OCR x Pytesseract

在 Python 中, 使用 OCR (Optical Character Recognition , 字元辨識)
將圖片的內容轉換成一般的文本,非常簡單。
只要將相關軟體 與 Python 套件安裝完成後,即可運行程式,
這份文件就是將之前的踩坑過程記錄下來,以供想後續想要研究的開發者可以快速上手。
https://gitlab.com/GammaRayStudio/DevDoc/-/blob/master/Python/004.PythonOCR.md
https://gitlab.com/GammaRayStudio/Program/PythonStudio/SE/PythonOCR
轉換目標
圖片

文字
English
Gamma Ray Studio
English Text
Text Text Text ~ !!!
圖片

文字
繁體中文
Gamma Ray 軟體工作室
中文 文字
文字 文字 文字 ~ !!!
圖片

文字
简体中文
Gamma Ray 软体工作室
中文 文字
文字 文字 文字 ~ !!!
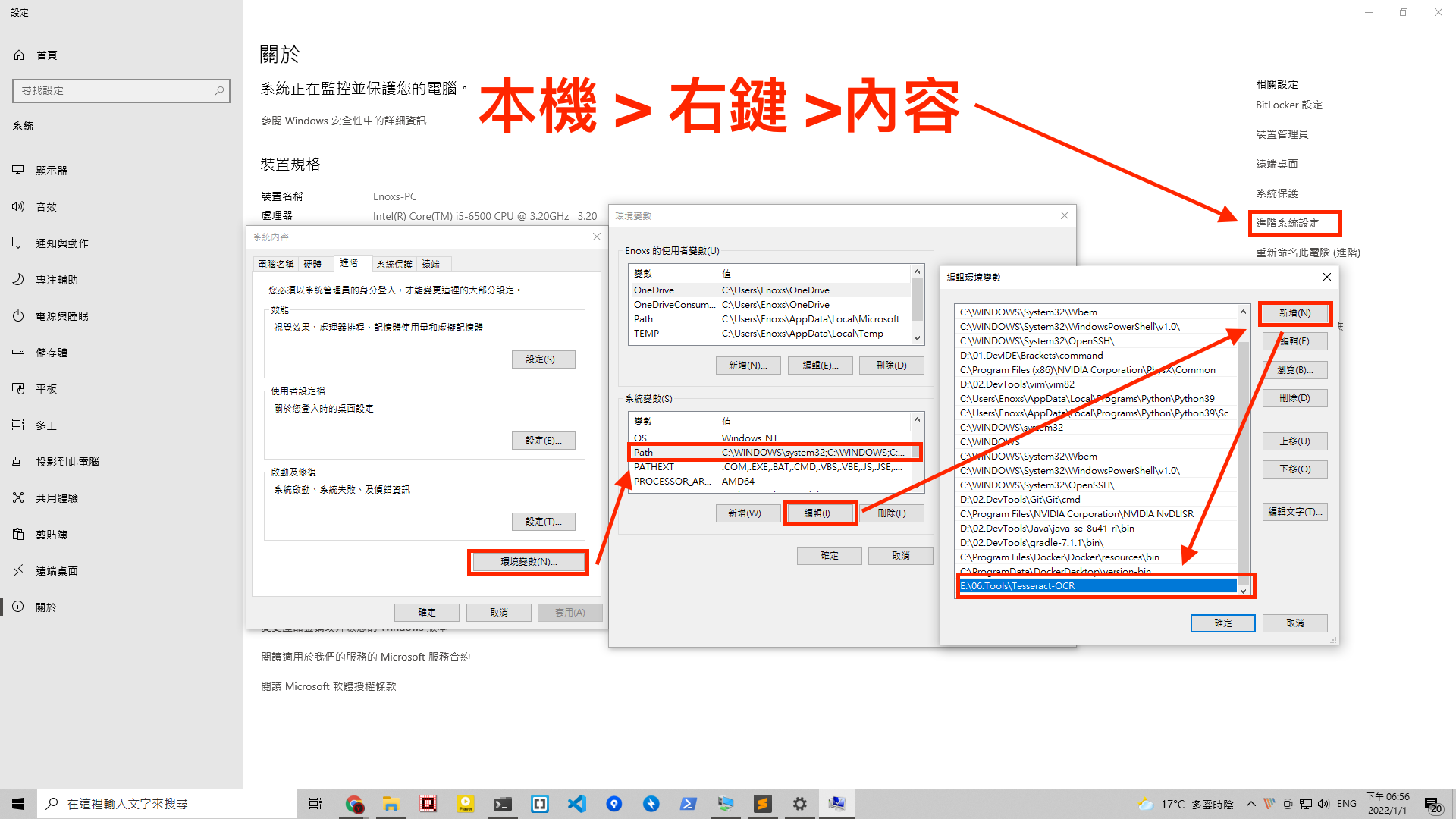
環境變數
brew install tesseract
apt-get install tesseract-ocr
tesseract -v

