各位早安,書接上回我們已經知道抓取想要的網頁資訊的邏輯了,也成功抓到了,今天我們的目標是抓取一整頁文章標題
一樣以 PTT 股票版為例
繼續加強我們的程式
我們先打開原始碼看看標題在哪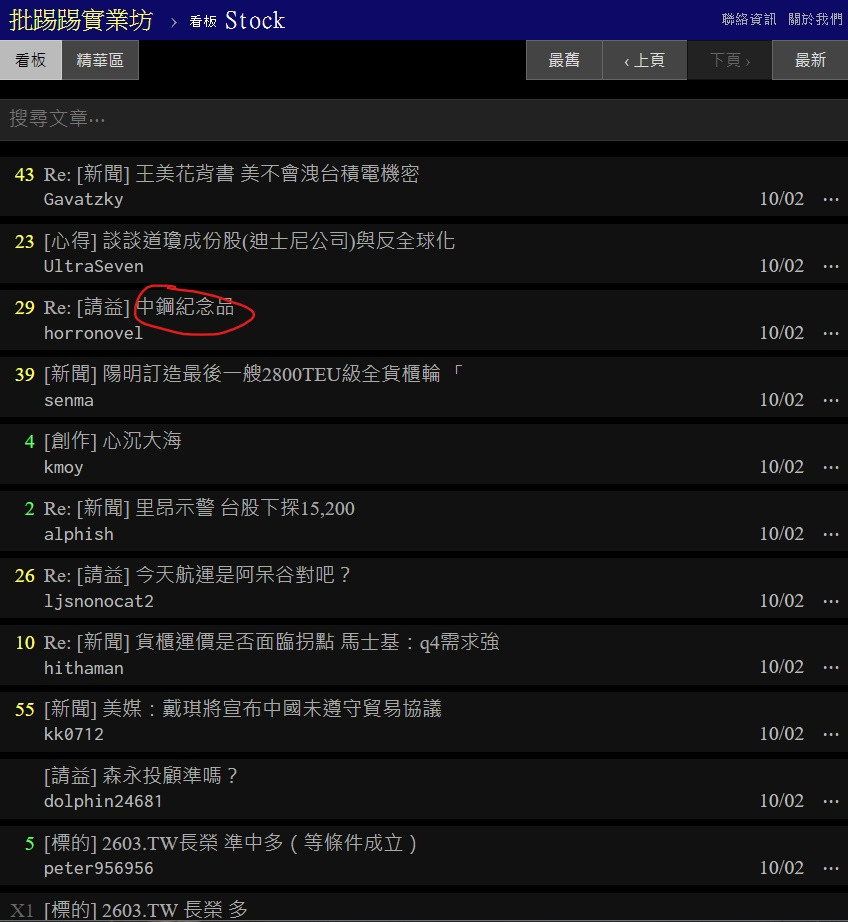
可以看到跟昨天文章內容不一樣 因為這上面的資訊都是實時更新的
我們要的標題位置以中鋼紀念品為例
一樣右鍵檢視網頁原始碼 接著按 CTRL+F
就會出現可以查詢文字的地方
打上要搜尋的 中鋼紀念品 它就會顯示文字位置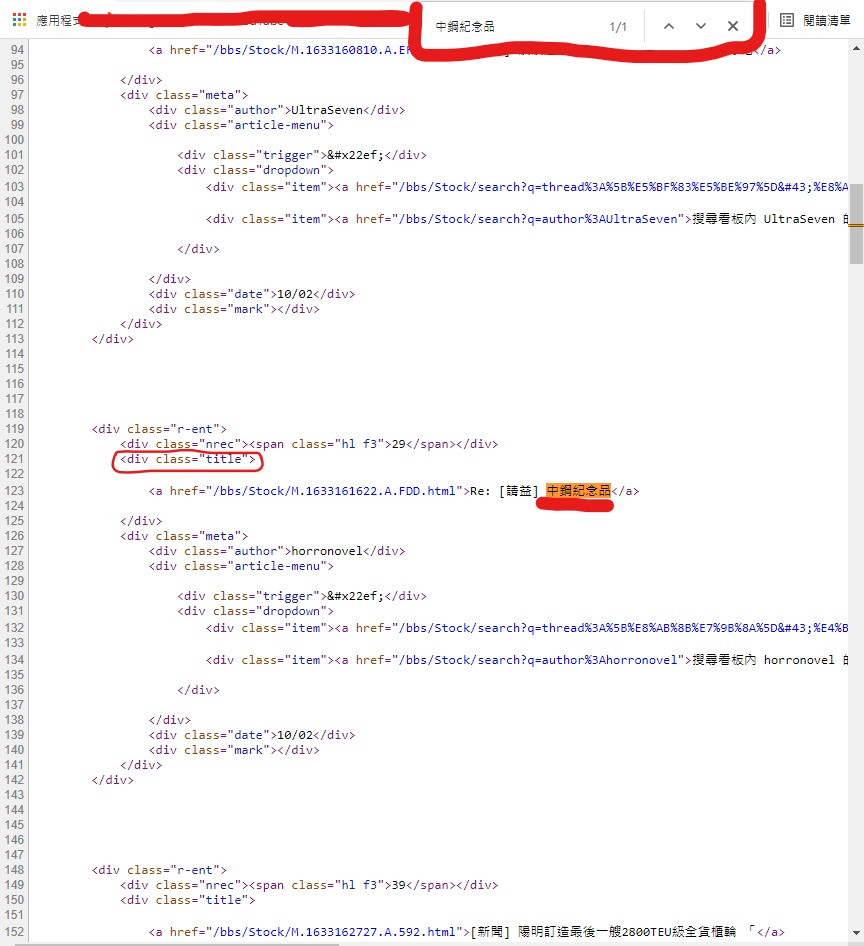
可以看到它是在 < div class="title" > 標籤內
所以程式碼後面加上
titles = data.find("div", class_ = "title")
