昨天的內容還可以吸收嗎?
也許有人會問:
這些神經網路模型還有GPU、CUDA什麼的我都不懂,能不能有一個最簡單的方式做即時人臉辨識?
也許Google ML Kit比較適合你
OpenCV除了之前提到的,專門處理影像相關功能之外,
它提供了一系列的接口讓你可以載入各種模型 (只要有辦法轉成OpenCV支援的模型格式)
cv2.dnn.readNet
cv2.dnn.readNetFromCaffe
cv2.dnn.readNetFromONNX
cv2.dnn.readNetFromTorch
cv2.dnn.readNetFromDarknet
cv2.dnn.readNetFromModelOptimizer
cv2.dnn.readNetFromTensorflow
對,基本上想得到的想不到的模型格式它都支援了,
而OpenCV會自動載入模型結構,
你要做的就是給它輸入跟得到輸出而已。
由於今天的目的是用最簡潔的方式來應用人臉偵測
我們只會使用OpenCV來做人臉偵測與人臉辨識的工作,
當然,還是需要有資料。
我們就開始吧!
face_recognition下新增一個檔案opencv_realtime.py
import ntpath
import sys
# resolve module import error in PyCharm
sys.path.append(ntpath.dirname(ntpath.dirname(ntpath.abspath(__file__))))
import argparse
import numpy as np
import os
import time
from urllib.request import urlretrieve
import cv2
from imutils.video import WebcamVideoStream
from imutils.video import FPS
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
from dataset.load_dataset import load_images
from face_detection.opencv_dnns import detect
# 下載模型相關檔案
embedder_model_url = "https://storage.cmusatyalab.org/openface-models/nn4.small2.v1.t7"
embedder_model = "nn4.small2.v1.t7"
if not os.path.exists(embedder_model_url):
urlretrieve(embedder_model_url, embedder_model)
def main():
# 初始化arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", type=str, required=True, help="the input dataset path")
args = vars(ap.parse_args())
# 初始化要使用到的模型
embedder = cv2.dnn.readNetFromTorch(embedder_model)
print("[INFO] loading dataset....")
# 篩選掉張數小於10的人臉
(faces, names) = load_images(args["input"], min_size=10)
print(f"[INFO] {len(faces)} images in dataset")
# 初始化結果
known_embeddings = []
known_names = []
# 建立我們的人臉embeddings資料庫
print("[INFO] serializing embeddings...")
start = time.time()
for (img, name) in zip(faces, names):
rects = detect(img)
for rect in rects:
(x, y, w, h) = rect["box"]
roi = img[y:y + h, x:x + w]
faceBlob = cv2.dnn.blobFromImage(roi, 1.0 / 255, (96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
known_embeddings.append(vec.flatten())
known_names.append(name)
end = time.time()
print(f"[INFO] serializing embeddings done, tooks {round(end - start, 3)} seconds")
# 使用SVM來"訓練"我們的模型可以辨別人臉
le = LabelEncoder()
labels = le.fit_transform(known_names)
print("[INFO] training model...")
recognizer = SVC(C=1.0, kernel="linear", probability=True)
recognizer.fit(known_embeddings, labels)
# 啟動WebCam
vs = WebcamVideoStream().start()
time.sleep(2.0)
fps = FPS().start()
while True:
frame = vs.read()
# 偵測人臉與將人臉轉為128-d embeddings
rects = detect(frame)
for rect in rects:
(x, y, w, h) = rect["box"]
roi = frame[y:y + h, x:x + w]
faceBlob = cv2.dnn.blobFromImage(roi, 1.0 / 255, (96, 96), (0, 0, 0), swapRB=True, crop=False)
embedder.setInput(faceBlob)
vec = embedder.forward()
# 辨識人臉
preds = recognizer.predict_proba(vec)[0]
i = np.argmax(preds)
proba = preds[i]
name = le.classes_[i]
text = "{}: {:.2f}%".format(name, proba * 100)
_y = y - 10 if y - 10 > 10 else y + 10
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.putText(frame, text, (x, _y), cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
fps.update()
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
fps.stop()
print("[INFO] Approximate FPS: {:.2f}".format(fps.fps()))
# 清除用不到的物件
cv2.destroyAllWindows()
vs.stop()
if __name__ == '__main__':
main()
python face_recognition/opencv_realtime.py -i dataset/caltech_faces,等待資料庫建立後,辨識看看你自己的臉吧!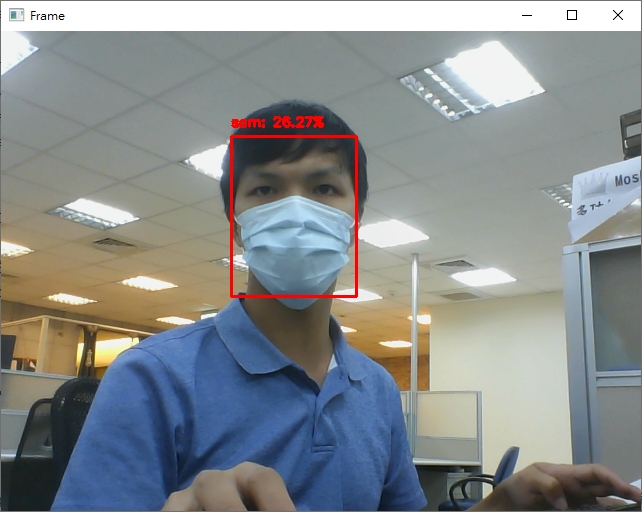
程式碼主要處理流程與昨天基本相同:
可以看到雖然辨識率不高 (主要原因為資料庫中都是未戴口罩的照片,但實際測試是戴上口罩),不過還是可以成功辨識出是誰。
今天的程式碼中是使用與Google FaceNet相同架構的OpenFace預訓練模型,
明天我們將談談FaceNet這個網路。
-- 今日程式碼傳送門
不好意思
請問在opencv_realtime.py專案下
usage: dlib_with_opencv_realtime.py [-h] -i INPUT
dlib_with_opencv_realtime.py: error: the following arguments are required: -i/--input
執行後跑出這個要如何解決
跳出的錯誤應該很清楚了喔!
你缺少了輸入參數INPUT

