所謂的OHLC(或是OHLCV),就是指Open、High、Low及Close(加上Volume)這幾個欄位。之前的文章中,是將這幾個欄位分別做resample後,再結合成一個DataFrame,但最近做功課時,發現其實可以直接用pandas中的aggregation做運算
Pandas OHLC aggregation on OHLC data
程式範例如下:
import pandas as pd
import sqlite3
conn = sqlite3.connect('D:/shioaji.db') #建立資料庫連線
#從stocks_1min_kbars這個Table中,取出2890這檔股票的資料,並且將ts資料type轉換為datetime64
df = pd.read_sql('SELECT * FROM stocks_1min_kbars WHERE code = "2890"', conn, parse_dates=['ts'])
# 加inplace=True,代表index變動後直接取代原本的dataFrame,而不是回傳一個新的dataFrame
df.set_index('ts', inplace=True)
df_5minK = df.resample('5min').agg({'Open': 'first',
'High': 'max',
'Low': 'min',
'Close': 'last',
'Volume': 'sum'})
df_5minK.to_csv('5minK.csv', encoding="utf_8_sig") #將處理後的資料先匯出成csv檔
conn.close() #關閉資料庫連線
當在處理這類大量的資料時,我會先抓一部份的資料做處理,當處理的結果確定是我要的,我才會正式開始處理全部的資料,以免花了一大堆時間後才發現跑出來的資料是錯的。
上面的程式,我先用pandas.read_sql抓2890永豐金的1分K資料,這裡請務必要加上parse_dates=['ts'],這樣下面的set_index才可以正常執行。
這裡的resample,是參考上面文章中aggregation方式處理,並且加入成交量Volume這個欄位。轉換成5分K並匯出成CSV檔,開啟檔案後,可以看到2021-10-08第一個及第二個5分K,成交量分別為714和137,跟三竹及XQ的前兩個5分K成交量是不同的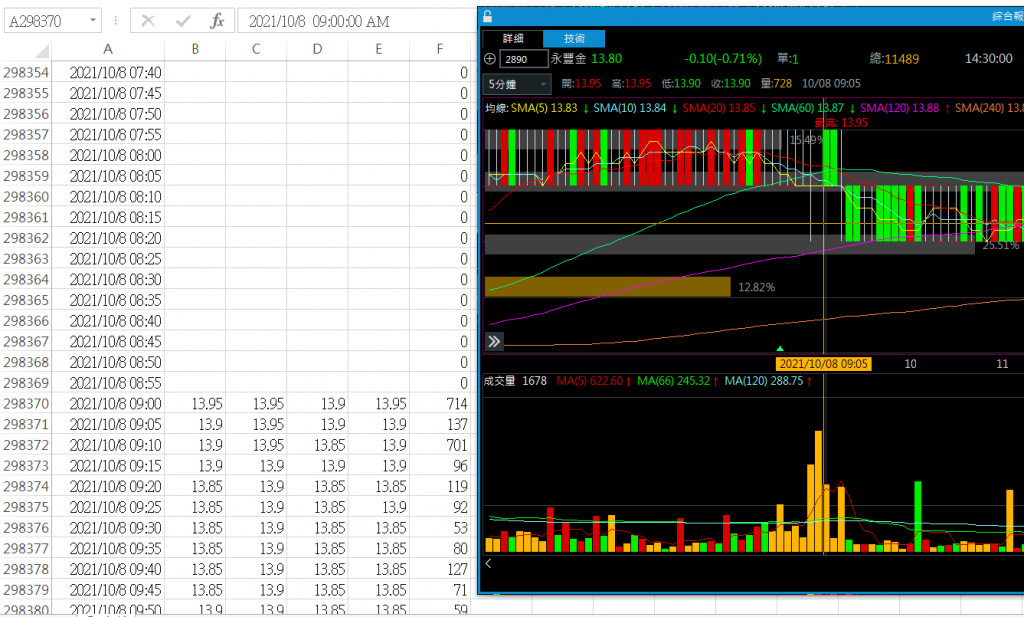
比對1分K的資料之後,發現我們所做的resample,前兩個5分K分別是抓「09:01-09:04」及「09:05-09:09」,而看盤軟體則是抓「09:01-09:05」及「09:06-09:10」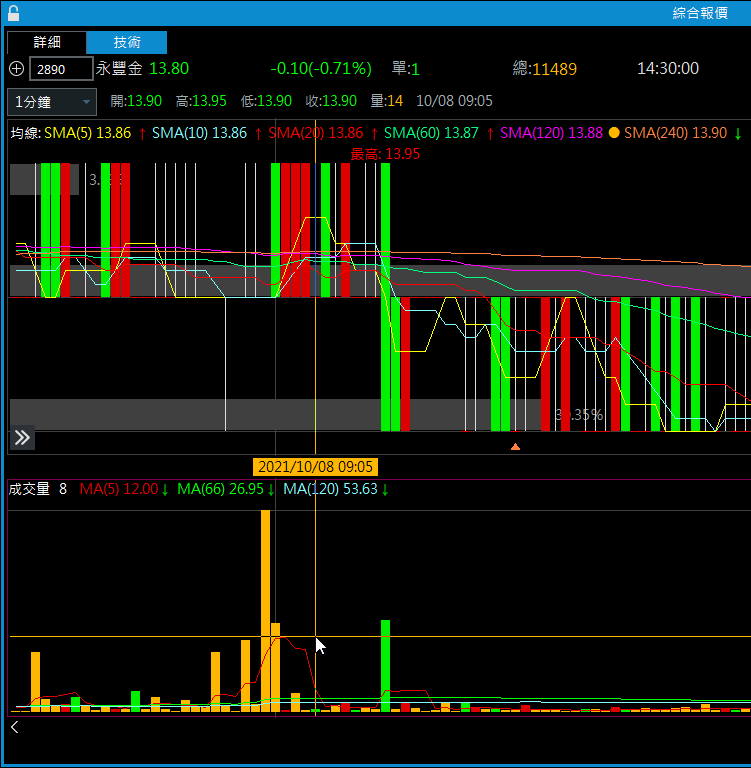
