Day18提到了數字與文字辨識的機器學習。
然而實際上,我們應該進一步考慮圖片的每個像素權重與各個像素間彼此的關聯性。
舉例來說,一張帶有數字的圖片,在中心區塊的權重(紅圈處)理當明顯比角落的權重要高。
卷積神經網路 (CNN) 是一種前饋神經網路 (Feedforward Neural Network)。
藉影像處理,從圖片中萃取特徵,使特徵抽象化 (Abstraction),從而更準確辨識影像。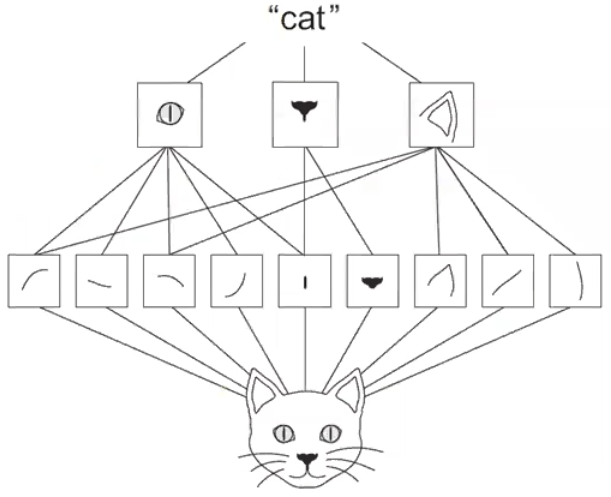
常由多個卷積層與池化層 Convolution & Pooling;和全連接層 Fully Connected 組成。
此結構使 CNN 與其他深度學習相比,在圖像和語音辨識表現得更好。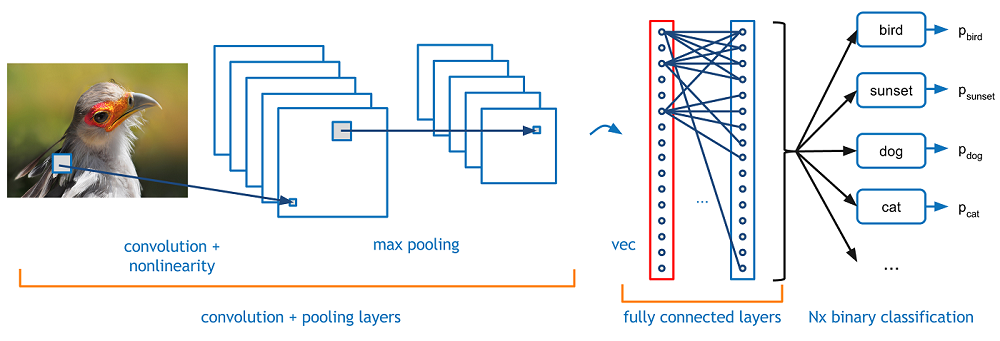
原圖網址
CNN 有兩大假設
即是每個神經元僅接收上一層部分神經元的傳導,又稱 Receptive Field 感知域。
每個感知域對下一隱藏層均使用相同的權重,即 Feature Detector 也稱 Filter。
即是將 "Input" 與 "Filter" 以 numpy nd array 的方式相乘後加總
假設今天我們有一個 7*7 的 input image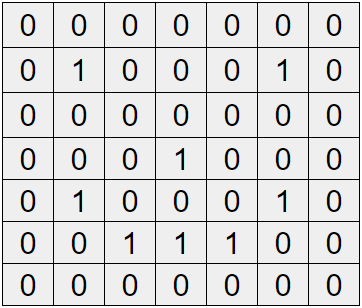
我們使用一個 3*3 的 Feature Detector(又稱 Filter)stride=1, 1 來轉換: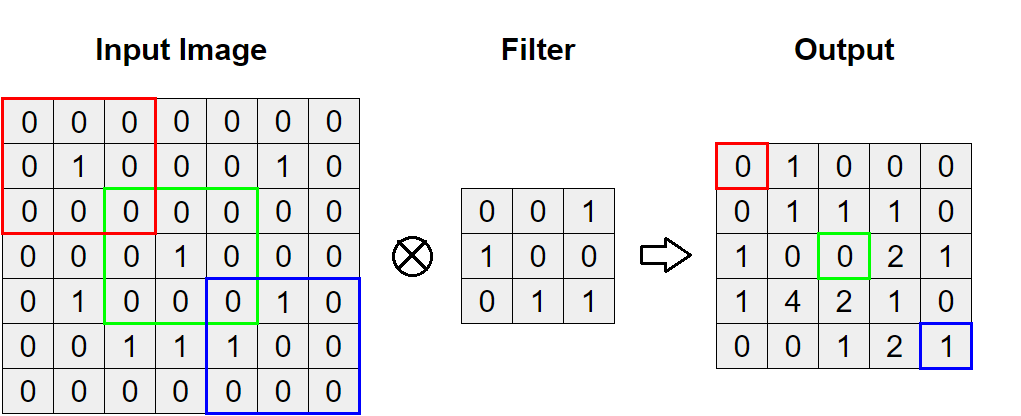
實例上,我們常用卷積運算萃取物體邊界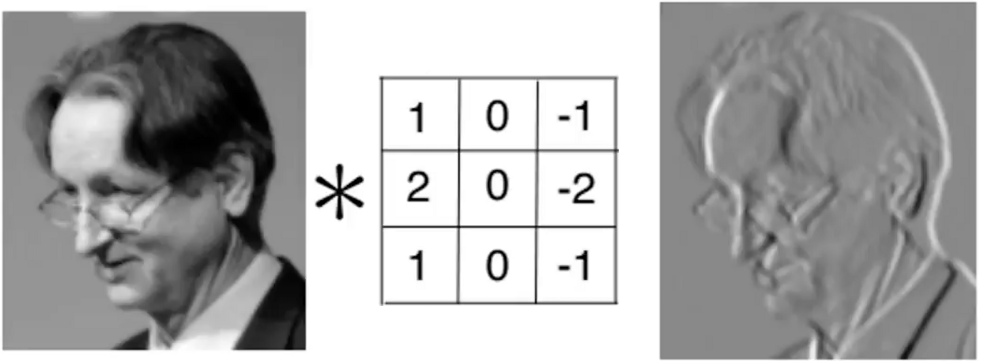
甚至搭配 Relu 函數,進一步淬煉物體形狀(因負值都變成 0,輪廓更顯著)
除上述自訂的 Filter,也很常使用以下幾種濾波器:




tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), strides=(2, 2), padding='same', activation='relu')

若說卷積層是用來萃取「精華」,那麼池化層就是用來「壓縮並保留」重要資訊的方法。
以上例延伸,使用較常見的 Max Pooling(另一種為 Avg),對 2*2 的範圍 stride=2, 2 取最大值: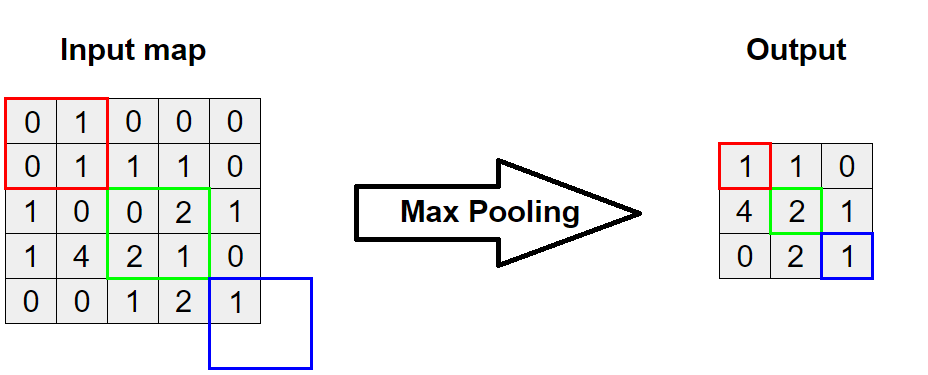
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')
即是將結果平坦化後連接,概念就像是把 2D 的圖片拍扁變成 1D 的數列。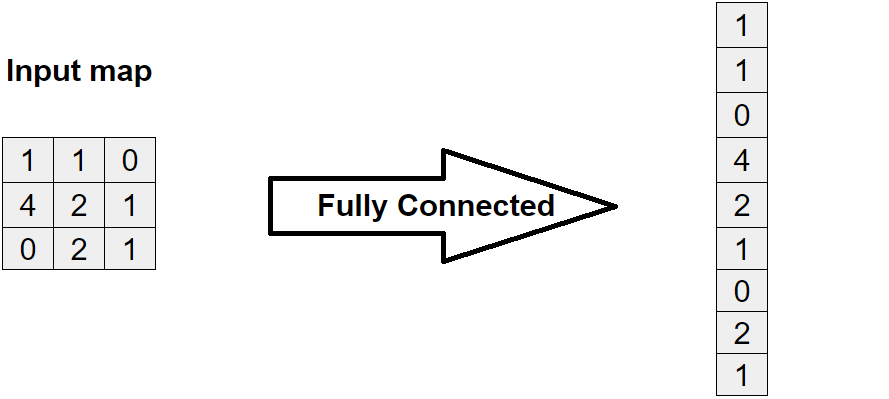
講完了概念,接著我們用 Tensorflow 官網的範例來演練一下。
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)

原本的 mnist 的資料已經很乾淨,因此實作的準確度本身就已相當高。
接著我們試著用 CNN 的方式來撰寫:
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train_norm, x_test_norm = x_train / 255.0, x_test / 255.0
首先,要把 x 增加一維在最後面,因為 CNN 要多一個表示顏色的維度
x_train = x_train.reshape(*x_train.shape, 1)
x_test = x_test.reshape(*x_test.shape, 1)
x_train.shape, x_test.shape
>> ((60000, 28, 28, 1), (10000, 28, 28, 1))
建模
model_cnn = tf.keras.Sequential([
tf.keras.Input(shape=(28, 28, 1)),
tf.keras.layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation="softmax"),
])
優化器設定:與前面同樣使用 Adam、交叉熵做損失函數,關鍵指標則看準確率。
model_cnn.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
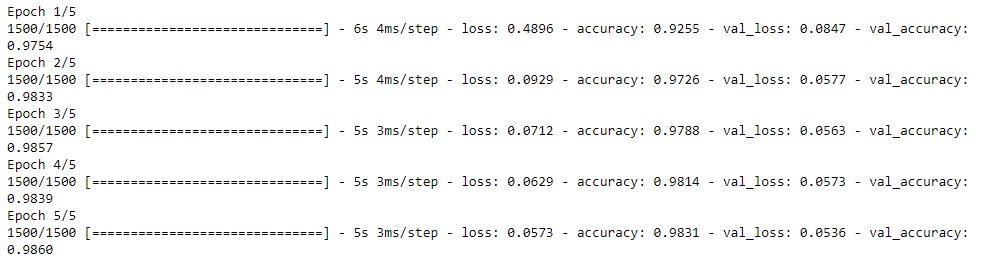
history = model_cnn.fit(x_train, y_train, epochs=5, validation_split=0.2)
 s790502ss
s790502ss

 iThome鐵人賽
iThome鐵人賽