正規化 (Regularizers) 是在 Loss Function 中,多加一項權重的懲罰,目的是規範模型在學習過程中,避免權重值過大,達到一種防止過擬合的手段。其中有L1和L2兩種正規化方式。
今天我們會分別來實驗: 完全不做、做L1 Regularizers 和做L2 Regularizers 三種實驗的差別。在實驗前,我們一樣先做一個方便測試的模型 function。
def get_mobilenetV2(shape, regularizer):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same', depthwise_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), regularizer, shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), regularizer, shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), regularizer, shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), regularizer, shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), regularizer, shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), regularizer, shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), regularizer, shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), regularizer, shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), regularizer, shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), regularizer, shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), regularizer, shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), regularizer, shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
return input_node, net
def bottleneck(net, filters, out_ch, strides, regularizer, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding, depthwise_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
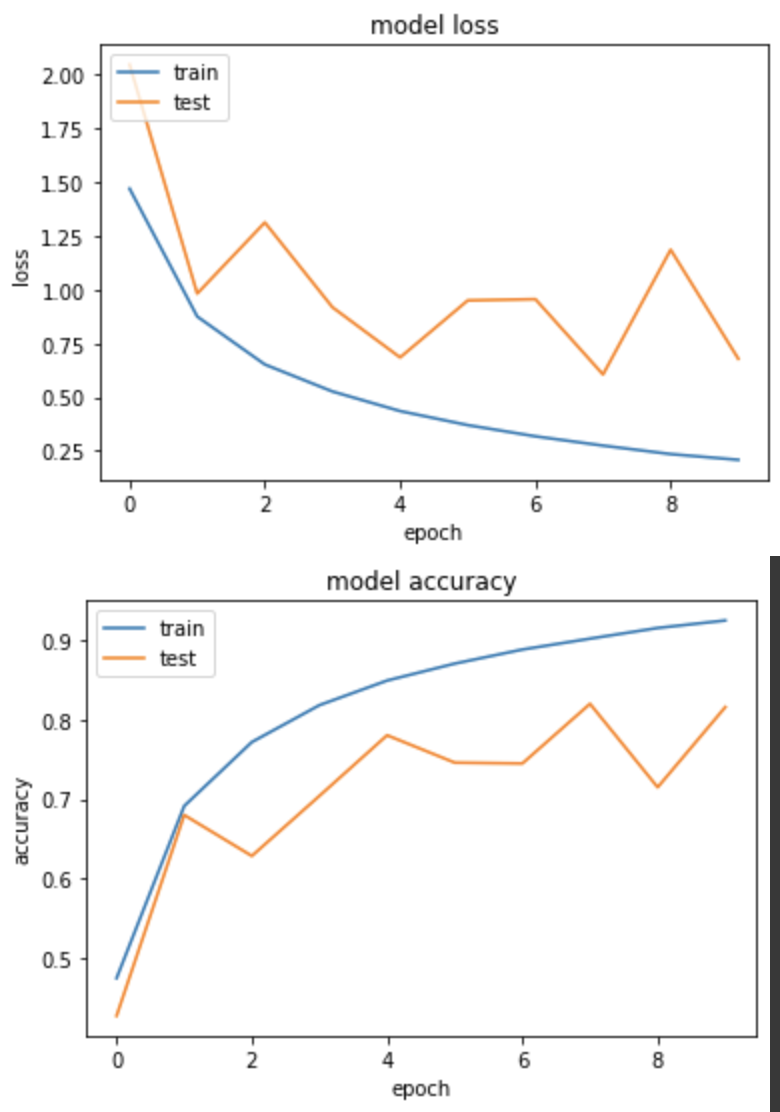
實驗一:完全不做
只要將 REGULARIZER 設為 None 丟進去即可。
REGULARIZER=None
input_node, net = get_mobilenetV2((224,224,3), REGULARIZER)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
產出
loss: 0.2075 - sparse_categorical_accuracy: 0.9257 - val_loss: 0.6781 - val_sparse_categorical_accuracy: 0.8164
實驗二:使用 L1 Regularizers
一般來說,L1 Regularizers 具有稀疏性,很容易將大部分的權重變成0,只為了找到主要影響的 features
REGULARIZER=tf.keras.regularizers.l1(0.001)
input_node, net = get_mobilenetV2((224,224,3), REGULARIZER)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
reg_losses = []
class LogRegCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
reg_loss = tf.math.add_n(self.model.losses)
reg_losses.append(reg_loss.numpy())
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True,
callbacks=[LogRegCallback()])
我們多做了一個 callback 紀錄每個 epoch 會得到多少 reg_loss。
產出:
loss: 1.7935 - sparse_categorical_accuracy: 0.4739 - val_loss: 2.2774 - val_sparse_categorical_accuracy: 0.3328
