通常在 model.compile() 時,我們要指定這個訓練應該要使用哪種 loss 來計算,前面幾天我們比較了各種 cross entropy 的使用方式,今天我們來講一下模型訓練新手容易忽略的 from_logits 。
什麼是 logits ?
根據維基百科,logit 在數學上是一個將0~100%映射到負無限大到正無限大的函示,舉例來說,50%就是代表0,不到50%在 logit 上都是負的,可以到負無限大,50%以上的 logit 範圍就是大於0到無限大。
而我們再計算 loss 值時,label 通常都是0與1,我們必須經過 sigmoid 或 softmax 將 logit 的範圍縮到同樣也是0和1之間,這麼一來計算出的 loss 才有意義,所以一般我們會把在最後經過 softmax 或 sigmoid 的前一個 tensor 稱作 logit。
tf.keras.losses.* 系列提供的 API 中,很多都提供了 from_logits 這個參數讓你直接接 logit 層,預設 from_logits=False,我們來看看使用 from_logits=False 來訓練的結果。
實驗一:在oxford_flowers102用 softmax 跑 SparseCategoricalCrossentropy
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
net = tf.keras.layers.Softmax()(net) # from_logits=False時,多加這一層
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 0.0056 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.6840 - val_sparse_categorical_accuracy: 0.8608