建立 titles 變數存放我們的資料
資料從 data 裡解析過的資料內 抓取 標籤為 < div > 且 class = "title" 的資料
也就是我們剛剛看到 中鋼紀念品 的位置
因為我做這篇時間太久
所以 PTT 更新了
但是我們要抓的依舊是文章標題沒錯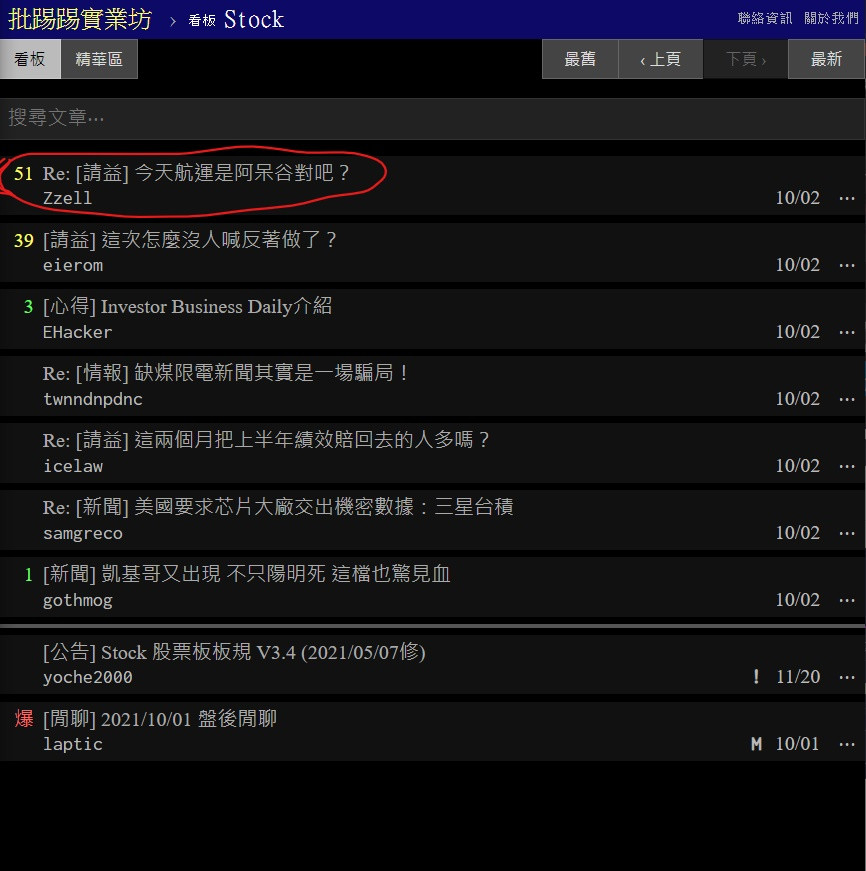
等等應該會抓到這個標題
到時候你們抓到的會是你們網頁開起來後的第一個標題
最後把 print 內改成 titles
程式碼目前是這樣
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index.html"
#抓PTT股票版的網頁原始碼
