
昨天我們探討了 L1 與 L2 Regularizers 的問題,但其實啊,Regularizers 還有一個和 Batch Normalization 有個有趣的關係,這篇文章 L2 Regularization and Batch Norm 提到了同時使用 BN 和 Regularizers 時,所產生的有趣問題。
首先,我們知道套用 Regularizers 後,會對權重產生一個小於1的衰變(decay),
讓權重更新往0靠近些,這個(1−αc)的值我們稱作為λ。

另一方面,經過 CNN 或 Dense 層輸出的數值通常會再經過 BN 層,BN 層會對該次 batch 計算平均 mean 和變異數 var,並正規化輸出:
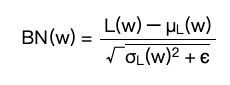
而剛剛λ倍縮放了權重,也等於是縮放了輸出,對於BN的 mean 和 var 也一樣做了λ倍的縮放,所以套回原本的 BN 公式,分子和分母同時乘上 lambda 就剛好抵銷,等於是經過 BN 層後,Regularizers 對輸出毫無影響。

那麼,如果是這樣子,我們還需要 Regularizers 做什麼?其實就算 Regularizers 的效果被 BN 約掉,他仍然可以拿來約束權重的大小,這反而讓 Regularizers 有了一個新的定位!
綜上所述,我們分別來訓練並觀察:
實驗一:僅用 BN
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_bn(shape):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
return input_node, net
input_node, net = get_mobilenetV2_bn((224,224,3))
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True,
callbacks=[PrintWeightsCallback()])
Epoch 1/10
conv2d_70 layer: [-0.02620085 0.10190549 -0.11347758 -0.120565 0.10449789 0.09324147 -0.02767587 0.03863515 0.12804998 0.10915002]
(略)
Epoch 10/10
conv2d_70 layer: [-0.17744583 0.17197324 -0.25094765 -0.4260909 -0.2861711 0.12653658 -0.18487974 0.10149723 -0.08124655 0.30025354]
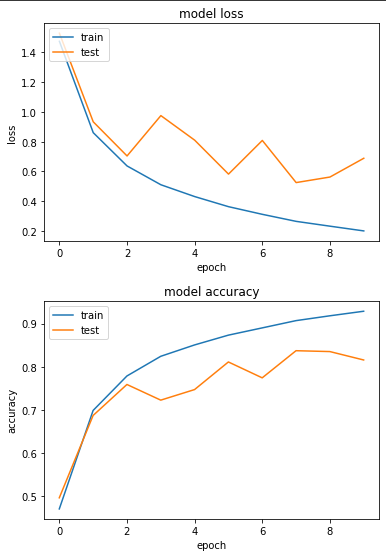
可以看到模型準確度有上升,而模型的權重的大小以0.x居多。
實驗二:僅用 L2 Regularizers
def bottleneck(net, filters, out_ch, strides, regularizer, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding, depthwise_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_l2(shape, regularizer):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(input_node)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same', depthwise_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = bottleneck(net, 16, 24, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), regularizer, shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), regularizer, shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), regularizer, shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), regularizer, shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), regularizer, shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), regularizer, shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), regularizer, shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), regularizer, shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), regularizer, shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), regularizer, shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), regularizer, shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), regularizer, shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
return input_node, net
REGULARIZER=tf.keras.regularizers.l2(0.001)
input_node, net = get_mobilenetV2_l2((224,224,3), REGULARIZER)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS, kernel_regularizer=REGULARIZER, bias_regularizer=REGULARIZER)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True,
callbacks=[PrintWeightsCallback()])
產出:
Epoch 1/10
conv2d_140 layer: [ 0.13498078 -0.12406565 0.05617869 0.1112484 0.0101945 -0.09676153 0.05650736 0.03752249 -0.01030101 0.08091953]
(略)
Epoch 10/10
conv2d_140 layer: [ 0.00809666 -0.00744193 0.00336981 0.00667309 0.0006115 -0.00580412 0.00338953 0.00225074 -0.00061789 0.00485385]
準確度沒上升,但是權重有受到 Regularizers 的影響,最後的大小在 0.00X附近。
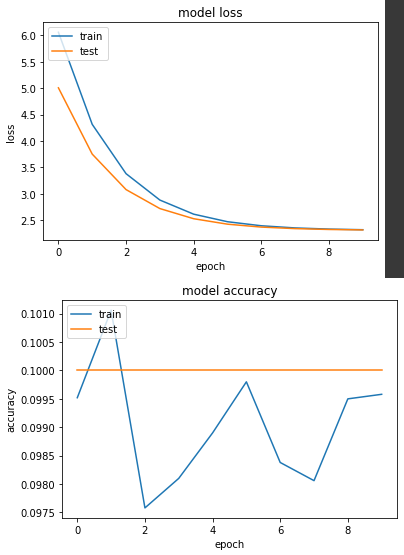
實驗三:同時使用 BN 與 L2 Regularizers
def bottleneck(net, filters, out_ch, strides, regularizer, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding, depthwise_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_bn_l2(shape, regularizer):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same', depthwise_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), regularizer, shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), regularizer, shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), regularizer, shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), regularizer, shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), regularizer, shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), regularizer, shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), regularizer, shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), regularizer, shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), regularizer, shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), regularizer, shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), regularizer, shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), regularizer, shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), regularizer, shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same', kernel_regularizer=regularizer, bias_regularizer=regularizer)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
return input_node, net
REGULARIZER=tf.keras.regularizers.l2(0.001)
input_node, net = get_mobilenetV2_bn_l2((224,224,3), REGULARIZER)
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS, kernel_regularizer=REGULARIZER, bias_regularizer=REGULARIZER)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True,
callbacks=[PrintWeightsCallback()])
產出:
Epoch 1/10
conv2d layer: [ 0.08555499 0.12598534 -0.03244241 0.11502795 0.05982415 0.11824064 0.13084657 0.08825392 0.02584527 -0.0615561 ]
(略)
Epoch 10/10
conv2d layer: [-0.12869535 -0.09060557 0.01533028 -0.05165869 -0.00263854 -0.06649228 -0.02129784 0.09801372 0.12735689 0.0331211 ]
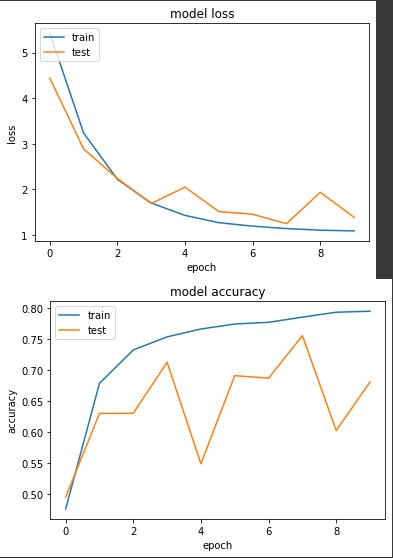
準確度有上升,權重也有比實驗一有壓制的感覺,雖然最大有到0.12,但多數為0.0X。
如同昨天說到,我自己實務上很少套用 Regularizers 在訓練任務上,雖然實驗三發現 Regularizers 可以把權重壓小,但是實驗一使用 BN 後的權重數值也還在可接受的區間。
ref:
https://blog.janestreet.com/l2-regularization-and-batch-norm/
