昨天介紹完支持向量機,今天就要來介紹甚麼是分類和聚類:
通過將資料通過分類的方法分成不同的組別或者更多的集別,使在同一個子集或組別中的物件都有相似的一些屬性,而組別外的資料差異性會很大-->
分類(class):通常會用擁有一組x和目標(類別)y-->然後透過某個模型去進行學習-->然後就可以把test_X樣本帶模型裡,而求出test_y
聚類(cluster): 通常會用擁有一組x但不知道y-->所以就要利用相似性或是資料之間距離來決定誰為同一組通常組內的相似性越大,組間差別越大,聚類就越好-->簡單來說就是幫一組資料找尋y
而今天主要會聚焦在聚類方法上主要會實作兩個方法,一個是
1.(K-means)K-means clustering
2. (DBSCAN)Density-based spatial clustering of applications with noise
而今天主要先介紹K-means方法
首先是它在維基百科上說明:
(來源:維基百科)
意思也就是說要找到一個中心點,使得那一類到中心點距離最小-->
而k-means在使用會需要先告知你想要分成幾群(因為這個方法是需要決定有幾點中心點)
以下是它的演算法:
1.首先,先從一筆資料內隨機取d個中心點
2.再把資料去對d個中心點去做最短距離配飾-->誰距離短,它就屬於哪類(一樣則隨機分在同樣的類之其中一組)
3.把分好類的資料個別找出新的d個中心點
4.接下來重複2,3直到分類過資料都不再變動為止
(這樣子,就可以求得y為何)-->至於距離一般來說會使用歐式距離
EX: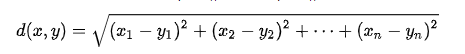
所以明天實際做的時候,會使用歐是距離作示範
好,今天講解完關於kmeans演算法,明天就要開始實際操作程式
小木屋旁,狐狸用他的爪子,摀住他受傷的身體,鮮血從傷口不斷地湧出,男子看著狐狸,同時伸出舌頭舔著刀子上的鮮血,原本男子想往狐狸的喉嚨刺下去,但所幸狐狸反應快,他一個跳躍躲過了致命的一擊,但男子還是刺到了他的身體,狐狸覺得再這樣下去不行,至少它要拉著男子同歸於盡,於是狐狸衝向男子,男子一個側身閃過了衝擊,被抓準時機往狐狸刺了下去,男子笑了笑,但他突然發現自己不能動,原來狐狸在被刺瞬間,同時用尾巴將它纏住,狐狸拖著男子往小木屋衝了過去
--|一起燃燒吧,這是最後的最後,餘燼|-- MS.CM

