官方說明文件:https://sinotrade.github.io/tutor/market_data/streaming/quote_binding/
因為在這篇,我們要訂閱tick與bidask的資料,並且將這些資料儲存起來,這時候就要用到Shioaji API中的Quote-Binding Mode。
在官方的說明文件中,Quote-Binding Mode的範例有兩種,第一種是在callback中,將quote資料存入deque中,程式說明如下:
from collections import defaultdict, deque
from shioaji import TickFOPv1, Exchange
msg_queue = defaultdict(deque) #設定要用來儲存quote資訊的msg_queue
api.set_context(msg_queue) #將msg_queue設定為quote_callback中的context
@api.on_tick_fop_v1(bind=True) #在decorator中,將bind設為True來啟用Quote-Binding Mode
def quote_callback(self, exchange:Exchange, tick:TickFOPv1): #quote_callback,參數多加一個self
self[tick.code].append(tick) #這裡的self,其實就是剛才宣告的msg_queue,將quote的tick存入
api.quote.subscribe(
api.Contracts.Futures.TXF['TXF202107'],
quote_type = sj.constant.QuoteType.Tick,
version = sj.constant.QuoteVersion.v1
)
關於defaultdict和deque的說明,可參考Python官方說明文件
https://docs.python.org/zh-tw/3/library/collections.html
而第二個方式,就是將quote資料,存入Redis中。這次測試的資料會以這個方式先儲存在Redis中,程式範例如下:
import redis #匯入redis模組
import json #匯入json模組
from dotenv import load_dotenv
import os, threading
import shioaji as sj
from shioaji import Exchange, TickSTKv1, BidAskSTKv1
load_dotenv('D:\\python\\shioaji\\.env') #讀取.env中的環境變數
r = redis.Redis(host='localhost', port=6379, decode_responses=True) #建立一個Redis的連線
api = sj.Shioaji()
api.login(
person_id=os.getenv('YOUR_PERSON_ID'),
passwd=os.getenv('YOUR_PASSWORD')
)
api.set_context(r) #將Redis的連線傳入
@api.on_tick_stk_v1(bind=True) #將bind設為True來啟用Quote-Binding Mode
def quote_callback(self, exchange: Exchange, tick:TickSTKv1):
channel = 'Q:' + tick.code #設定channel名稱,即存入資料所使用的key值
#將tick quote資料轉換成json並存入Redis中
self.xadd(channel, {'tick':json.dumps(tick.to_dict(raw=True))})
@api.on_bidask_stk_v1(bind=True) #將bind設為True來啟用Quote-Binding Mode
def quote_callback(self, exchange: Exchange, bidask:BidAskSTKv1):
channel = 'Q:' + bidask.code #設定channel名稱,即存入資料所使用的key值
#將bidask quote資料轉換成json並存入Redis中
self.xadd(channel, {'bidask':json.dumps(bidask.to_dict(raw=True))})
# 訂閱盤中tick資料
api.quote.subscribe(
api.Contracts.Stocks["3008"],
quote_type = sj.constant.QuoteType.Tick,
version = sj.constant.QuoteVersion.v1
)
# 訂閱盤中bidask資料
api.quote.subscribe(
api.Contracts.Stocks["3008"],
quote_type = sj.constant.QuoteType.BidAsk,
version = sj.constant.QuoteVersion.v1
)
print('Event().wait()...')
threading.Event().wait() #執行Event().wait(),防止程式未等待quote資料而直接結束
透過以上的程式,就可以訂閱盤中的tick及bidask資料,並將資料儲存至Redis中
儲存完資料後,最花時間的大概就是取出資料這一部份。因為前面的部份,我把tick和bidask的資料都放在同一個db中,如果一開始就放在不同的db,可能就不用花太多時間。
Redis預設會建立16個db,若在建立連線時沒有指定,預設就是用第0個db做儲存
若要指定,可以在建立連線時,加上「db=n」(n為0~15)即可
import redis, json #匯入redis及json模組
import pandas as pd
r = redis.Redis(host='localhost', port=6379, decode_responses=True) #建立一個Redis的連線
# 將所有的tick資料取出來並轉換成DataFrame
tick_datas = [json.loads(x[-1]['tick']) for x in r.xread({'Q:3008':'0-0'})[0][-1] if 'tick' in x[-1].keys()]
df_tick = pd.DataFrame(tick_datas)
df_tick.to_csv('test_tick_data.csv', encoding='utf_8_sig')
# 將所有的bidask資料取出來並轉換成DataFrame
bidask_datas = [json.loads(x[-1]['bidask']) for x in r.xread({'Q:3008':'0-0'})[0][-1] if 'bidask' in x[-1].keys()]
df_bidask = pd.DataFrame(bidask_datas)
df_bidask.to_csv('test_bidask_data.csv', encoding='utf_8_sig')
df_tick['type'] = 'tick' #tick的DataFrame中,增加type欄位,並設為'tick'
df_bidask['type'] = 'bidask' #bidask的DataFrame中,增加type欄位,並設為'bidask'
df = df_tick[['code', 'datetime', 'type']] #抓df_tick中的code、datetime及type,產生新的DataFrame
df = df.append(df_bidask[['code', 'datetime', 'type']]) #將df_bidask中的code、datetime及type,append到新的DataFrame中
df = df.sort_values(by='datetime') #依照datatime欄位內容排序
df = df.reset_index(drop=True) #依照現有的資料,重新產生index編號
df.to_csv('test_result.csv', encoding='utf_8_sig')
取出資料後,我用了DataFrame.append將tick和bidask的資料取出code、datetime及type這三個欄位,並重新組成新的DataFrame,並使用sort_values依照datetime做排序。相關的文件說明請參考以下連結
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.sort_values.html
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.append.html
在這個測試中,我是特別選3008這種成交量不高但又不算冷門的股票。可以看到,bidask資料比較多,而tick資料比較少。結論就是,tick是只有成交時才會有資料;而bidask則是只有買賣的最佳五檔有變化時,就會有資料產生,跟tick是沒有前後關係的。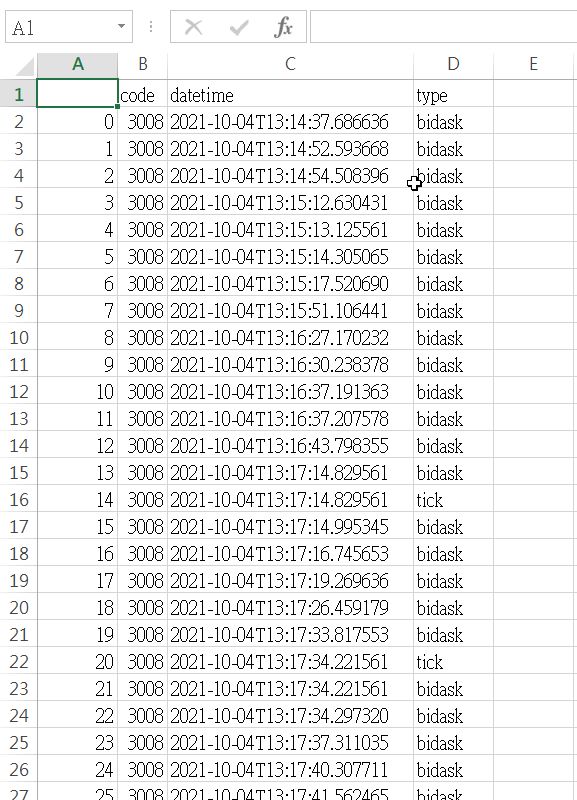


 iThome鐵人賽
iThome鐵人賽