目前為止Glue的三個工具,可以依使用者的開發習慣與技術背景來選用,而AWS是以客戶為導向的公司,對於越來越多跨領域的人才都要希望能夠善加應用手中資料的需求下,AWS也應運而生了另一個服務—Glue Data Brew,讓使用者只要帶著資料來,就可以在不需要編撰任何程式碼的情況下,利用AWS積年累月資料經驗所提供建立的250個內建ETL範本,將資料清洗成符合自己使用需求的資料集,方便接下來的分析與機器學習建模使用。
基本元件介紹:
Project專案:進入服務業面可以在右方先建立專案,建立時選定Dataset,選擇Recipe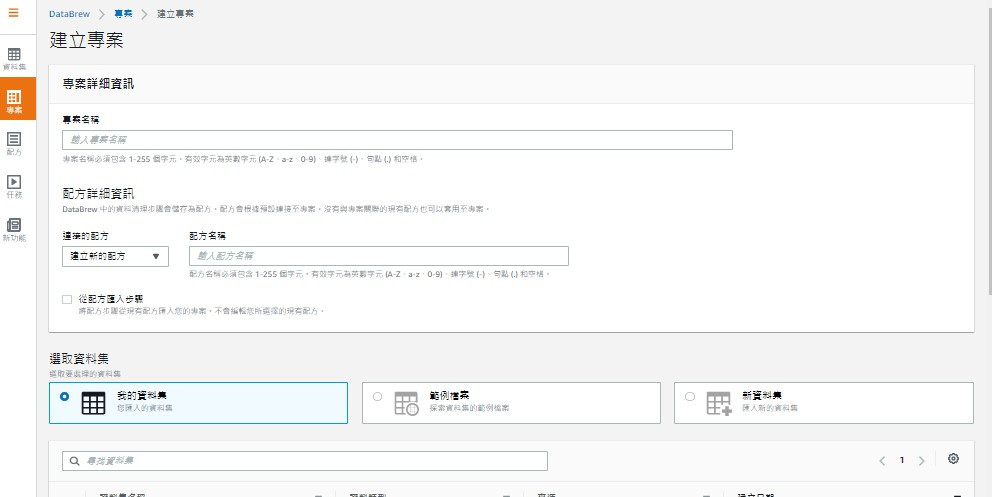
或是直接選擇建立內建的範本專案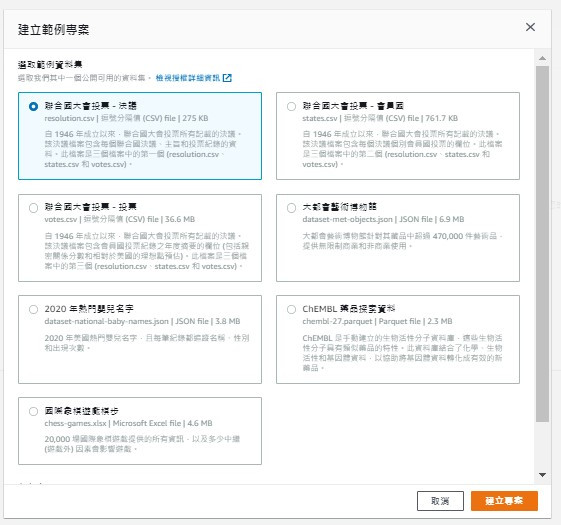
記得選用的role需要擁有相關資源的權限(例如S3)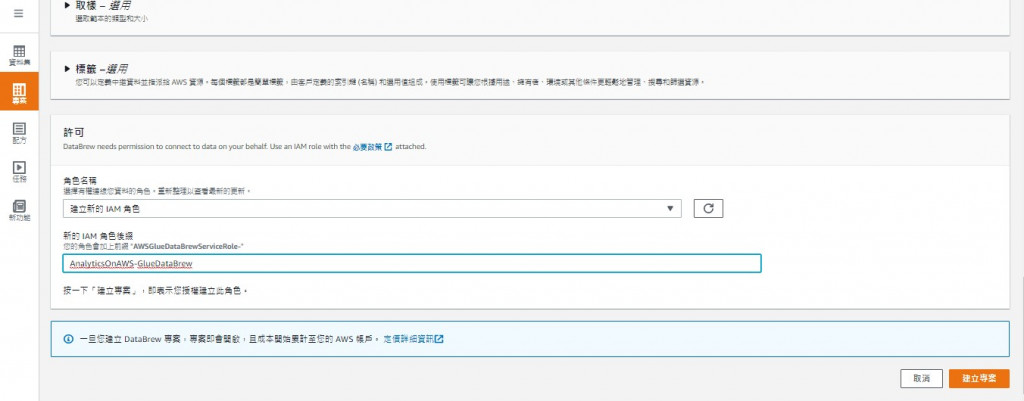
Dataset:與data catalog一樣並沒有實際存有資料本身,而是記錄著metadata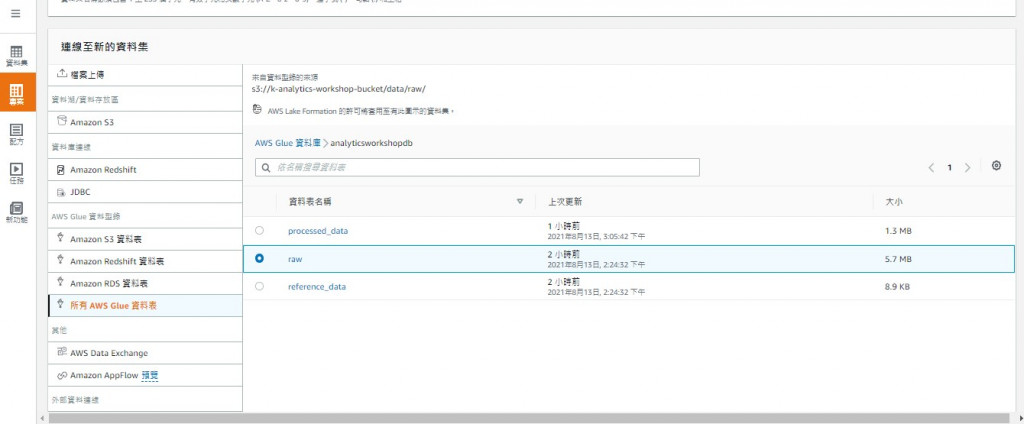