request = requests.get(url)
#將網頁資料利用requests套件GET下來
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find("div", class_ = "title")
print(titles)
#解析網頁原始碼
執行 python crawler.py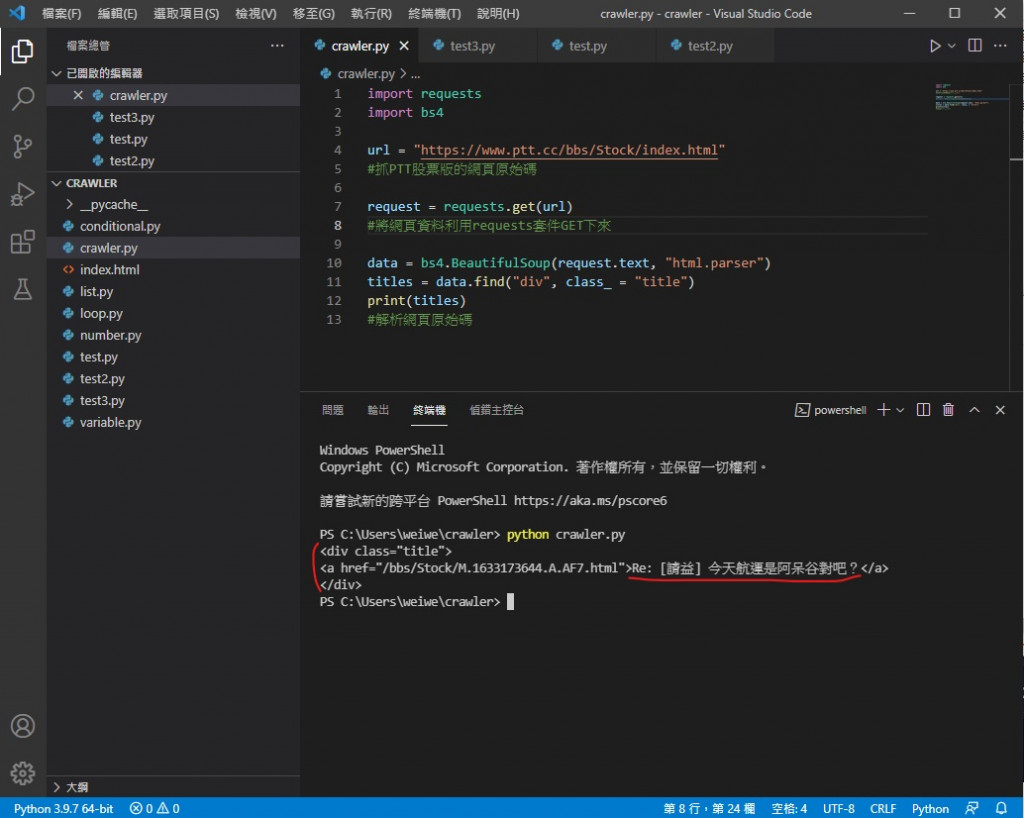
成功印出了 但是有討厭的標籤在不好看
那如果想要去掉標籤
就要再往內指定
把 print(titles) 改成 print(titles.a.text)
因為可以看到我們要的文字部分是在 < div > 標籤內的 < a > 標籤裡
而變數 titles 本身就已經指定到 < div > 標籤內了