要解決這個問題,可以在resample中傳入「closed='right'」,修改後的程式如下:
# 執行resample,並指定close為right
df_5minK = df.resample(rule='5min', closed='right').agg({'Open': 'first',
'High': 'max',
'Low': 'min',
'Close': 'last',
'Volume': 'sum'})
這樣resample出來的數字,就會跟看盤軟體中的數字一樣
關於DataFrame.resample中的Left與Right,在官方的說明文件中並沒有特別說明,以下為我個人的理解
以上面我們針對1分K做resample為列,當我們執行df.resample(rule='5min')時,pandas就會依照DataFrame中的index,先將資料做分割;雖然在1分K中並沒有09:00的資料,但在做resample時,預設是會自動填補資料上去,此時的資料轉為橫向就會如下圖這樣排列,黃色底就是所謂分割點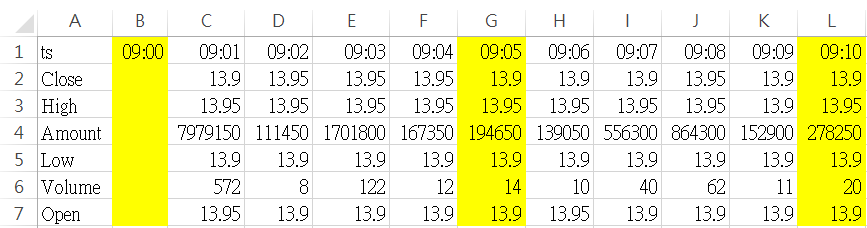
在DataFrame.resample中,label參數影響的是resample後的index內容,而closed則是影響resample後data的內容。在執行resample時,若未指定label跟closed這兩個參數,則預設皆為left,所以resample後,第一組資料的index會是09:00,而data部份也是抓09:00-09:04去做計算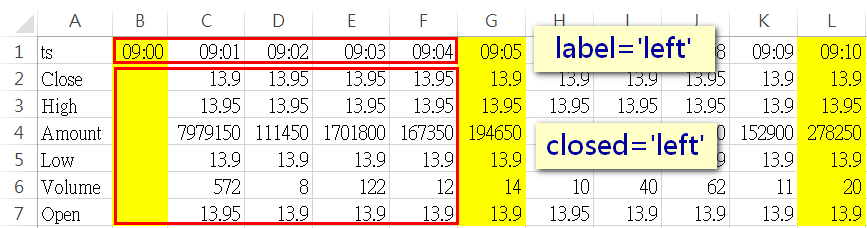
而在執行resample時傳入「closed='right'」,第一組資料的index一樣是09:00,而data部份就變成抓09:01-09:05去做計算(即所謂的向右結合)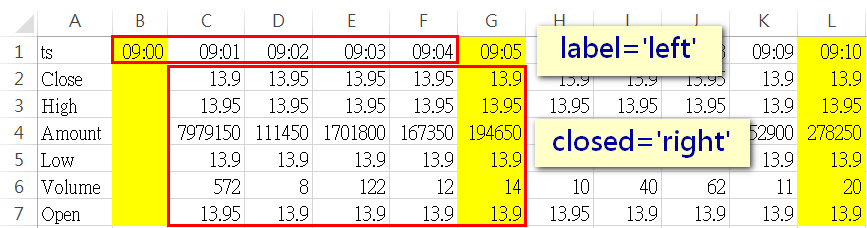
若在執行resample時傳入「closed='right'」及「label='right'」,第一組資料的index就會變成是09:05(向右結合),而data部份一樣是抓09:01-09:05去做計算(即所謂的向右結合)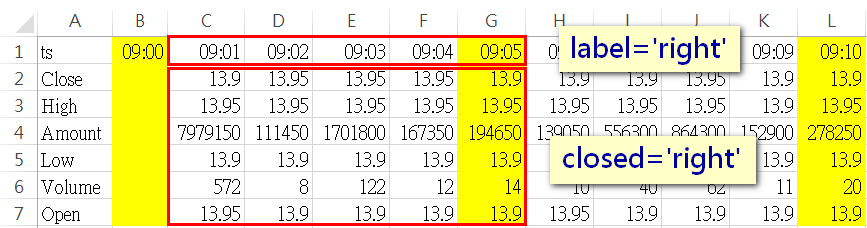
若將上面的資料轉出來並跟看盤軟體比較,你會發現XQ的5分K資料就是label='left'+closed='right';而三竹的5分K資料就是label='right'+closed='right'。
另外,在CSV檔中,可以看到在執行resample後,pandas會幫我們在每個交易日的13:30到次一個交易日的09:00之間,增加對應時間的資料,但因為這段時間沒有資料,所以OHLC的欄位內容皆為空值。我們可以用
