圖片標準化 Image Normalization 不做可以嗎?小實驗實測差別
一般我們在處理大部分的機器學習問題時,我們都會將輸入的資料特徵做 Normalization,將範圍縮小到0的附近後在進行訓練,而這個再丟給模型推論之前所做動作稱之為資料預處理,而預處理的方式又有很多種,像是減去平均值除上標準差等方式。
通常大家在學習上聽到的預處理是為了讓模型收斂速度加快,而我們今天就來做個小實驗比較看看這兩者的差別。
實驗一:有做 Normalization
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image / 255., label. # Normalization 到 [0,+1]
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 3.6706e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4833 - val_sparse_categorical_accuracy: 0.8647
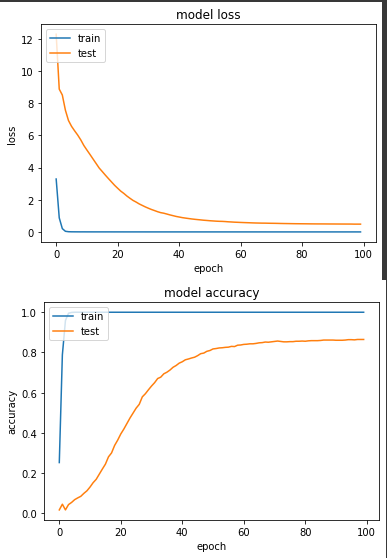
loss值落在 0.4833,準確度落在86.5%
實驗二:不做 Normalization,使用原圖片輸入數值範圍 [0, 255]。
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image, label # 不除255.
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出:
loss: 3.7623e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4478 - val_sparse_categorical_accuracy: 0.8873
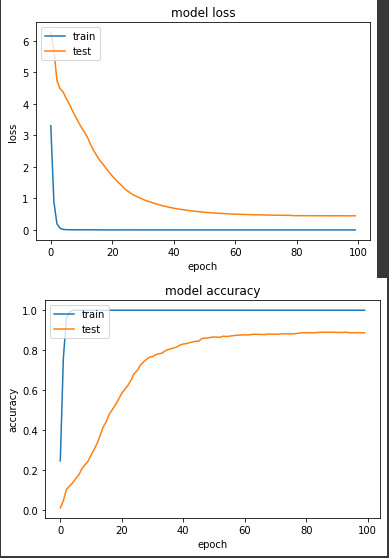
結果有些出乎我意料,loss 值0.4478,準確度88.7%,整體結果比實驗一好,而且實驗一在第50個 epoch 達到80%準確度,但實驗二更快,在第36個 epoch 就到達了80%,實驗一並沒有收斂比較快。
雖然這次實驗結果是不做 Normalization 的成績好一些,但我還是不太建議略過 Normalization ,之所以會有這樣的結果,我猜想可能是我的模型用了 Batch Normalization 來解決數值的差異,如果數值的差異很大的話,其實蠻容易訓練到一半時,loss變成nan 的狀況(gradient exploding),有關這種狀況,後面我會再獨立介紹。

