今天開始的幾天內,會進入 Azure Machine Learning(下稱 AML) SDK 比較難的地方,但也是最核心且最強大的地方囉!
一個科學家,會做很多很大量的實驗,來證明某些東西。而資料科學家也是,需要做很多實驗,才找到 insight。在 AML 裡面提供了 Experiment 這個類別,可以讓你可以更好管理你的每次的實驗。你可以使用不同的資料、不同的程式碼來執行同一個實驗,然後發佈到 AML 紀錄每一次執行的結果,讓你更好的管理資料科學的研究。
而 Run,就是每一次實驗「跑」的過程,你可以透過 Run 物件來紀錄你跑的過程。一個實驗裡面可以有很多次的 Run,還記得下面這張圖嗎?這是我們在 AutoML 的章節裡最後的結果。這張圖裡面的 Experiment 叫做 AutoTitanic,然後有一個 Run。如果你再調整後再跑一次,又會再多出個 Run 出來。這就是 Experiment 和 Run 的關係。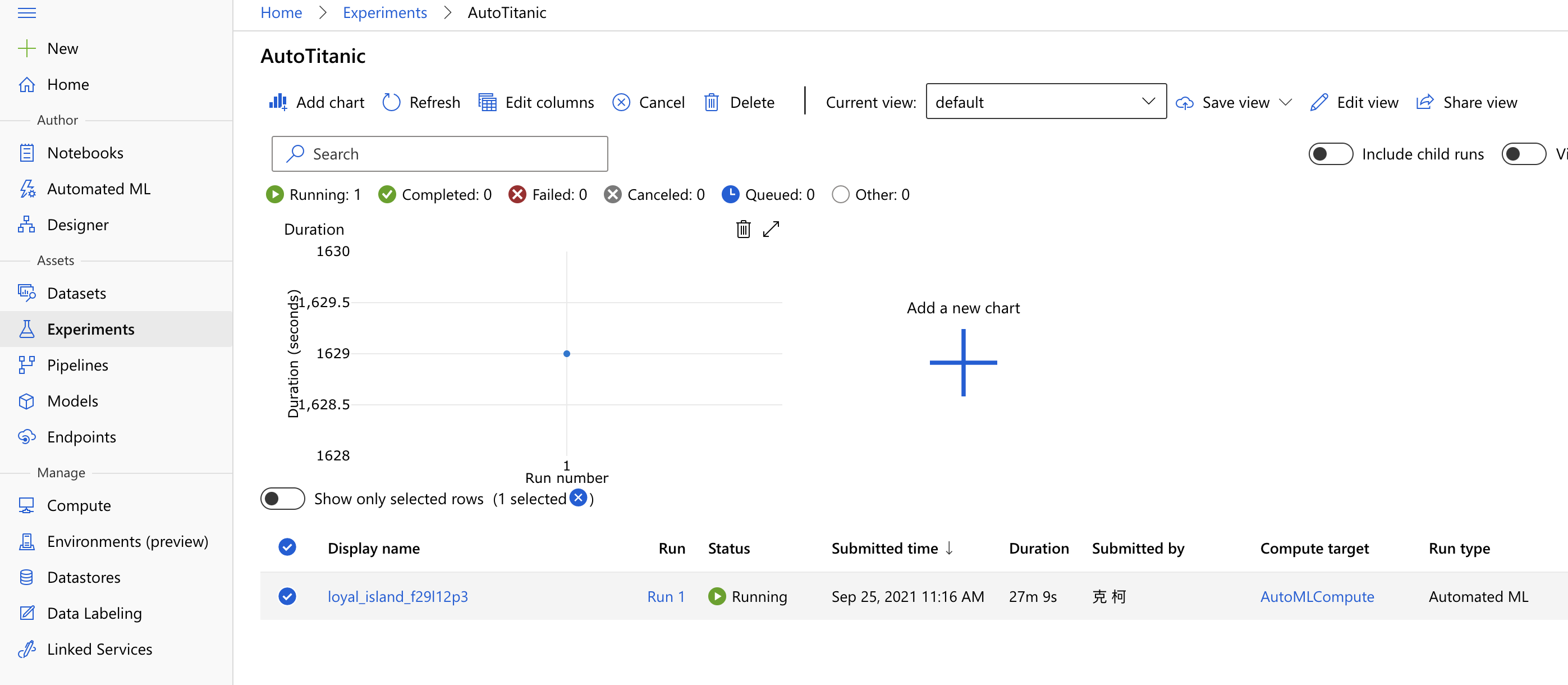