所以再 .a 就好
最後的 .text 則是指定 < a > 標籤內的文字部分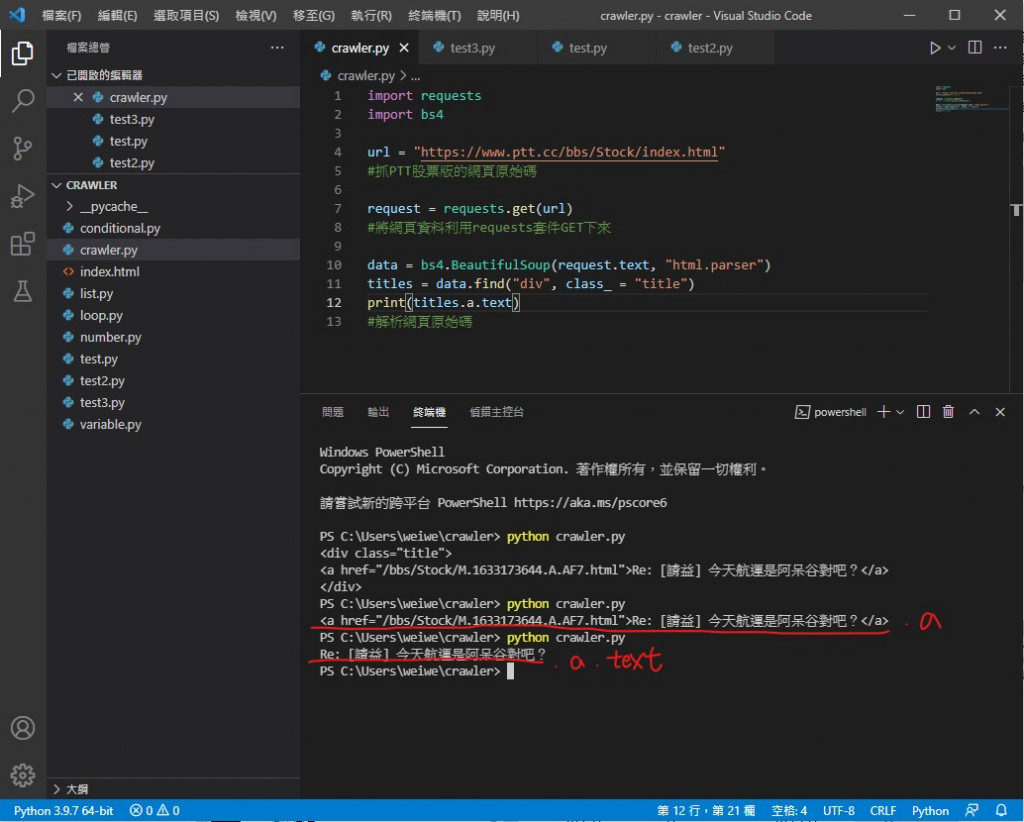
就像這樣 成功只剩下文字了
但是我們要看不會只看第一個標題吧
所以要整頁的標題就要 把 titles = data.find 改成 titles = data.find_all
就是從找到一個變成找到全部
但是光這樣不行 直接執行會噴錯
因為現在 titles 內有好幾個 < div > 標籤跟 < a > 標籤
所以要用 for 迴圈一個一個印出來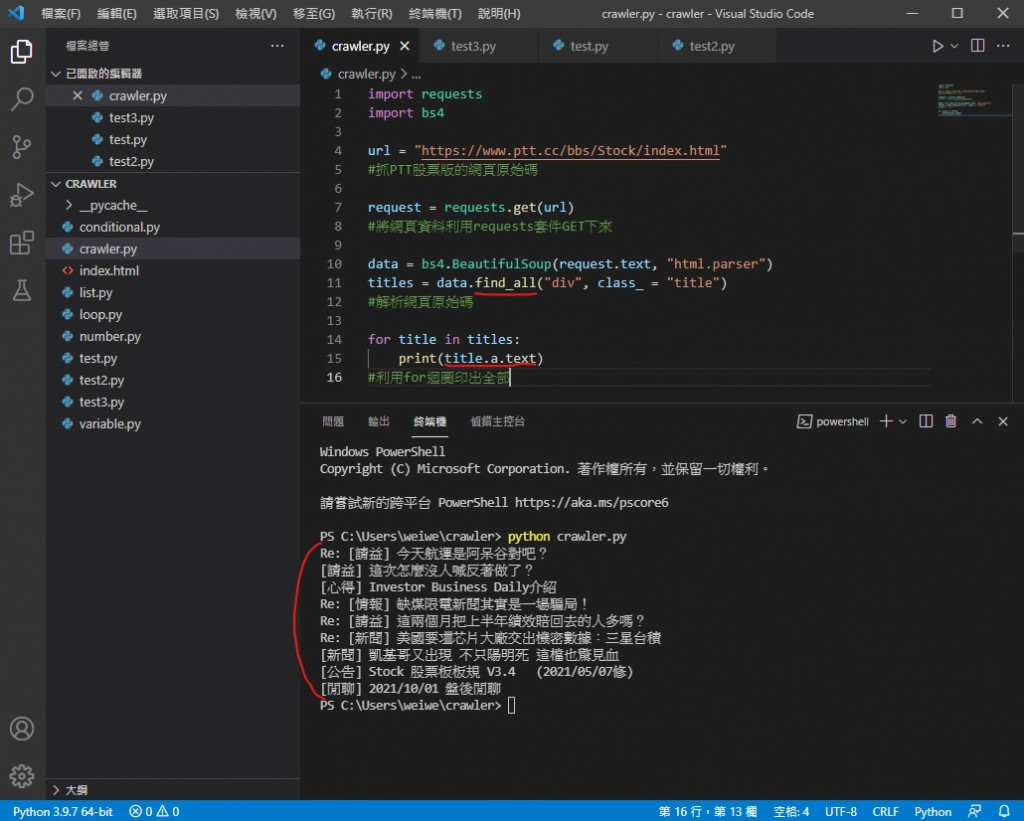
最後就像這樣 得到整頁的文章標題了
