在篩選字串時,有不少選擇提供我們使用,除了使用常見的直接比對字串的 includes 之外,還有 Regular Expression(以下簡稱 RegExp)及match 可以使用,他們的使用方法為何?我們到底該用誰?,今天94要來pk啦!看完這篇文章可以幫助你釐清自己比較適合用哪一個及他們之間的不同.
本文章會簡單介紹includes,RegExp及match,如果想直接知道結果可以直接從match vs RegExp vs includes開始看
此範例使用 indexOf 及 RegExp 進行 PK,可以了解不同瀏覽器執行結果不同的事實(如果你過去很喜歡使用 RegExp 請先冷靜點,並且不要在排斥使用 safari 開發了)
圖片來源
這邊可以測試一下自己愛用的瀏覽器
下圖為個人電腦在 Chrome 及 Safari 使用 measurethat.net 執行後的結果,分別是左方的 Chrome(version 98.0.4758.80)及右方的 Safari(version 15.1)
可以看出雖然 test 及 includes 在 Chrome 表現的比較好,不過 match 則是 Safari 表現得比較好
在 filter 輸入[,\和(都可以把前端搞炸!!!!? but why?
原因為在正規表示式中有'['開頭 就一定要有']'結尾,'('同理,也一定要有')'結果,而''則是要使用另一個''結尾或其餘特殊字元表示法,在了解 RegExp 的規則後,介紹一下常見的 method 分別是 test 和 exec
[的詳細說明
(的詳細說明
\的詳細說明
test:檢查字串中是否有符合的部分,有的話回傳 true 沒有則回傳 false
const str = 'hello';
const str2 = 'hello2';
// 尋找字串中有有lo的結果
const regex = new RegExp('lo');
// 尋找字串中有有Lo或lo的結果
const regexAddFlags = new RegExp('LO', 'i');
// 尋找字串中有有0~9的結果
const regexUseSpecialChar = new RegExp(/\d/);
console.log(regex.test(str));
// expected output: true
console.log(regex.test(str2));
// expected output: true
console.log(regexAddFlags.test(str));
// expected output: true
console.log(regexAddFlags.test(str2));
// expected output: true
console.log(regexUseSpecialChar.test(str));
// expected output: false
console.log(regexUseSpecialChar.test(str2));
// expected output: true
exec:檢查字串中是否有符合的部分,有的話以陣列的方式回傳,沒有則回傳 null
const str = 'hello';
const str2 = 'hello2';
// 尋找字串中有有lo的結果
const regex = new RegExp('lo');
// 尋找字串中有有Lo或lo的結果
const regexAddCaseInsensitive = new RegExp('LO', 'i');
// 尋找字串中有有0~9的結果
const regexUseSpecialChar = new RegExp(/\d/);
console.log(regex.exec(str));
// expected output: ["lo"]
console.log(regex.exec(str2));
// expected output: ["lo"]
console.log(regexAddCaseInsensitive.exec(str));
// expected output: ["lo"]
console.log(regexAddCaseInsensitive.exec(str2));
// expected output: ["lo"]