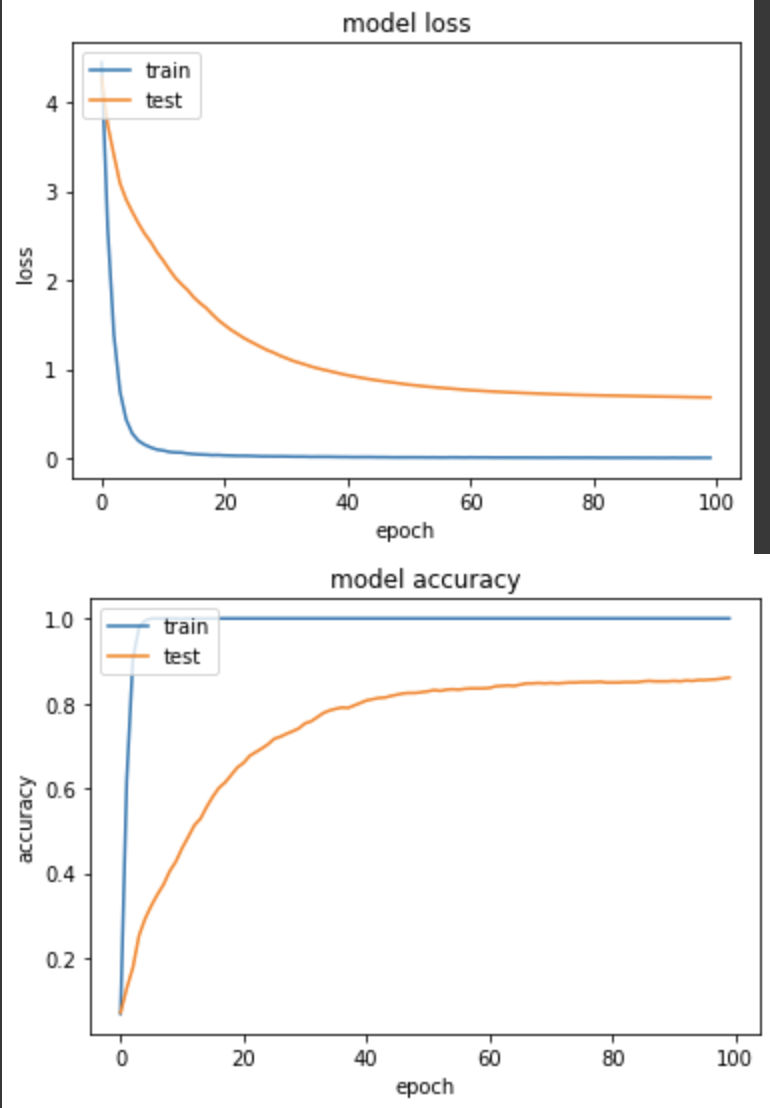
沒什麼問題,和day10的實驗一結果差不多。
實驗二,錯誤示範,忘記加 softmax
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
# net = tf.keras.layers.Softmax()(net) # from_logits=False,忘記多加這一層
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=10,
validation_data=ds_test,
verbose=True)
產出:
loss: 5.4419 - sparse_categorical_accuracy: 0.0098 - val_loss: 6.3155 - val_sparse_categorical_accuracy: 0.0098
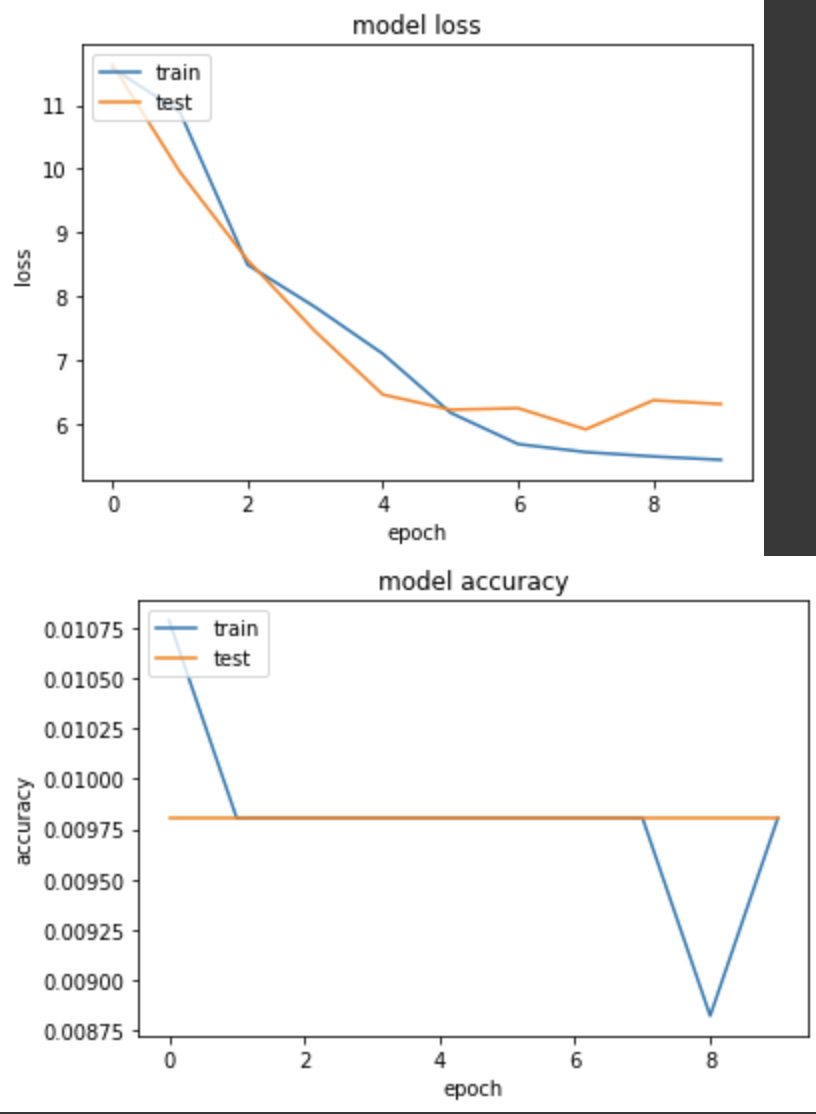
實驗三,在cats_vs_dogs用 sigmod 跑 BinaryCrossentropy
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(1)(net) # dense node = 1
net = tf.keras.activations.sigmoid(net) # from_logits=False時,多加這一層
