先前在 介紹影像辨識的處理流程 - Day 10 有提到,整個影像辨識的流程如下:
我們已經完成前 5 項工作,現在要進行的是調整影像辨識模型的參數,這些參數的功能主要分成
在進行 YOLOV3 影像辨識訓練前需要準備的有
下圖顯示在 AWS EC2 上的文件夾配置,最上面一層的 fishRecognition 是 python 的虛擬環境,而在這個虛擬環境中包含了一個 Django 專案 (./fishsite),還有它的應用 (./fishsite/fishsite),此外還有先前安裝的 YOLOV3 系統,而為了讓我們的影像辨識系統具體一點,我們另外建立了一個文件夾 FishRecognition ,在這個文件夾裡進行影像辨識的工作。
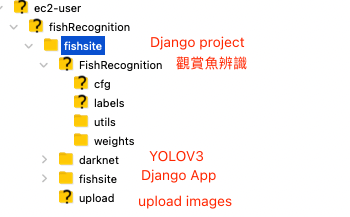
圖 1、AWS EC2 的文件夾配置
以下是 FishRecognition 文件夾的結構,darknet53.conv.74 是 YOLOV3 權重檔,在終端集中透過以下指令就可以下載,統一擺在 weights 這個文架夾中, labels 這個文件夾用來存放影像數據集,包含影像跟標籤文件,這樣一來前三項工作就完成了。
wget https://pjreddie.com/media/files/darknet53.conv.74
├── cfg
│ ├── obj.data
│ ├── obj.names
│ ├── test.txt
│ ├── train.txt
│ └── yolov3.cfg
├── labels
│ ├── 00-frame-608x608-0001.jpg
│ ├── 00-frame-608x608-0001.txt
...
│ ├── 02-frame-608x608-0093.jpg
│ └── 02-frame-608x608-0093.txt
├── utils
│ └── generatetrain.py
└── weights
└── darknet53.conv.74
數據集設定檔
obj.data 是主要的數據集設定檔,內容如下:
obj.data
classes = 3
train = cfg/train.txt
valid = cfg/test.txt
names = cfg/obj.names
backup = weights/backup
參數說明:
train.txt 跟 test.txt 的內容其實就是 labels 文件夾內的檔案,我們要從 labels 文件夾內的檔案來產生 train.txt 跟 test.txt,於是我們寫一個簡單的程式,來自動生成這兩個檔案,放在 utils 文件夾中。
generatetrain.py
#!/usr/bin/env python3
import glob
import os
from os import listdir, getcwd
import random
import numpy as np
# 影像數據集的文件夾
input_path = './labels/'
# 生成訓練跟驗證文件的文件夾
cfg_path = './cfg/'
# 設定訓練與驗證的比例為 0.8, 0.2
train_ratio = 0.8
if os.path.isdir(input_path):
types = os.path.join(input_path,'*.jpg'), os.path.join(input_path,'*.jpeg'), os.path.join(input_path,'*.png')
files_grabbed = []
for files in types:
files_grabbed.extend(sorted(glob.iglob(files)))
elif os.path.isfile(input_path):
files_grabbed = [input_path]
else:
raise ValueError("File PATH is NOT Valid")
train_file = open('%s/%s.txt' % (cfg_path, 'train'), 'w')
test_file = open('%s/%s.txt' % (cfg_path, 'test'), 'w')
trainNum = int(len(files_grabbed) * train_ratio)
random.shuffle(files_grabbed)