console.log(regexUseSpecialChar.exec(str));
// expected output: null
console.log(regexUseSpecialChar.exec(str2));
// expected output: ["2"]
和 RegExp 的 test 很類似,都是檢查字串中是否有符合的部分,有的話回傳 true 沒有則回傳 false,不同的是不能使用 Flag 或是正規表示的內容(如上面範例中的'/\d/').因此,想要達到 RegExp 不區分大小寫的搜尋法可能要搭配 toUpperCase 或 toLowercase 才能達到,在 code 裡看起來會比較囉唆一些
const str = 'hello';
console.log(str.includes('lo'));
// expected output: true
console.log(str.includes('Lo'));
// expected output: false
const strToUpperCase = 'hello'.toUpperCase();
console.log(strToUpperCase.includes('lo'.toUpperCase()));
// expected output: true
console.log(strToUpperCase.includes('LO'.toUpperCase()));
// expected output: true
和 RegExp 的 exec 很類似,都是檢查字串中是否有符合的部分,有的話以陣列的方式回傳,沒有則回傳 null,同樣可以使用正規表示的內容(如上面範例中的'/\d/')但不能使用 Flag.因此,想要達到 RegExp 不區分大小寫的搜尋法可能要搭配 toUpperCase 或 toLowercase 或是使用正規法式法才能達到,在 code 裡看起來會比較囉唆一些
const str = 'hello';
const str2 = 'hello2';
console.log(str.match('lo'));
// expected output: ["lo"]
console.log(str.match('Lo'));
// expected output: null
console.log(str2.match(/\d/));
// expected output: ["2"]
const strToUpperCase = 'hello'.toUpperCase();
console.log(strToUpperCase.match('lo'.toUpperCase()));
// expected output: ["LO"]
console.log(strToUpperCase.match('LO'.toUpperCase()));
// expected output: ["LO"]
終於看完了他們三個的使用介紹覺得講了那麼多廢話 我只想知道到底該用哪個而已的人請冷靜點,接著就是最重要的 PK 環節了,不過在三個大 PK 之前,我們先拿 match 跟 RegExp 進行 PK 就好
我們先來看一張 match 和 RegExp 的比較圖
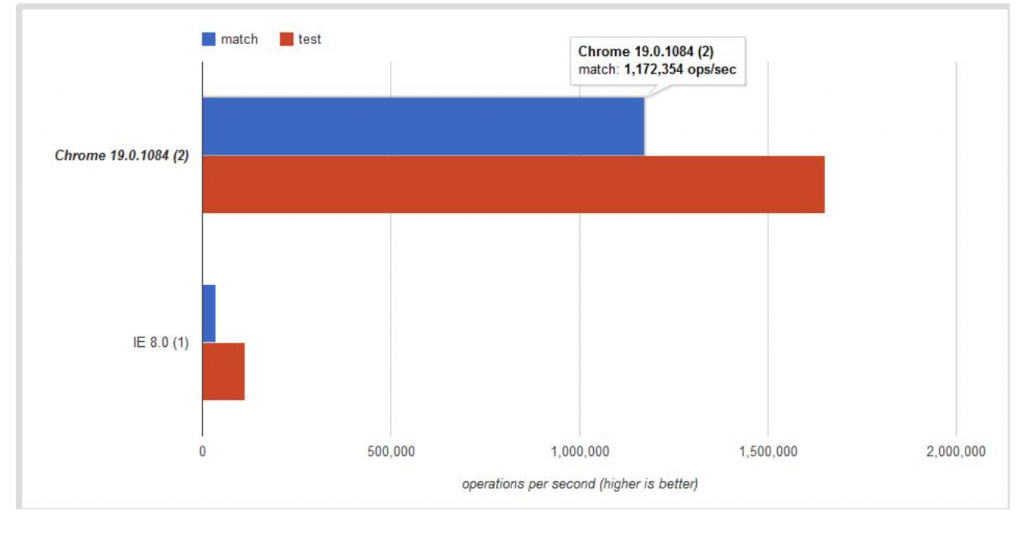
(ops/sec = operate per second)
圖片來源
MDN告訴我們以下三點:
參考資料:來自 MDN 的金玉良言
懶人包:如果只想知道是否符合條件的話就用test,如果想知道第一個及全部符合的是誰都用exec即可.
看完了 match 和 RegExp 我們在把 includes 加進來一起做比較,下面有兩張圖,我們一張一張看
在第一張圖中 RegExp 我們執行了兩次分別是有加入 Flag 和沒有加入的,可以在圖中其實兩者的表現並沒有相差太多
在整理後的表現優劣排名為:includes>RegExp(沒有 Flag)>RegExp(有 Flag)>match.
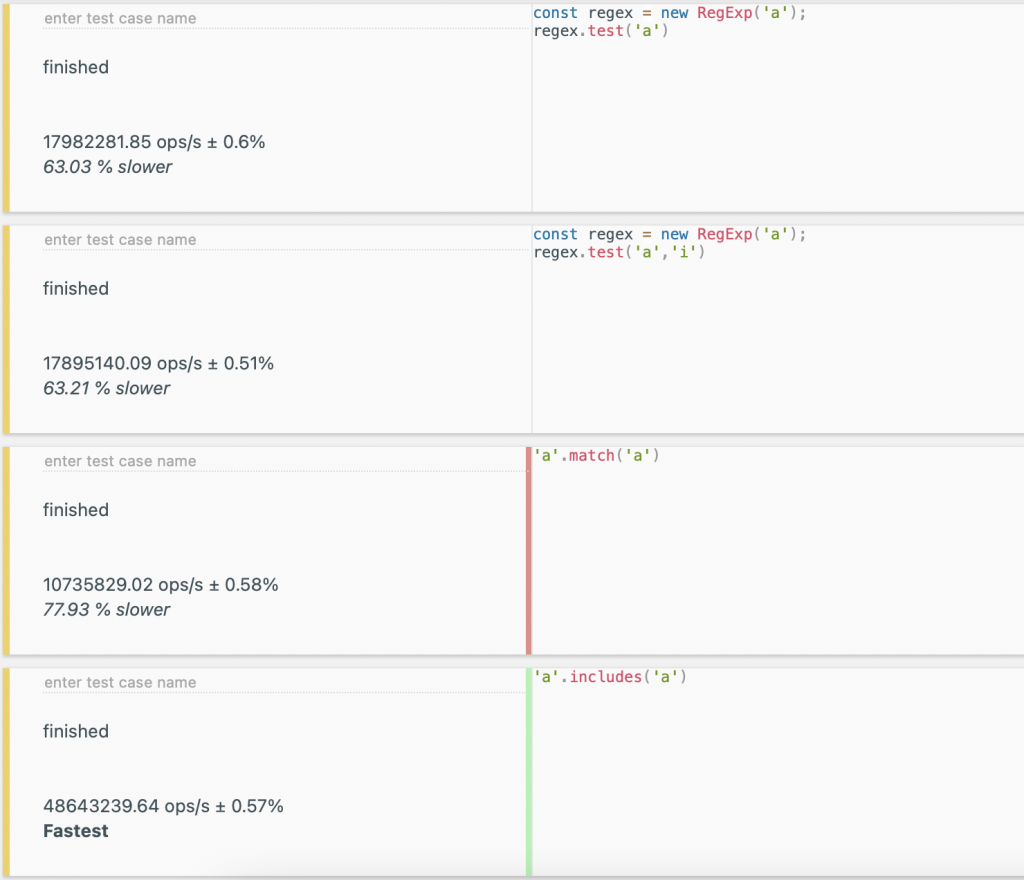
但是在第二張圖中的排行結果竟然變成:RegExp(有 Flag)>RegExp(沒有 Flag)>match>includes.