python -V
Python 3.8.5
pip3 install Pillow
pip3 install pytesseract
from PIL import Image
import pytesseract
img_name = './001.en-us.png'
img = Image.open(img_name)
text = pytesseract.image_to_string(img, lang='eng')
print(text)
Pillow
Pytesseract
img_name = './001.en-us.png' : 圖片路徑img = Image.open(img_name) : 載入圖片text = pytesseract.image_to_string(img, lang='eng') : 圖片轉文字,使用英文語系Output

English
Gamma Ray Studio
English Text
Text Text Text ~ 11!
1 ,但基本上大部分都辯認得出來from PIL import Image
import pytesseract
img_name = './002.zh-cht.png'
img = Image.open(img_name)
text = pytesseract.image_to_string(img, lang='eng')
print(text)
img_name = './002.zh-cht.png' : 調整載入的圖片 中文
Output
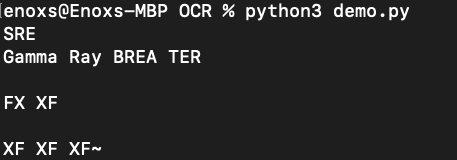
SRE
Gamma Ray BREA TER
FX XF
XF XF XF~
https://github.com/tesseract-ocr/tessdata_best
eng.traineddata
chi_tra.traineddata
chi_sim.traineddata
以 Mac 為例
Tessdata 程式路徑
/usr/local/Cellar/tesseract
語言包路徑
/usr/local/Cellar/tesseract/4.1.3/share/tessdata
/share/tessdata 路徑,就可以生效獨立資料夾
C:\DevTools\tessdata
環境變數

/Users/Enoxs/DevTools/tessdata
.zprofile
# TESSDATA
export TESSDATA_PREFIX=/Users/Enoxs/DevTools/tessdata
.bash_profile
# TESSDATA
export TESSDATA_PREFIX=/Users/enoxs/DevTools/tessdata
from PIL import Image
import pytesseract
img_name = './002.zh-cht.png'
img = Image.open(img_name)
text = pytesseract.image_to_string(img, lang='chi_tra+eng')
print(text)
img_name = './002.zh-cht.png' : 調整載入的圖片 繁體中文
text = pytesseract.image_to_string(img, lang='chi_tra+eng') : 圖片轉文字,使用繁體中文與英文
eng
chi_tra
chi_sim
無 Code Review ,Free Style
執行 ocr.py
將 image 資料夾內的圖片轉換成文字,
並且依據原始檔案名稱,保存在 text 資料夾中

from PIL import Image
import pytesseract
import os
from os import listdir
from os.path import isfile, join
def ocrText(fileName):
img = Image.open(fileName)
# text = pytesseract.image_to_string(img, lang='eng')
# text = pytesseract.image_to_string(img, lang='eng+chi_tra')
text = pytesseract.image_to_string(img, lang='eng+chi_tra+chi_sim')
return text
def replaceText(str):
str = str.replace(",", ",")
text = str.replace(" ", "")
return text
def save(fileName, text):
print("text.length => ", len(text))
with open(fileName, 'w', encoding='UTF-8') as f:
f.write(text)
f.close
def main():
path = '.' + os.sep + 'image'
lstFile = [f for f in listdir(path) if isfile(join(path, f))]
for f in lstFile:
if '.png' in f:
idx = f.find('.png')
out_name = ""
for i in range(idx):
out_name += f[i]
print(out_name)
text = ocrText('.' + os.sep + 'image' + os.sep + '{}'.format(f))
# text = replaceText(text)
path = '.' + os.sep + 'text' + os.sep + out_name + '.txt'
save(path, text)
if __name__ == "__main__":
main()
ocrText() : 將目標圖片轉換成文字replaceText() : 依據需求替換指定文字save() : 將文字保存到指定路徑main() : 整體流程
https://github.com/UB-Mannheim/tesseract/wiki
https://ithelp.ithome.com.tw/articles/10227263
https://www.dotblogs.com.tw/RYNote/2021/01/14/105447
https://www.twblogs.net/a/5c016054bd9eee7aec4ebd26
 Enoxs
Enoxs

{kind=link}