pandas.DataFrame.dropna來刪除這些不需要的資料
df_5minK.dropna(axis=0, inplace=True) #移除有空值的row,並取代原本的DataFrame
接著,我們就可以依照上面的程式碼,稍做修改來產生所有股票的5分K資料,完整程式範例如下:
import pandas as pd
import sqlite3
conn = sqlite3.connect('D:/shioaji.db') #建立資料庫連線
# 傳入股票代碼,產生5分K資料並存至資料庫
def generate_5min_kbar(stock_code):
print(f'generate 5minK for stock:{stock_code}') #輸出程式執行點資料至console
df = pd.read_sql(f'SELECT code, Open, High, Low, Close, Volume, ts FROM stocks_1min_kbars WHERE code = {stock_code}', conn, parse_dates=['ts'])
df.set_index('ts', inplace=True)
df_5min_kbar = df.resample(rule='5min', closed='right').agg({
'code': 'first',
'Open': 'first',
'High': 'max',
'Low': 'min',
'Close': 'last',
'Volume': 'sum'})
df_5min_kbar.dropna(axis=0, inplace=True)
df_5min_kbar.to_sql('stocks_5min_kbars', conn, if_exists='append')
print(f'stock:{stock_code}, 5minK is added to DB...') #輸出程式執行點資料至console
cursor = conn.cursor() #建立cursor物件
# 執行SQL,取出stocks_1min_kbars中所有的股票代碼(不重複)
for code in cursor.execute('SELECT DISTINCT code FROM stocks_1min_kbars'):
generate_5min_kbar(code[0])
conn.close() #關閉資料庫連線
請注意,在df_5min_kbar.to_sql這裡,並沒有傳入index=False,因為現在df_5min_kbar中的index就是ts欄位,而寫入資料庫是需要保留這個欄位內容,供後續處理資料時使用。
若要產生其它分K的資料,只要稍微修改上面的程式碼,就可以產生對應的資料。


 iThome鐵人賽
iThome鐵人賽