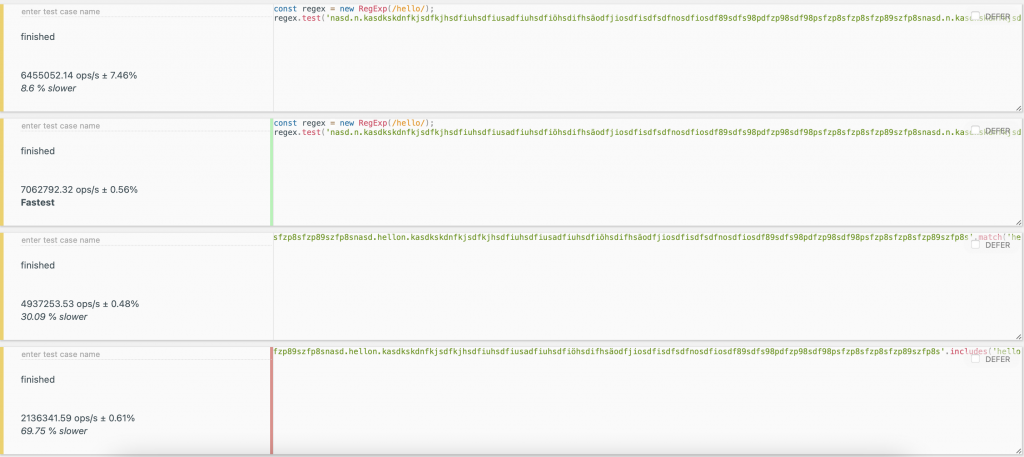
P.S. 以上結果皆是使用 JSBench.Me 測試的結果
講了那麼多,我們確定了 match 和 RegExp 在 MDN 的建議下,我們該使用 RegExp,但 includes 和 RegExp 到底該用誰比較好?
個人的觀點是,RegExp 和 includes 用誰都好,了解使用情境比較重要,在 Select 類型的搜尋可以大膽的使用 RegExp.但使用 input 提供使用者輸入關鍵字搜尋時,請避免會造成 RegExp 錯誤的符號出現在畫面上,可能會引導使用者在搜尋時輸入,進而導致頁面爆炸的悲劇發生,畢竟我們沒辦法控制使用者照著我們期望方式的輸入.
說了那麼多,若執意(明知山有虎,偏向虎山行)要使用RegExp請記得遵照以下武林秘笈
武林秘笈:
Escaping user input that is to be treated as a literal string within a regular expression—that would otherwise be mistaken for a special character—can be accomplished by simple replacement:
function escapeRegExp(string) {
return string.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'); // $& means the whole matched string
}
// 先看只使用一個'['會出錯的範例,在經過武林秘笈的調教後,功能的正常
const replaceStr ='[123'.replace(/[.*+?^${}()|[\]\\]/g, '\\$&')
const regex = new RegExp(replaceStr);
console.log(replaceStr)
// expected output: "\[123"
console.log(regex.test('[123'));
// expected output: true
console.log(regex.test('[1223'));
// expected output: false
// 開始耍白爛丟一堆原本會出錯的'['跟'(',也在經過武林秘笈的調教後,非常的正常
const replaceStr2 ='[123([('.replace(/[.*+?^${}()|[\]\\]/g, '\\$&')
const regex2 = new RegExp(replaceStr2);
console.log(replaceStr2)
// expected output: "\[123\(\[\("
console.log(regex2.test('[123([('));
// expected output: true
console.log(regex2.test('[123('));
// expected output: false
// 以上看起來都很美好,不過實際上還是有些特殊的例子
// 例如下面的範例 其實我們不希望'a\[123'被找出來 但它還是會被找到.此外,只輸入一個'\'還是會讓js直接爆炸
const replaceStr3 = 'a['.replace(/[.*+?^${}()|[\]\\]/g, '\\$&') // "a\["
const replaceStr4 = 'a\['.replace(/[.*+?^${}()|[\]\\]/g, '\\$&') // "a\["
const regex3 = new RegExp(replaceStr3);
console.log(replaceStr3 === replaceStr4)
// expected output: true
console.log(regex3.test('a[123'));
// expected output: true
console.log(regex3.test('a\[123'));
// expected output: true
 zyx
zyx