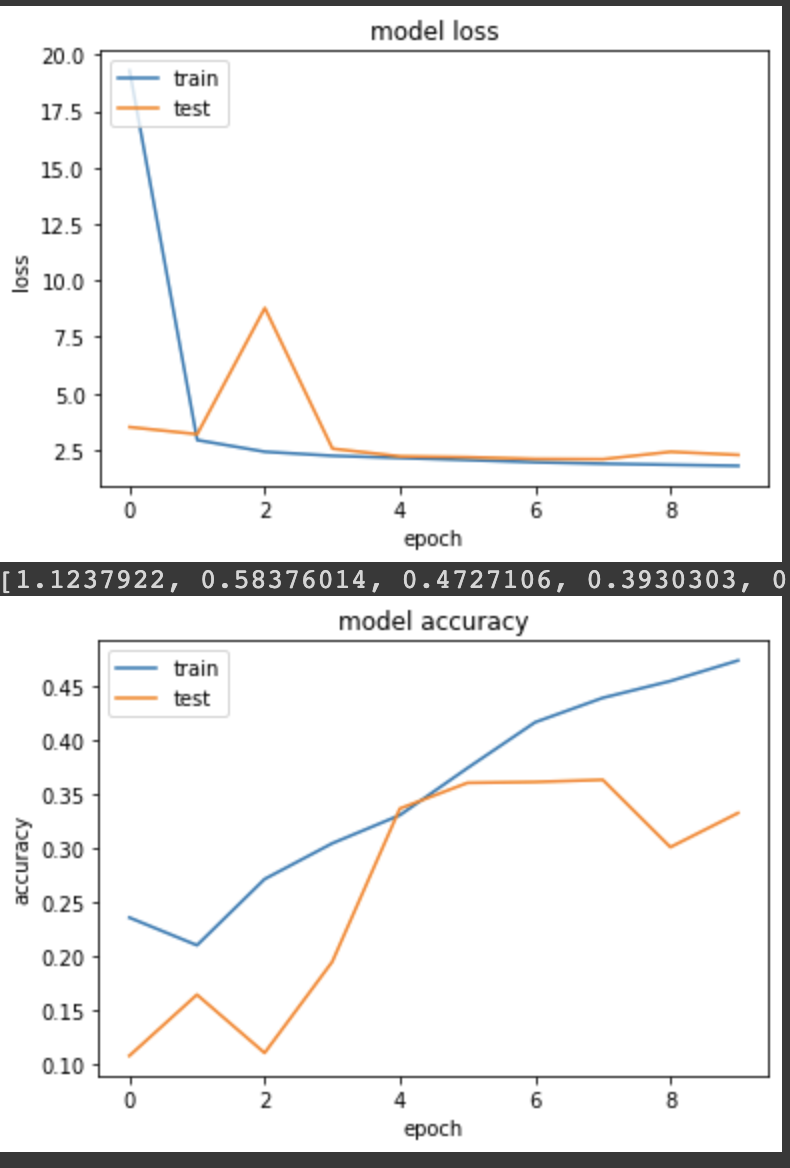
reg loss值在10個 epochs 中分別是:
[1.1237922, 0.58376014, 0.4727106, 0.3930303, 0.37723392, 0.37397617, 0.36347908, 0.3558346, 0.347651, 0.3464979]
實驗三:使用 L2 Regularizers
和實驗二一樣,我們用 callbacks 來紀錄 reg_loss。
REGULARIZER=tf.keras.regularizers.l2(0.001)
input_node, net = get_mobilenetV2((224,224,3), REGULARIZER)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS, kernel_regularizer=REGULARIZER, bias_regularizer=REGULARIZER)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
reg_losses = []
class LogRegCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
reg_loss = tf.math.add_n(self.model.losses)
reg_losses.append(reg_loss.numpy())
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True,
callbacks=[LogRegCallback()])
產出:
loss: 1.0696 - sparse_categorical_accuracy: 0.8059 - val_loss: 1.8243 - val_sparse_categorical_accuracy: 0.5945
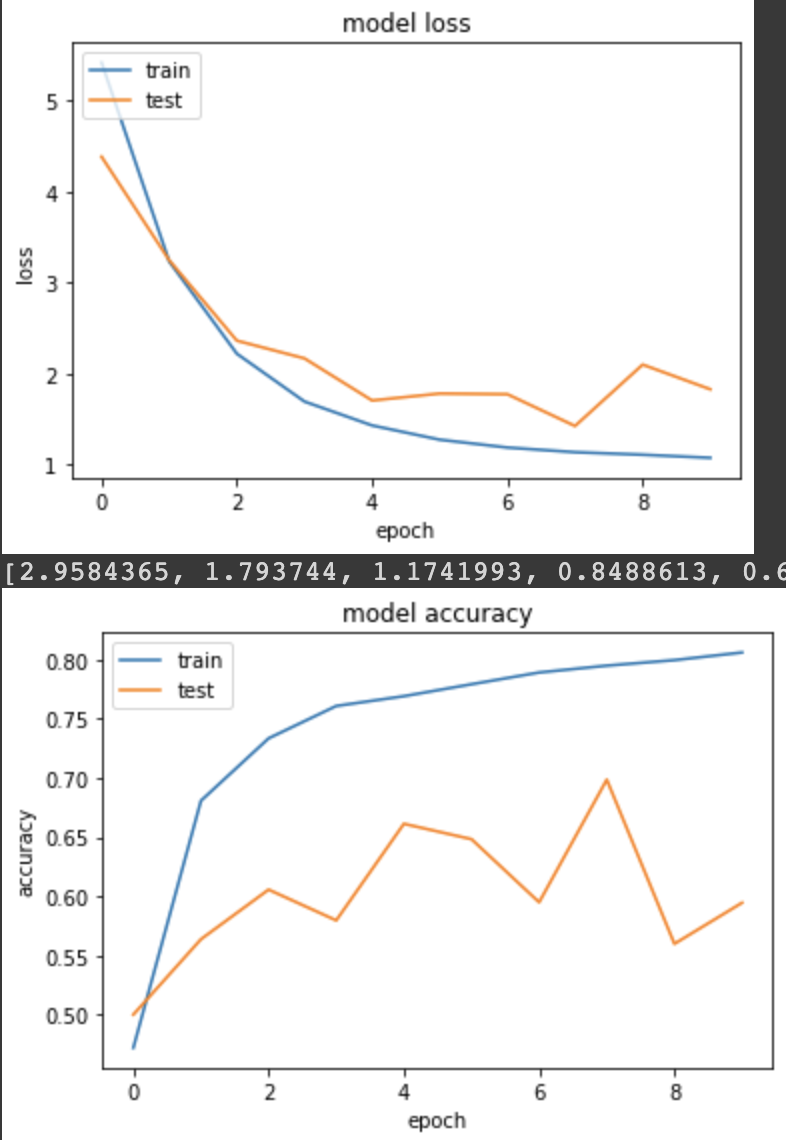
reg loss值在10個 epochs 中分別是:
[2.9584365, 1.793744, 1.1741993, 0.8488613, 0.67782825, 0.5916853, 0.54554325, 0.52234, 0.51154846, 0.50444514]
以上就是這兩個 Regularizers 的實驗。我自己的實務經驗其實很少使用,因為現在有了 Batch Normalization,該怎麼使用了,明天會再做實驗分享。