也可以從本地上傳
Recipe:是一步步資料處理流程的集合,如果不使用範本也可以上傳自己編寫的版本,或是修改範本讓資料能清洗成更符合自己所需的樣子。注意上傳檔案須是JSON檔。
Job:Recipe的執行實例,可以按需執行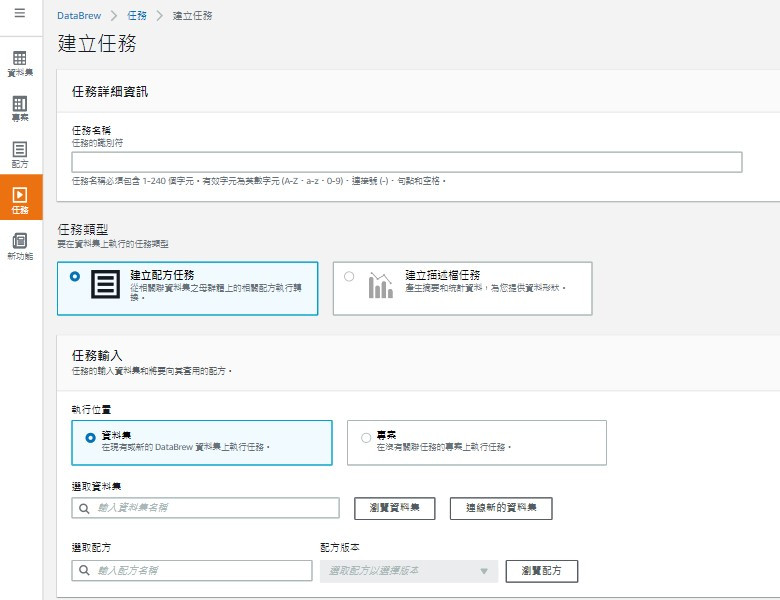
兩個值得一提的功能是:
Data lineage:視覺化呈現資料流,可以追蹤資料處理的狀態進度
Data profile:提供基本資料輪廓的敘述統計資訊,類似pandas的describe功能
花了許多篇幅介紹資料處理工具,因為資料清洗是個非常關鍵卻又耗時的過程,資料清洗的程度與否直接影響著分析結果,所以常常是一個資料分析系統中的痛點,不只是Glue Data Brew,市面上也有許多其它為了解決這個問題而產生的工具,例如Informatica、Tableau Prep等
但Glue所適用的資料量大約1TB左右,如果要處理更大量(可能10TB以上)的資料,就需要另一個更強壯的服務 — Amazon EMR。明天做介紹。