如果在執行上遇到錯誤 代表文章中有已經被刪除的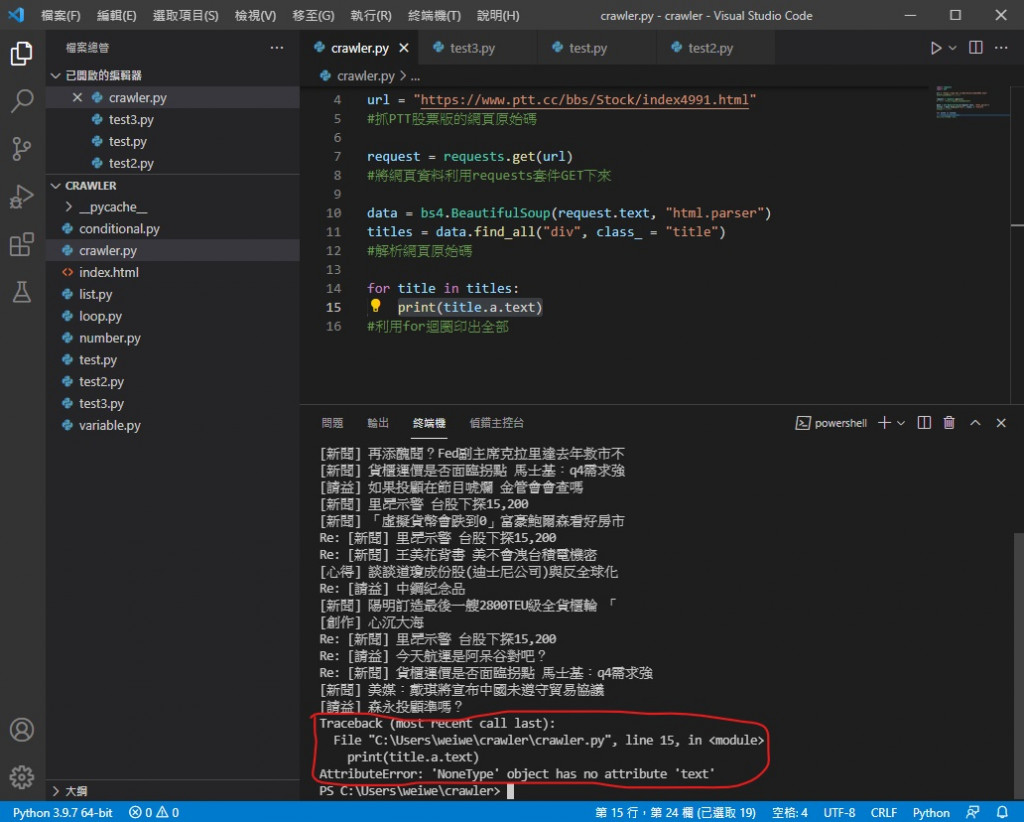
因為被刪除的文章沒有 a 標籤 程式會找不到目標就噴錯
必須在 for 迴圈中加一個 if 用來去掉沒標題的文章
改成這樣就可以了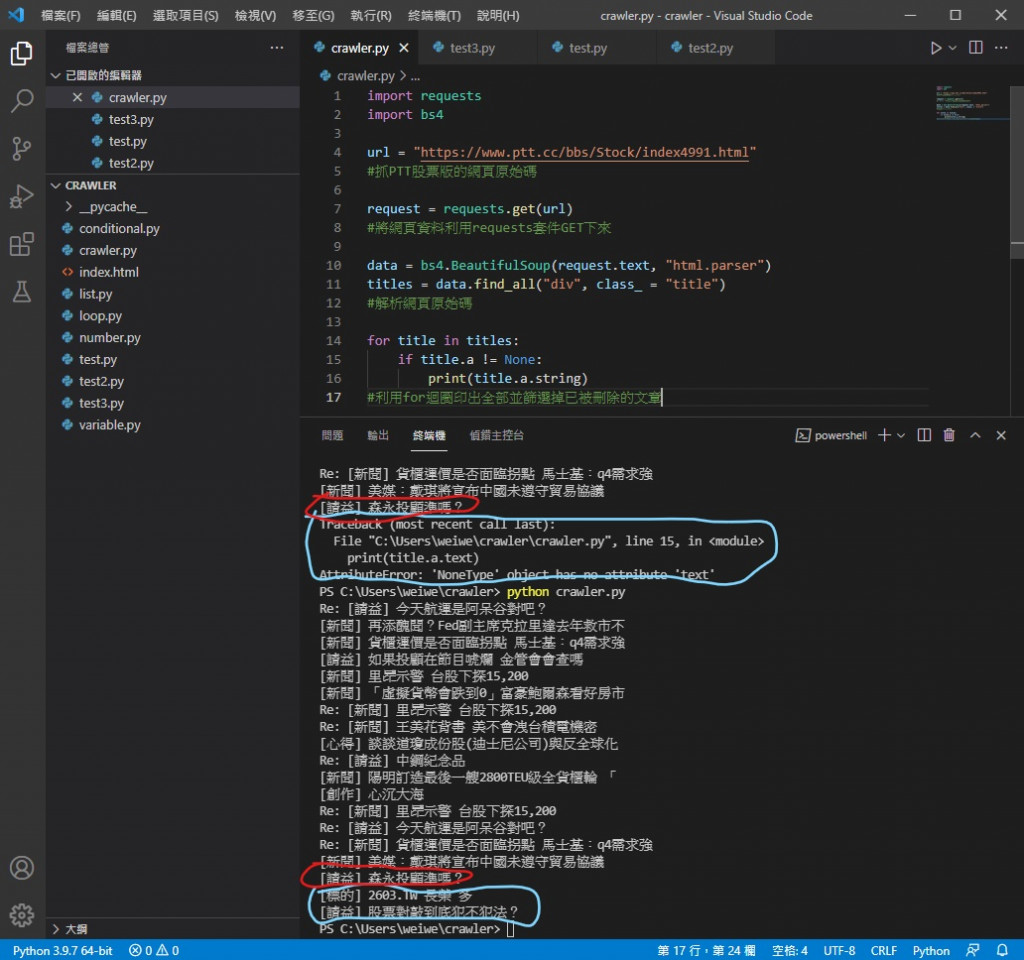
可以看到沒有噴錯 剩下的文章標題也正常印出
今天的程式碼
import requests
import bs4
url = "https://www.ptt.cc/bbs/Stock/index4991.html"
#抓PTT股票版的網頁原始碼
request = requests.get(url)
#將網頁資料利用requests套件GET下來
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析網頁原始碼
for title in titles:
if title.a != None:
print(title.a.string)
#利用for迴圈印出全部並篩選掉已被刪除的文章
今天我們已經能印出整頁所有標題 而且沒有標籤影響美觀 也篩選掉已刪除的文章
明天我們要來實作更進階的功能
販毒比吸毒判刑更重喔 (珍愛生命遠離毒品 碰了不只犯法還會變笨喔)
你希望另一半比自己年長還年輕呢
令人敬佩的鐵人大大您好
感謝您的熱心分享
小白實做一遍,原網站原始碼稍有修改
因此git分享
當作習作繳回
附上傳送門
https://github.com/Alice049/simple_string_debug.git
再次感謝分享喔
這篇文章有幫到你真是太好了