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.BinaryAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 0.0051 - binary_accuracy: 0.9986 - val_loss: 0.0327 - val_binary_accuracy: 0.9895
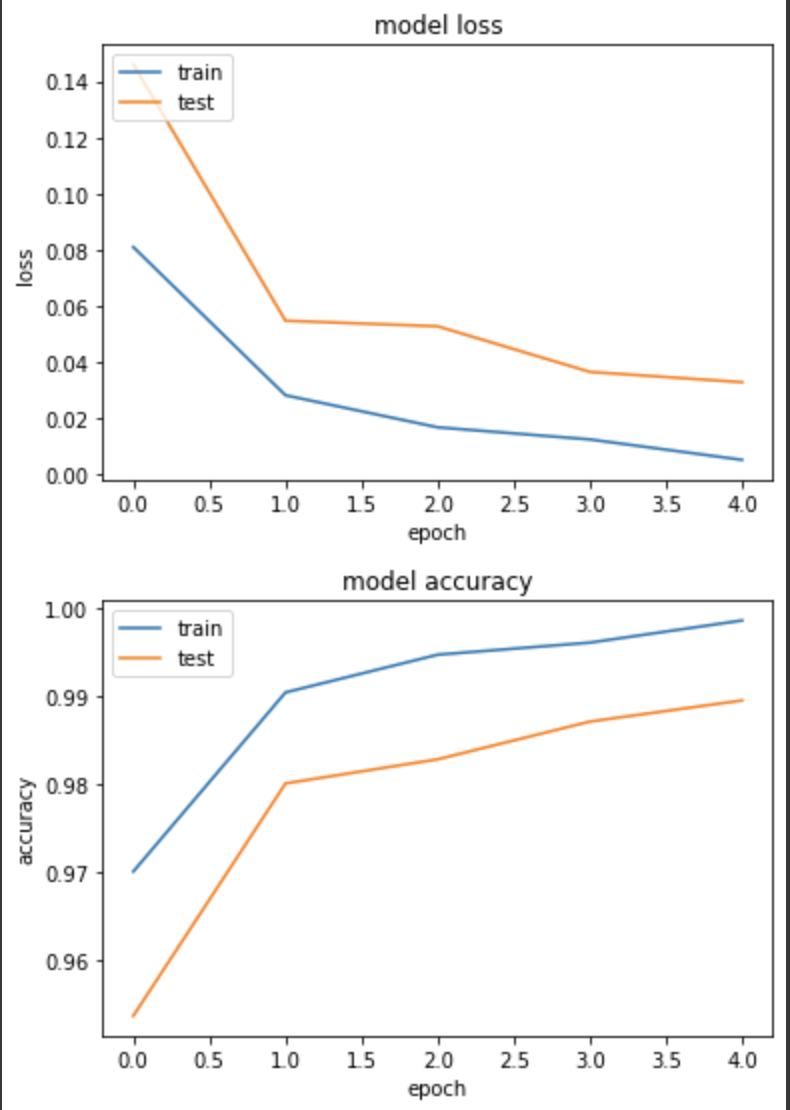
和day11的實驗二差不多,準確度都高達98.9%
實驗四:錯誤示範,忘記加 sigmoid
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(1)(net) # dense node = 1
# net = tf.keras.activations.sigmoid(net) # from_logits=False時,忘記加這一層
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=False),
metrics=[tf.keras.metrics.BinaryAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 7.6577 - binary_accuracy: 0.5036 - val_loss: 7.0626 - val_binary_accuracy: 0.5156
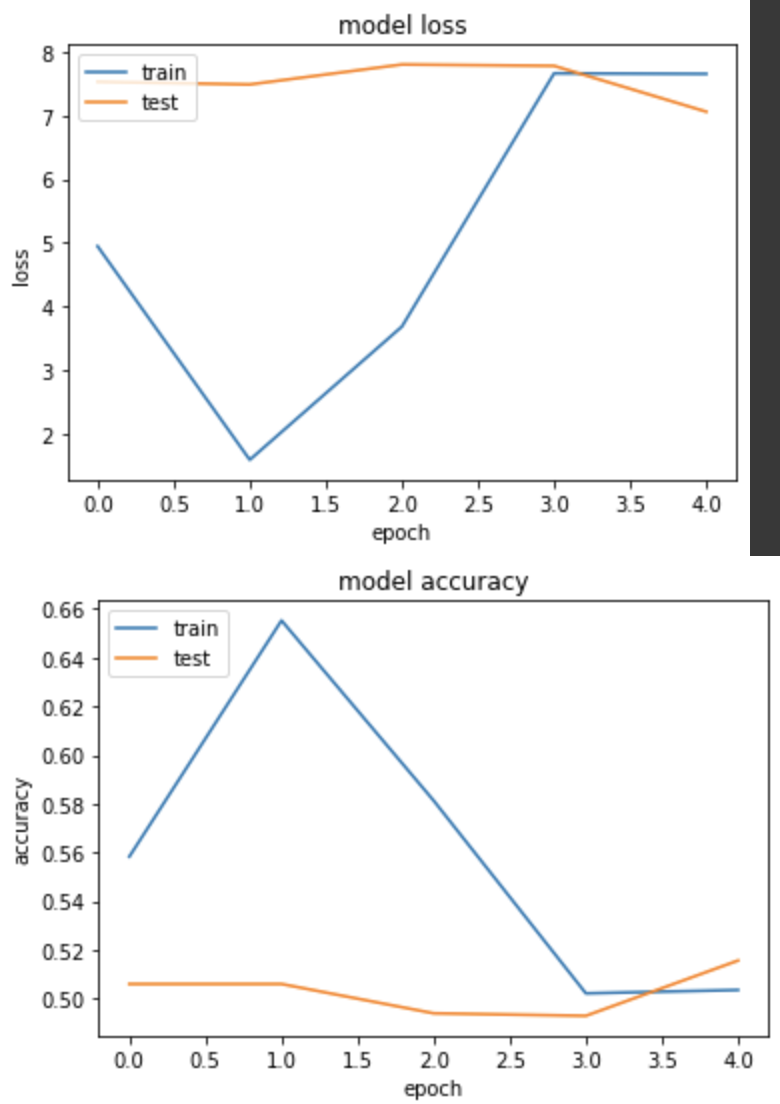
以上結果,可以得知在計算 loss 值時,如果不透過 softmax 或 sigmoid 將 logit 縮限範圍會導致與 label 的值計算錯誤,從而讓模型學不到東西,因此在建構模型時,請務必檢查這個地方是否有遺漏!