from azureml.core import Experiment
# 建立一個 Experiment
experiment = Experiment(workspace = ws, name = "experiment_sdk")
# 開始一個實驗並紀錄
run = experiment.start_logging()
data = pd.read_csv('data.csv')
row_count = (len(data))
# 用 log 紀錄下來
run.log('資料大小', row_count)
# 實驗完成
run.complete()
接著我們進到 AML 的介面,點左邊選單的 Experiment,就會看到我們剛剛建起來的實驗:experiment_sdk 了。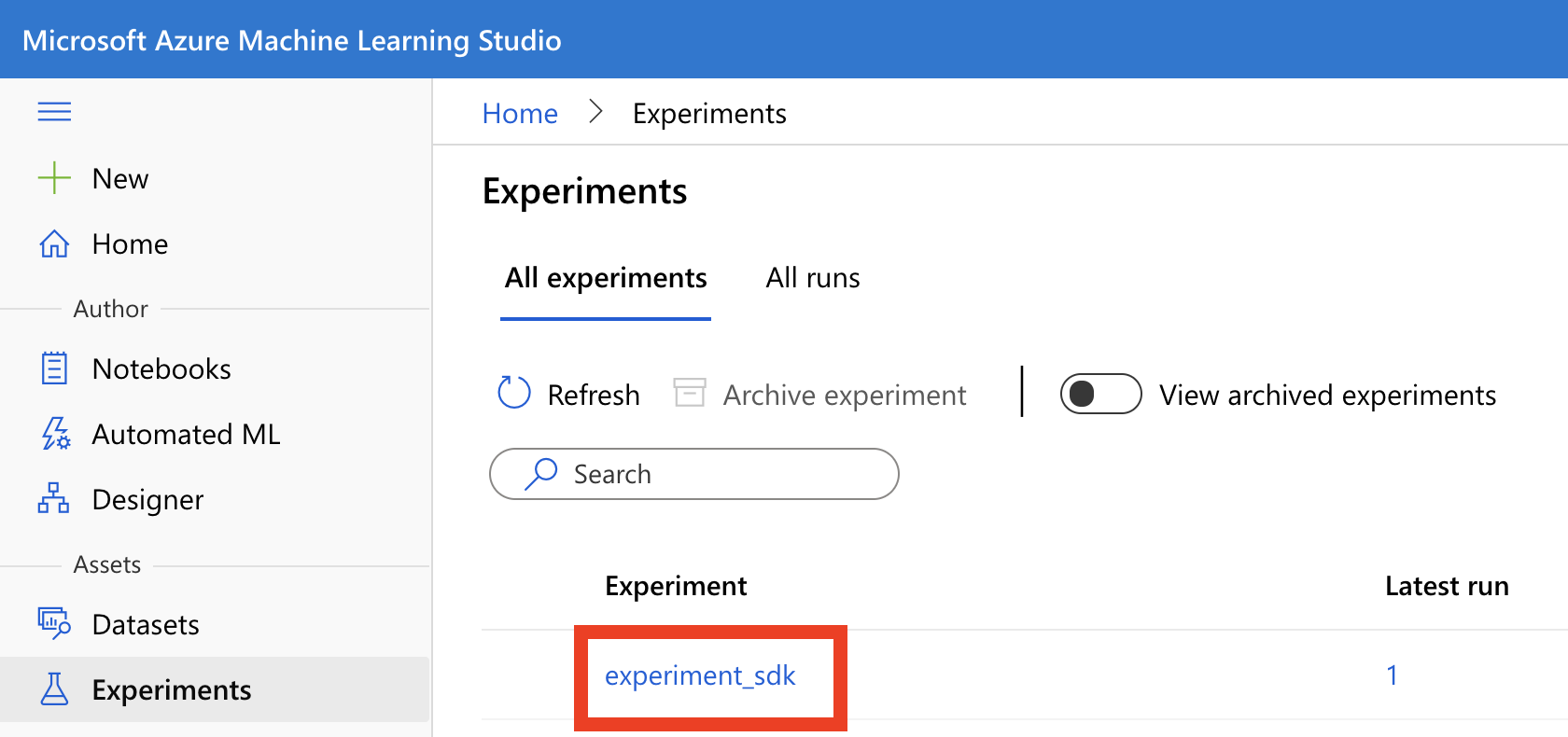
