偵測人臉位置與人臉關鍵點,兩個混 合 在 一 起
MTCNN -- Multi-task Cascaded Convolutional Networks
從完成名稱可以看出一些端倪:
到這裡你已經知道MTCNN的精隨了,剩下的就是如何訓練MTCNN。
但這部分是需要精心設計訓練資料,以及分階段訓練MTCNN (P-Net -> R-Net -> O-Net),
這裡我們只專注在如何使用,
Let's Go!
facial_landmark目錄下新增mtcnn_predictor.py
mtcnn_predictor.py,輸入下面到目前為止最簡單的程式碼:
import time
import cv2
import mtcnn
from imutils.video import WebcamVideoStream
def main():
# 初始化模型
detector = mtcnn.MTCNN()
# 啟動WebCam
vs = WebcamVideoStream().start()
time.sleep(2.0)
while True:
frame = vs.read()
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
faces = detector.detect_faces(rgb)
for face in faces:
(x, y, w, h) = face['box']
keypoints = face['keypoints']
conf = face['confidence']
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(frame, f"confidence: {str(round(conf, 3))}", (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 255), 2)
for (s0, s1) in keypoints.values():
cv2.circle(frame, (s0, s1), 2, (0, 0, 255), -1)
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
# 清除用不到的物件
cv2.destroyAllWindows()
vs.stop()
if __name__ == '__main__':
main()
python facial_landmark/mtcnn_predictor.py
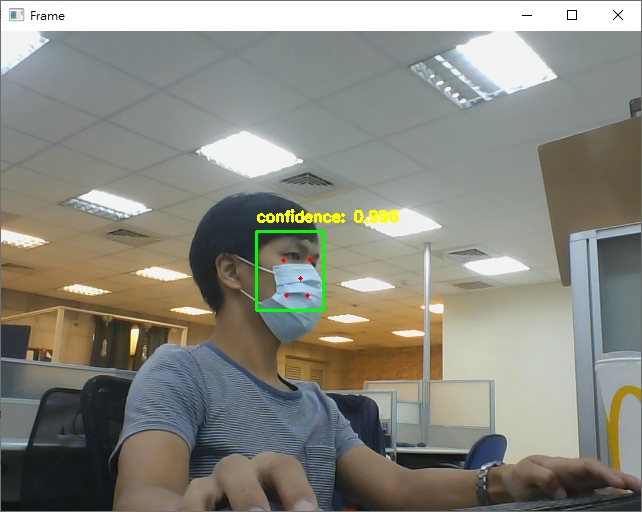
這次我給模型更困難的辨識情況:
但實際辨識結果你可以看到:不但辨識率有90%以上,也可以大致上辨別出眼、鼻、嘴等的位置。
而實際上,
FaceNet網路在訓練人臉辨識時也是使用MTCNN當作人臉偵測與人臉關鍵點任務使用
好工具,不學起來用嗎?

