Google在2015年時發表了一篇論文,
提出了FaceNet網路架構。
而其實在前面幾天實作人臉辨識時,也都或多或少有用到FaceNet:
而FaceNet最主要的重點有兩個:
使用FaceNet預訓練的模型可以很好的辨識人臉,
這個我們已經在前面學習到了。
今天,我們要來談談Triplet Loss的做法以及實際如何用。
找Triplet Loss,大多都會出現這張圖: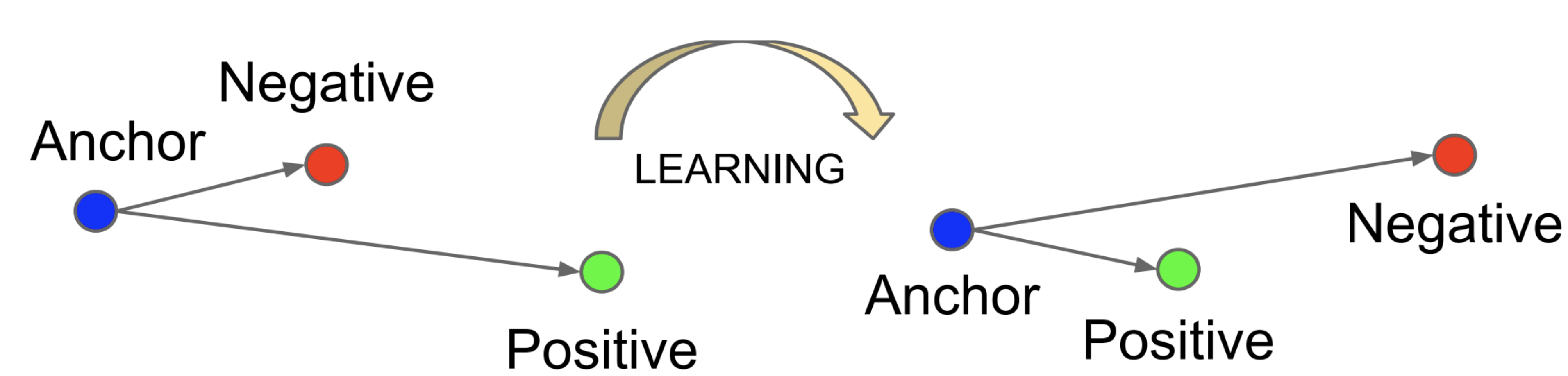
Anchor是當前要訓練的資料,
目的是要將:
Loss是損失函數,也就是模型在"學習"的過程中如何判斷當前的訓練結果是好是壞;
因此Triplet Loss就是要讓模型"學習"如何將相似的資料輸出的特徵相近,而不相似的資料輸出特徵相遠。
作法聽起來很簡單,
但實際上它的"眉角"就在
如何選擇Positive與Negative資料?
如果選擇的資料是"相似資料的特徵已經很近,不相似資料的特徵已經很遠"
滿足Triplet Loss的目標,模型不用訓練,結束。 --- 這是Easy Triplet
選擇"相似資料的特徵都離很遠,不相似資料的特徵都很近"
可能模型訓練到最後很難有不錯的結果。 --- 這是Hard Triplet
凡事過猶不及都不好,
因此出現了一種作法叫做Semi-hard Triplet
到這裡為止還是太抽象了,我們實際舉個例子來說:
大家都吃過「豆」吧?
當我們今天想要學習區分豌豆與荷蘭豆的區別,請看下面的圖片:
如果跟你說Anchor與Positive都是豌豆、Negative是荷蘭豆,
你可能會很直覺的"看到"豌豆與荷蘭豆就是不一樣的東西。
但你會直覺"想到"是什麼不一樣嗎?
.
.
.
.
.
同樣的例子,再來另一個比較:
如果跟你說Anchor與Positive都是豌豆、Negative是荷蘭豆,你的腦袋這時應該會直覺想到:
喔~豌豆的豆仁比較飽滿,而荷蘭豆感覺沒什麼豆仁;豌豆的豆筴好像也比較厚實,荷蘭豆看起來扁扁的
這時候再跟你說中間的那張圖片是你在超市一定會看到的"三色豆"其中一個 -- 青豆仁 (也就是去除豆筴後的豌豆)
荷蘭豆一般都會連豆莢一起直接與其他蔬菜拌炒。
有沒有恍然大悟「喔!我會區分豌豆跟荷蘭豆了!」?
對 --- 上面第二個例子是說明Hard Triplet如何讓人"學習"去想辦法區別兩個不一樣的物體真正的差別。
而第一個例子就是Easy Triplet,你的"眼睛"已經直接告訴你這兩個是不一樣的東西。
今天我們要讓電腦去學習區分也是一樣的道理,
將兩個是一樣的東西,但看起來卻幾乎是不一樣的
以及
兩個不一樣的東西,但看起來很相似
讓電腦去學習特徵,來區別其中的不同。
Google發表的FaceNet就是在這樣的精神下去訓練模型來區別人臉,
也因為Triplet資料的選擇有特別處理,讓這個模型直到現在都還是相當熱門且準確的模型。
最後,
由於Easy Triplet容易學不到東西,
而Hard Triplet困難到學不到東西,
Semi-hard Triplet是折衷作法,
如何挑選,網路上也都有數值分析作法,有興趣一樣可以搜尋看看
就這樣,對我來說FaceNet的重點一次說完囉!


