資料增強(Data Augmentation),是一個當今天資料集樣本不多時,透過調整亮度、剪裁、角度等手法來增加多樣性的好方法,Tensorflow 的 tf.image.random_* API 提供了不少資料增強的方法,讓我們在訓練模型時可以使用。
這次我簡單介紹幾個 API 並看看,這幾種 Augmentation 方式會產生什麼樣的效果。
def aug_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
flip_image = tf.image.random_flip_left_right(image)
flip_image = tf.image.random_flip_up_down(flip_image)
brt_img = tf.image.random_brightness(flip_image, 70)
brt_img = tf.clip_by_value(brt_img, clip_value_min=0.0, clip_value_max=255.0)
sat_img = tf.image.random_saturation(brt_img, 0.7, 1.5)
sat_img = tf.clip_by_value(sat_img, clip_value_min=0.0, clip_value_max=255.0)
cts_img = tf.image.random_contrast(sat_img, 0.6, 1.4)
cts_img = tf.clip_by_value(cts_img, clip_value_min=0.0, clip_value_max=255.0)
return image, flip_image, brt_img, sat_img, cts_img
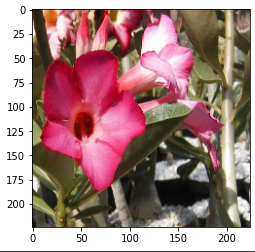
random_flip:
就是隨機上下左右顛倒,像這次的資料集是花的辨識,花本身就沒有一定的方向性,就很適合拿來使用,但如果今天的資料集是貓狗二分類,那麼只需要左右顛倒即可。
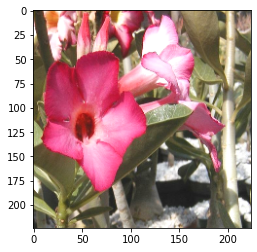
random_brightness:
提供一個 max_delta 的值,會將圖片每個像數乘上這個的變化量,要注意的是,如果今天你的圖片已經先 normalize 到 [0.0, 1.0] 之間了,那這個值可以指設0.1就會產生很大的亮度差異,但如果今天圖片的範圍是[0, 255],那就需要設定比如70這樣大的數值去產生亮度差異。
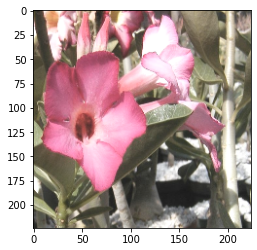
random_saturation:
提供上限 upper 和下限 lower 來決定圖片的飽和度。
random_contrast:
和 random_saturation 雷同,對圖片隨機的對比度。
我們印出實際的圖片變化
原圖:
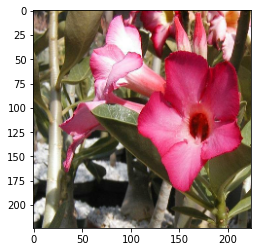
隨機顛倒:
隨機亮度:
隨機飽和度:
隨機對比度:
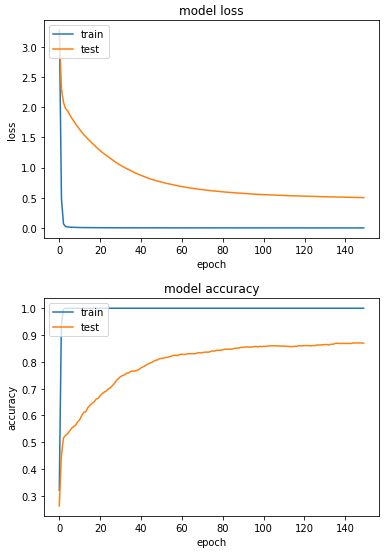
檢查完圖片都該有的變化後,我們先跑一次不做任何資料增強的訓練:
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
最佳成績:
loss: 5.2436e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.5029 - val_sparse_categorical_accuracy: 0.8706
接下來,跑一下套用資料增強後的模型:
def aug_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.random_flip_left_right(image)
image = tf.image.random_flip_up_down(image)
image = tf.image.resize(image, (224,224))
image = tf.image.random_brightness(image, 70)
image = tf.image.random_saturation(image, 0.7, 1.5)
image = tf.image.random_contrast(image, 0.6, 1.4)
image = tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=255.0)
return image / 255., label
ds_train = train_split.map(
aug_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 5.2807e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.6019 - val_sparse_categorical_accuracy: 0.8422
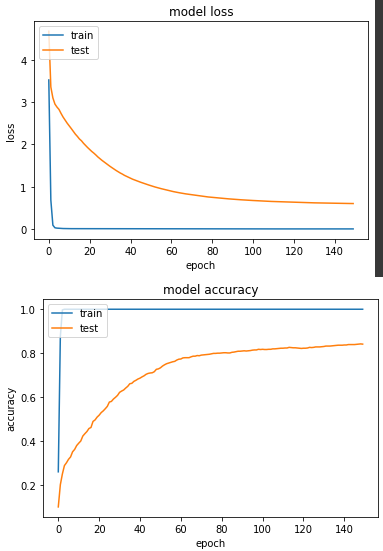
這次實驗結果顯示,最終的成績並沒有第一個模型好,相比準確度低了3%,但也不致於差到哪裡去,資料增強仍然是一個我實務上常使用的方法。

