Hi! 大家好,我是Eric,這次要來用Python做回歸模型。

1. 載入套件。
import statsmodels.api as sm #回歸模型套件
import numpy as np #資料處理套件
import pandas as pd #資料處理套件
2. 輸入資料。
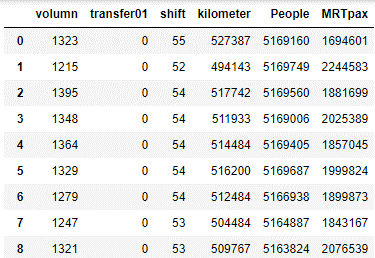
df0 = pd.read_csv("TaipeiAllBus 0105.csv") #輸入資料
df0
3. 資料前處理。
df0_X = df0.drop("volumn", axis=1) #將作為y的變數volunm刪去,並另存為x
df0_X1 = df0_X.drop("transfer01", axis=1) #之後要做相關係數,而因為transfer01變數為虛擬變數,故不須納入做相關係數,故刪除
df0_y = df0[["volumn"]] #製作變數y
4. 相關係數檢驗。
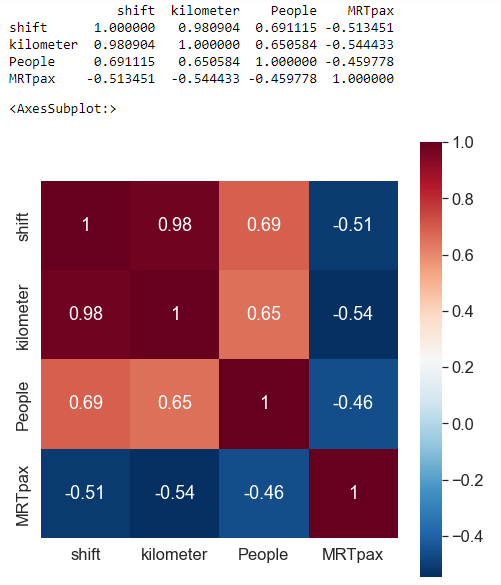
rDf0 = df0_X1.corr() #查看數據間的相關係數
print(rDf0)
%matplotlib inline
sns.set(font_scale=1.5)
sns.set_context({"figure.figsize":(8,8)})
sns.heatmap(data = rDf0, square = True, cmap="RdBu_r", annot = True)
5. 檢視資料分布情形。
import seaborn as sns #載入分布圖形套件
import matplotlib.pyplot as plt #載入畫圖套件
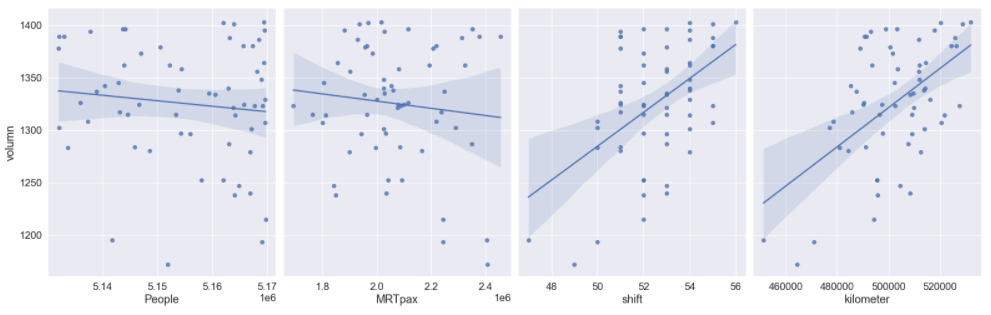
sns.pairplot(df0, x_vars=["People","MRTpax", "shift", "kilometer"], y_vars='volumn', size=7, aspect=0.8, kind='reg')
plt.show()
6. 建模。
df0_X = sm.add_constant(df0_X) #增加模型的常數,使更為符合回歸模型
model0 = sm.OLS(df0_y, df0_X) #OLS回歸
results0 = model0.fit()
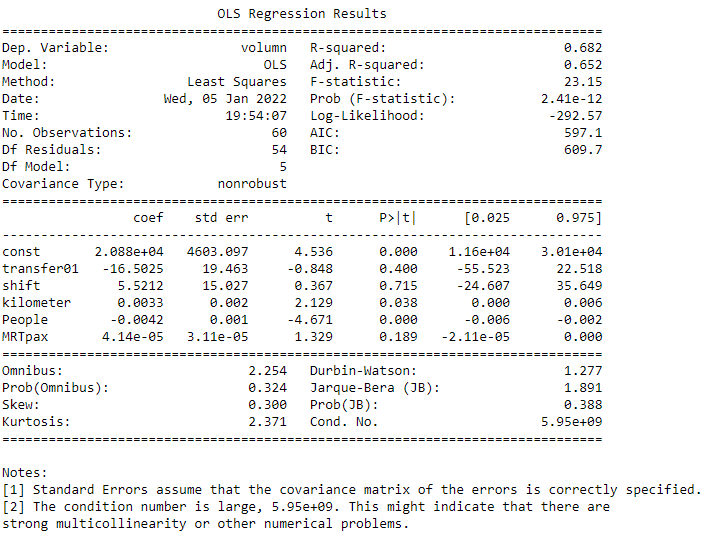
print(results0.summary())
7. 大功告成。
下圖就是回歸的結果,可以看到各個x變數的係數,以及P值,檢驗哪些x變數對於y具有顯著影響,另外也可由R2檢驗模型的解釋能力。
 Eric HSIEH
Eric HSIEH

 iThome鐵人賽
iThome鐵人賽