接著我們點進去剛剛建起來的實驗:experiment_sdk,會看到下圖的畫面,有一個 Run 1,Run 的名稱是隨機產生的,可以手動更改。我們點進去這個 Run 1 來看看。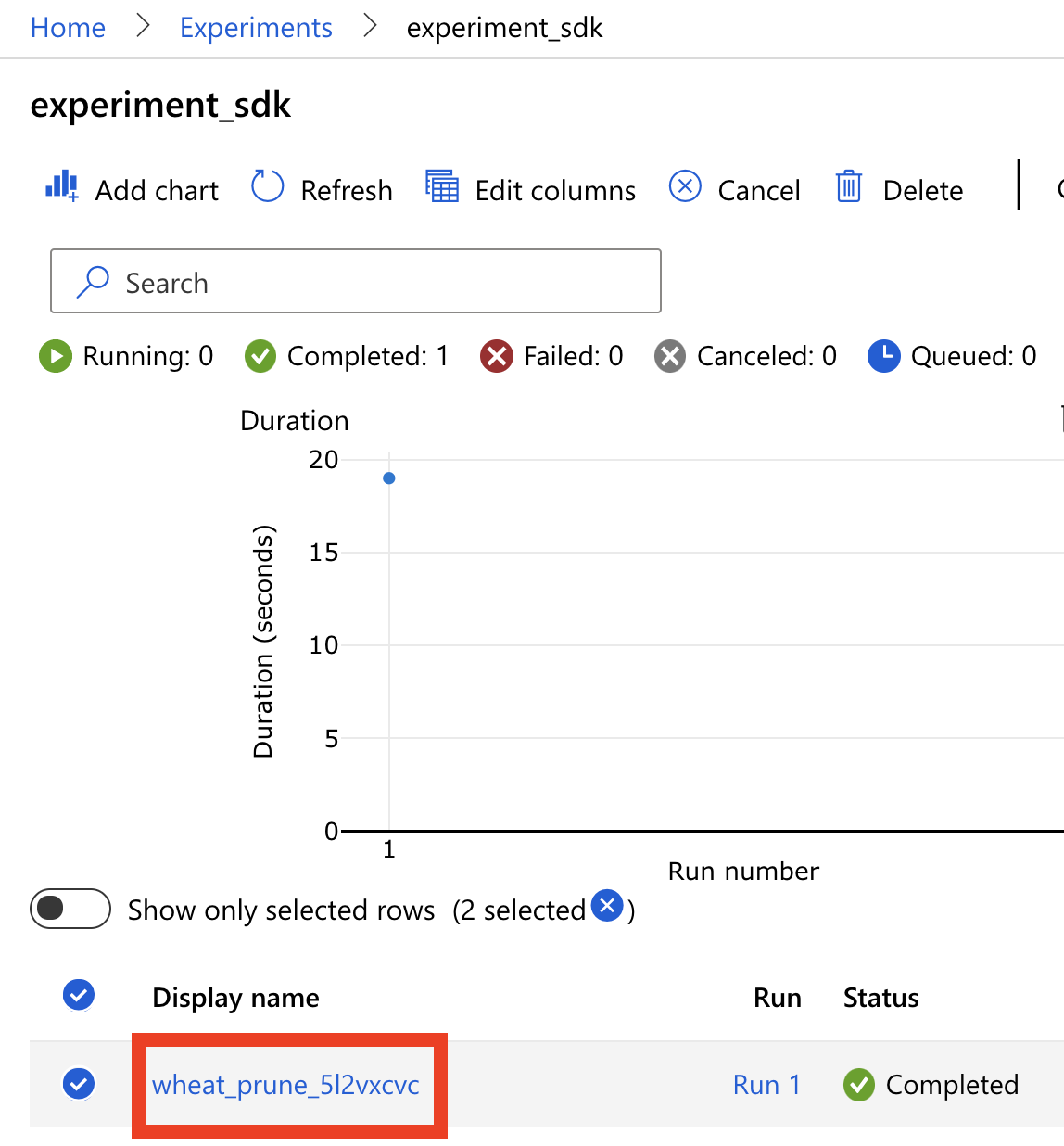
我們進去後,切到 Metrics 的頁簽,可以看到剛剛我們在 log 裡寫的「資料大小」,被寫進去了。這個就是 log 的作用。(其實剛剛在首頁,應該也是看得到這個資料大小的數據哦!)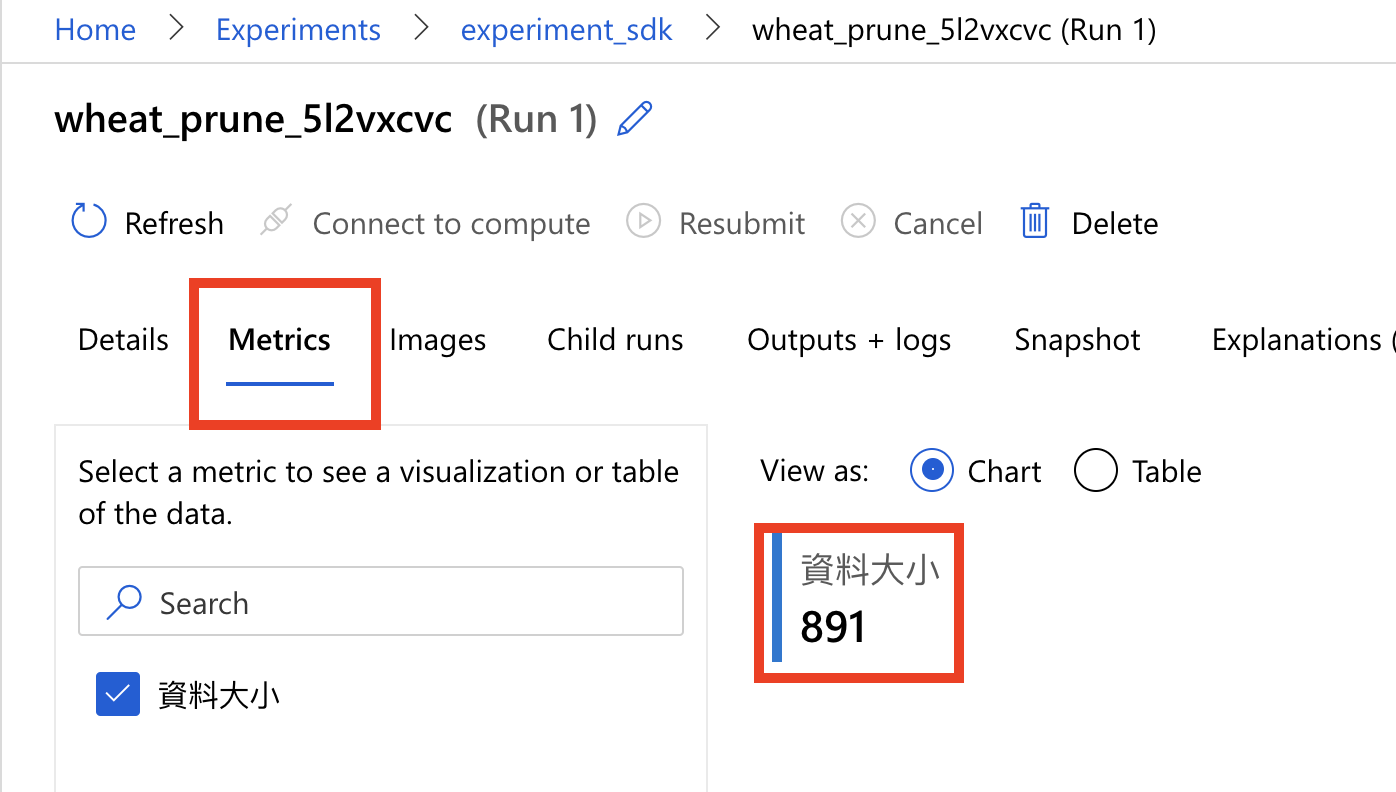
run.log() 的形式有很多種,分別說明如下:
如果是資料科學界的老司機的話,看到這裡記錄 log 的功能,應該會立刻聯想到一款知名的工具 MLflow。沒錯,MLflow 在 AML 的世界裡也是可以使用的哦!必須要安裝兩個套件:pip install mlflow 還有 pip install azureml-mlflow。
MLflow 的用法和原生的幾乎是一樣的,參考程式碼如下:
from azureml.core import Workspace
import mlflow
from mlflow.tracking import MlflowClient
ws = Workspace.from_config()
# 設定 MLflow URI 給 AML
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.create_experiment("mlflow-experiment")
mlflow.set_experiment("mlflow-experiment")
mlflow_run = mlflow.start_run()
mlflow.log_text('mlflow', 'my_log')
mlflow.end_run()
今天的內容有沒有開始覺得困難了呢?不過深入理解的話,會發現這些 SDK 的內容都是很強大的工具。明天我們來講 ScriptRunConfig,還有 Experiment and Run 的另一種使用方式哦!
ps 天啊今天的內容快要3000字了。

