昨天介紹完kmeans演算法程式,今天就要介紹DBSCAN演算法:
基本上他是根據資料點的密度進行聚類, 演算法會把附近的點分成一組(有很多相鄰點的點)並找出局外點,把他剃除,而他有一個好處,就是他一開始不用告知要分幾類,而是從資料來判斷是否為同一類,基本上演算法如下:
由數值點為半徑劃出的圓型區域,然後看這個區域是是否有包含其他點(數量如果超過最低點)-->就稱他們為同一類別
(圖片來源: https://www.itread01.com/content/1544121185.html)
演算法如下:
1.先設定好一個點半徑R和高密度點最少要M個點(也就是設定R和M)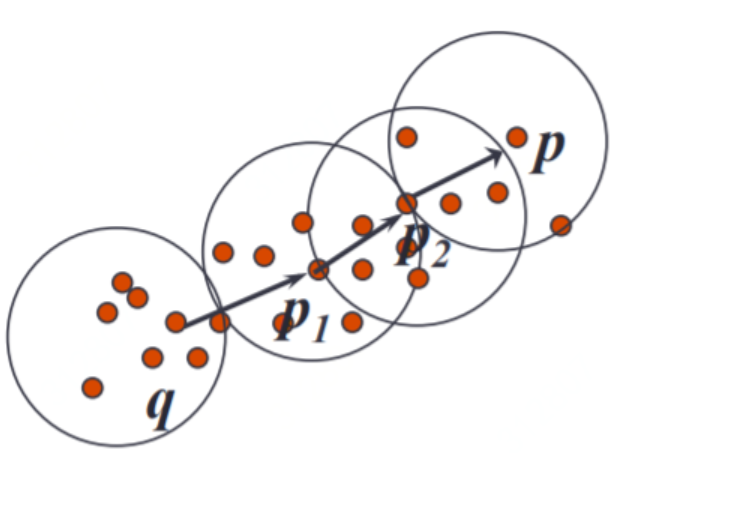
2.先隨機選一點P,然後對其畫出一個圓,然後看他範圍內是否滿足M個點(包含自己)-->如果有則建立新聚類,沒有就找尋下一個非聚類點
3.如果有新聚類產生,要針對他P點聚類範圍內所有點,在畫出一個圓,然後看有沒有點被添加(如果有,新的點也要畫出一個圓,然後看裡面有沒有再被添加,重複這個過程,直到範圍內沒有其他點),及視為一個聚類
4.重複2,3直到點全部分割完,遺留下來點,就稱為局外點
好了演算法就寫到這,明天再想想該如何去寫這個演算法:
先寫好之前程式繪圖(拿kmeans時,所用資料來做):
import numpy as np
label_data=np.array([[45,59],[52,63],[18,52],[72,24],[20,36],[12,39],[53,23],[52,70],[45,63],[24,55],[33,46],[28,30],[29,54],[55,14],[61,8],[69,7],[64,19],[51,66]])
label_data_x=[label_data[i][0] for i in range(len(label_data))]
label_data_y=[label_data[i][1] for i in range(len(label_data))]
print(label_data_x)
print(label_data_y)
import matplotlib.pyplot as plt
plt.scatter(label_data_x,label_data_y)
plt.show()
資料圖如下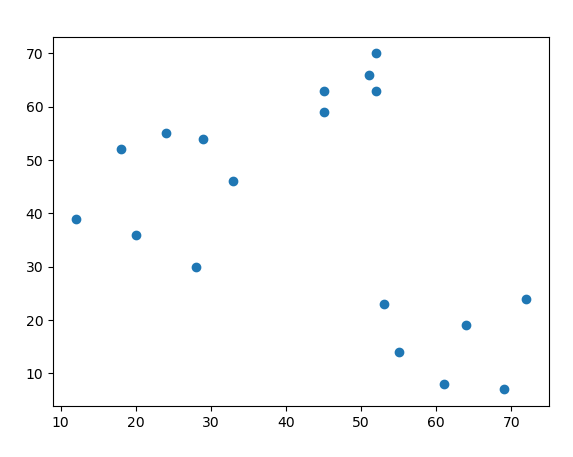
男孩看著娃娃,又看了狐狸一眼,只見狐狸茫然坐到地上,下一秒,狐狸突然開始不斷往男孩方向衝刺,只是每當他想撞過來時,都被娃娃伸手彈開,狐狸露出牙齒對著娃娃低吼,娃娃只是面無表情看著他,這時男子優雅往狐狸方向走過去,並對牠伸出了手,狐狸怒瞪了男子一眼,但隨即伸出手握住了男子
--|我不容許背叛/我容許合作|-- MS.CM/CS.MM