train_file.write("\n".join(files_grabbed[:trainNum]))
test_file.write("\n".join(files_grabbed[trainNum:]))
下圖是 cfg/test.txt 的內容

圖 2、驗證集文件的內容
以下是要辨識的觀賞魚名稱,請特別注意順序,以上圖來說 02-frame-608x608-0038.jpg 就是 Cichlasoma var. Kilin Parrot (麒麟鸚鵡)觀賞魚,因為依照順序 0, 1, 2 下來,對應到的就是編號 2 。可能有人會覺得 YOLOV3 是依照檔名來得知編號嗎?不是的,最上面的檔案結構中就有顯示,每個圖檔都會對應一個 YOLO 標籤文件檔,這個文件檔中就有顯示方塊框中的物件編號
cfg/obj.names
Altolamprologus compressiceps
Chilotilapia rhoadesii
Cichlasoma var. Kilin Parrot
02-frame-608x608-0038.txt
2 0.264803 0.469572 0.180921 0.097039
2 0.098684 0.523849 0.177632 0.083882
2 0.513158 0.471217 0.177632 0.083882
2 0.754934 0.478618 0.167763 0.088816
2 0.833882 0.612664 0.134868 0.110197
2 0.735197 0.585526 0.072368 0.131579
2 0.571546 0.622533 0.205592 0.097039
2 0.591283 0.539474 0.156250 0.072368
2 0.386513 0.593750 0.085526 0.131579
2 0.173520 0.603618 0.077303 0.141447
2 0.235197 0.586349 0.062500 0.143092
2 0.069079 0.634046 0.128289 0.106908
影像辨識模型設定檔
影像辨識模型設定檔可以根據需要,可以使用 coco,yolo3-tiny,或是 yolov3 都可以,都有已經調適到最佳參數的設定檔,下圖就是安裝 darknet 套件所附的相關設定檔,我們選擇 yolov3.cfg ,並修改部分設定以適合我們的配置。
圖 3、影像辨識模型設定檔
確認圖片大小,batch 參數是指每批次取幾張圖片進行訓練,subdivisions 參數是指要將每批次拆成幾組,這樣的設定是每次處理 4 張圖片,要考慮速度與避免 GPU 記憶體不夠兩者來權衡。
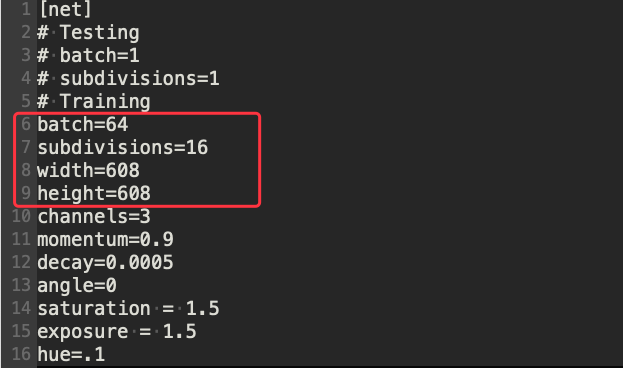
圖 4、YOLO 影像辨識模型設定檔 1
設定要判別的觀賞魚種類數量,因為我們只有提供 3 種,所以在 610 行的 classes 要改成 3 ,而上面捲積層的過濾器(603 行)也要相對應的改成 filters=24 這是因為公式如下:
(classes + 5)*3 = >(3+5)*3
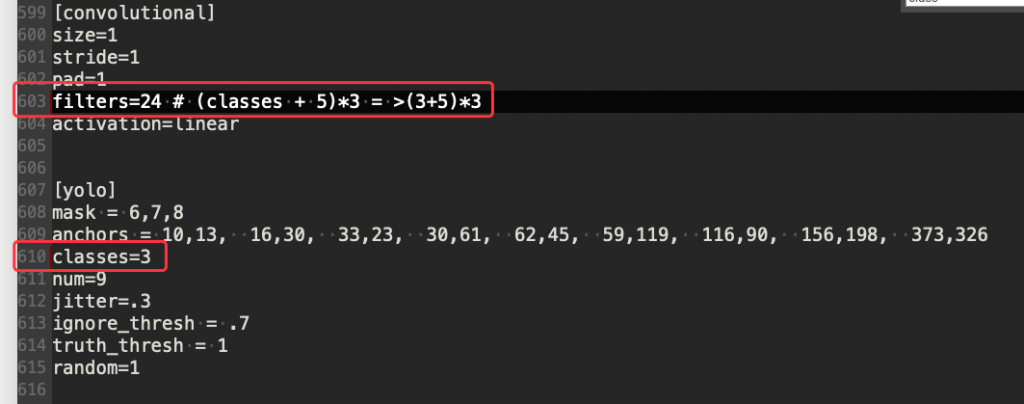
圖 5、YOLO 影像辨識模型設定檔 2
總共有四個地方要改,分別是行 689, 696, 776, 783,修改內容如上,所以就不一一截圖。
設定完畢後就可以進行訓練,輸入下列指令進行訓練,後面的 tee 指令是用來將訓練時的輸出結果儲存在 trainRecord.txt 這個檔案,好作為後來檢查訓練時的收斂程度。
../darknet/darknet detector train cfg/obj.data cfg/yolov3.cfg weights/darknet53.conv.74 | tee -a trainRecord.txt
下圖是訓練時的輸出結果,我們需要根據這個結果來觀察何時需要停止訓練,1278 是疊代的次數,通常需要訓練 6000-9000 次左右,avg. 前面的數字是平均損失,也就是所有機器學習或是深度學習用來判斷是否貼近實際值的一個判斷依據,越小表示越貼近實際值,越大表示還沒有收斂,通常是 0.06-0.6 之間就表示已經訓練的差不多了。後面表示一次疊代使用了多少訓練時間以及圖片。
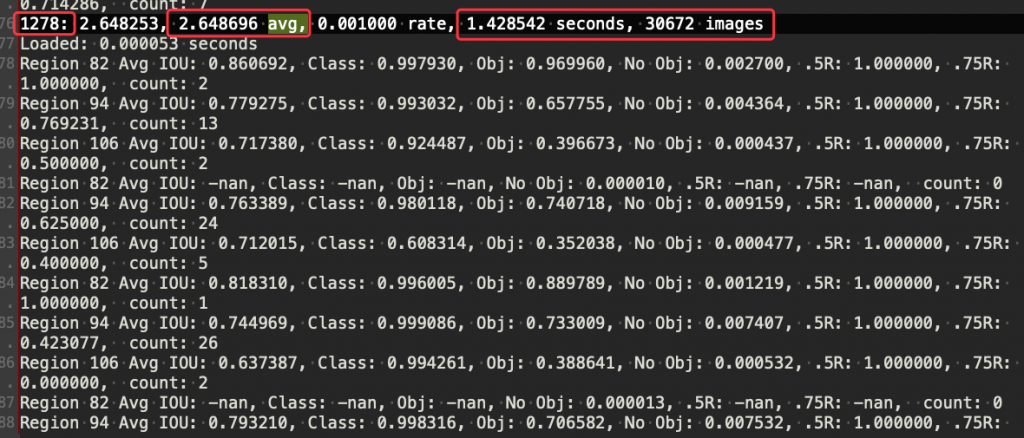
圖 6、訓練影像辨識模型的輸出

