。接下來就讓我們跟著Google官網「TensorFlow Lite for Microcontrollers」(以下簡稱TFLM)的說明來實際操練一下。
什麼是TFLM呢?一般大家在開發深度學習模型時多半會使用Google TensorFlow框架,但到了手機或單板微電腦(如Arm Cortex-A, Cortex-R或樹莓派Cortex-A53/A57等)時代,這樣的框架太大塞不進這些系統中,於是Google又推出TensorFlow Lite,它不僅更短小精悍,同時還提供的模型優化工作,使得在推論準確率只損失數個百分點甚至幾乎沒有損失的情況下,讓模型縮小十倍以上,不僅更容易塞進這些開發板,同時加快了推論速度。不幸地是,當遇到像MCU(Cortex-M)等級的開發板時,又遇到塞不進的問題,所以Google才會再推出TensorFlow Lite for Microcontroller。表面上名字很像Lite,但實質上為了牽就MCU的開發架構,因此本質上有很大不同,無法直接取代。原則上這些都是開源碼,有興趣研究原始碼的朋友可參考文末參考連結【TFLM Github開源碼】。另外目前TFLM可支援的開發板可參考[Day 03] tinyML開發板介紹的說明。
接下來就跟著Google TFLM的「Hello World」來建立基本操作觀念。這個範例主要分成兩個部份,如下所示。
首先點擊Google提供的Colab範例程式,免下載,可直接運行,Jupyter Notebook操作環境,說明文字和程式一起存在,方便學習,只需在每個程式欄位左上角按下黑色箭頭(或者點想執行的欄位按Ctrl + Enter亦可)即可單步執行,但切記要按照順序把每個步驟都執行完,不能跳過任何一步驟。由於開啟後會看到先前運行結果都被保留在執行結果欄位,為了更清楚看到所有動作,可執行主選單的[編輯]─[清除所有輸出欄位],將所有輸出欄位清除。
首先說明這個「Hello World」程式主要想展示如何將一個TensorFlow建立好的模型轉換到TFLM,為了方便說明,並沒有使用現成常用的資料集,而是以正弦波加亂數方式產生一個資料集,然後訓練出一個模型(正弦波函數),使得輸入X位置就能推論出Y位置。
接下來就快速摘要一下整個程式在做什麼?程式部份請參考原始程式,這裡僅作重點摘要及補充說明,方便大家更容易理解。程式運作後產生的相關圖表可參考Fig. 12-2。
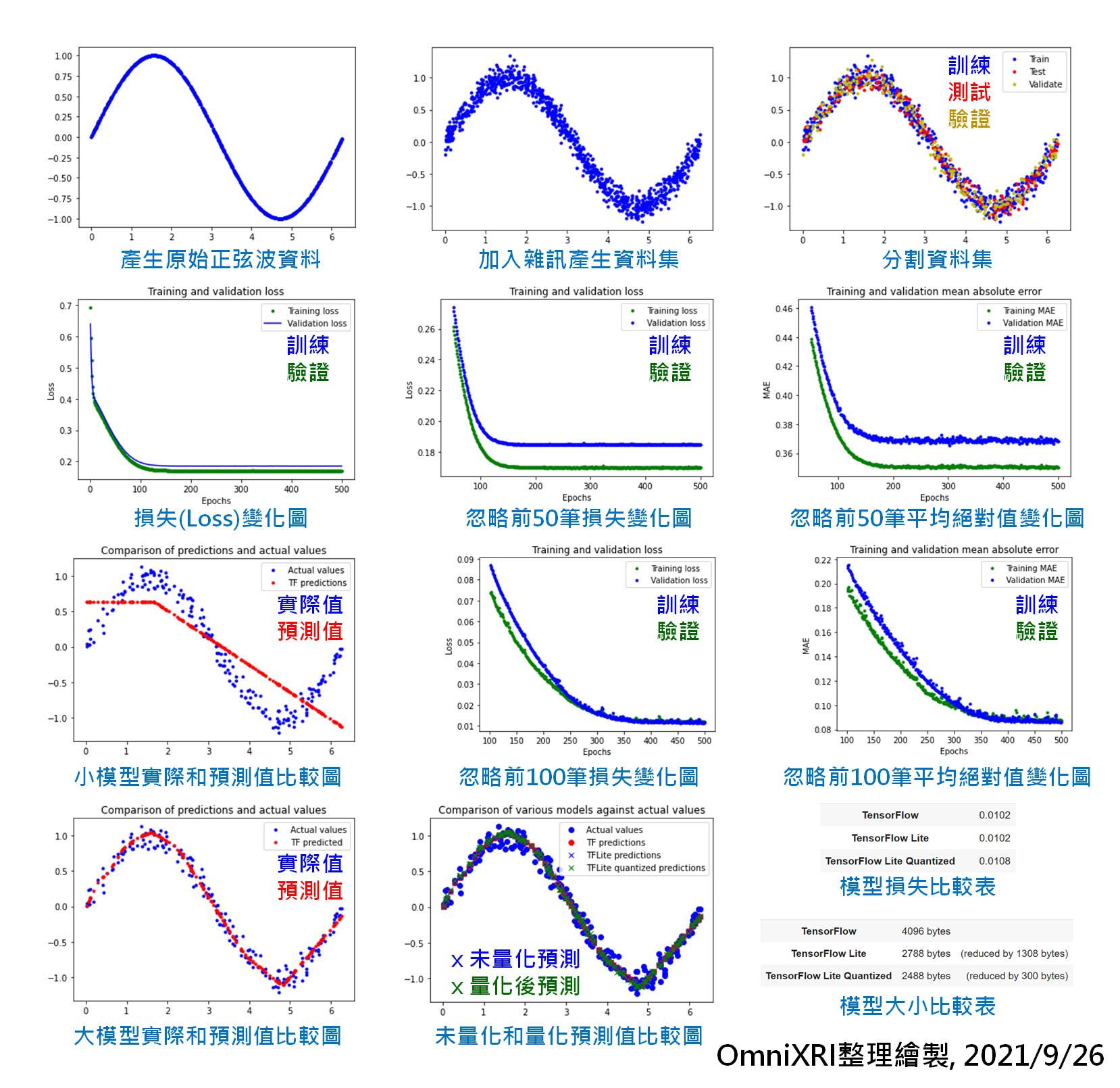
Fig. 12-2 TensorFlow Lite for Microcontroller Hello Wolrd範例相關圖示。(OmniXRI整理製作, 2021/9/26)
參考連結
Google TensorFlow Lite for Microcontrollers 中文學習指南
Pete Warden Youtube, TinyML Book Screencasts Playlist 影片清單
TensorFlow Lite for Microcontrollers Github 開源碼
TFLM Get started with microcontrollers, The Hello World example
Experiments with Google = TensorFlow Lite for Microcontrollers 案例分享
老師,一般作模型的過程中,感覺訓練資料的誤差都會比 validation or testing data error 小,不知道個 sine wave 做出來的跟我們以前的想法與經驗不一樣,老師有 idea 嗎?
先謝謝老師了
訓練過程訓練集誤差比驗證集好或訓練完後比測試集好,這是很正常的,因為訓練時你正利用給的已標註標籤在逼近,而驗證集和訓練集的並不一定會在訓練集的變動範圍中。這個SINE WAVE的案例是非常陽春的,若像[Day 26, 27]提及的影像分類時,這個問題就會更明顯。
所以有效分配資料集作訓練、驗證和測試,又是另一個AI工程師的挑戰。
