嗨大家!為了呼應今天的標題,讓我請出國小課本裡面被用來強調標點符號重要性的短句來問候各位。
下雨天留客天留我不留
請試著在這個短句裡面加上標點符號或是空格來明確你認為這句話是什麼意思~如果是跟我用同一個版本的國文課本的人應該知道這句話有很多不同的解讀方法吧XDD 這邊就提供一下我自己想到的幾個解讀方式,如果有其他的解讀也歡迎在留言處分享~
從上面三個例子裡面,大家應該可以感受到斷詞跟斷句的重要性了吧。因為語言是充滿歧異性的東西,根據我們選擇在一段文字當中的哪些地方分出詞彙,會得到各種不一樣的解釋。甚至就算選出了同樣的詞彙,也可能會因為一詞多意的關係而產生歧異。所以為了讓電腦可以理解語言,在把data裡面的雜質(沒用的東西)拿掉之後,通常我們要做的第一步就是斷詞-把文字分解成能夠解釋出意思的最小單位(語意學上對詞的定義就是這個)。
那麼斷詞除了對語意理解很重要以外還有什麼重要性呢?當我們拿到很長的一段文章或是大量資料的時候,通常會做什麼事來快速掌握裡面的內容咧?沒錯就是找關鍵字!(至少我是這樣啦)下面是我之前在通識課用slido調查學生學外語的理由收到的回覆。
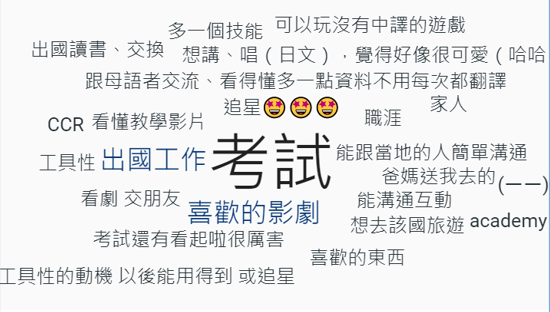
Slido很貼心地提供了文字雲的彙整服務,幫我把頻率比較高的回答放在中間,而且用大小來標示他的頻率之高。但如果仔細看邊緣的一些回答就會發現其實大家講的都是差不多的東西,卻被當作不一樣的回答,好像其實也沒起到很好的統整作用。所以為了可以讓重點更明確一點,我把這些回答丟到python裡面經過斷詞再重新統計詞彙的頻率,然後畫出了下面這個文字雲。

這樣看起來是不是就一目瞭然了呢?就算你對讓電腦理解語意沒有什麼遠大的抱負,如果想要有效率地做資料處理的話,絕對少不了斷詞的技術。
雖然說斷詞在NLP領域裡面是絕對少不了的重要技術,但是根據語言特性的不同,難易度會產生極大的差異(之後有空會寫一篇文章說明不同語言特徵造成的斷詞困難點)。請看下面不同語言裡面一句話的範例:
This is a book.
這是一本書。
これは本です。
第一句的部分要讓大家斷詞的話,基本上應該是一塊蛋糕(?),反正空格的地方就代表詞的邊界嘛。但是第二句跟第三句呢?沒有空格的時候要怎麼辦?先撇開日文不說,中文感覺怎麼斷都可以啊,就算每個字都斷開,他們也都還保有自己的意思。這就是中文斷詞困難的地方。因為是表意文字的關係,每個字都有自己的意思,結合成詞之後又會產生不同的意義,所以比起英文這種用空格來區分詞彙的書寫系統會困難很多。因此NLP的中文斷詞應該怎麼做比較好,至今都沒有什麼定論,而今天會先針對英文斷詞常用的方法進行介紹。但是在開始之前,還有一個重要的概念要介紹。
在語言學當中,如果要我們幫詞彙做分類的話,其中一個方式就是區分實詞(content words)跟虛詞(function words)。所謂實詞指的是我們可以講出實際意思且比較容易納入新詞的詞彙類別,像是名詞、動詞跟形容詞;而虛詞指的是比較難講出實際意思且不太會有新詞的詞彙類別,像是介係詞。如果你看到這邊覺得沒有辦法想像講不出實際意思的詞彙的話,可以想想看英文裡面的"the"跟中文裡面的「的」。而關於新詞,舉例來說,如果我今天告訴大家生物學家發現一種新的植物,然後幫它取名為"blanber",大家應該不會覺得哪裡有問題吧。但是如果我今天告訴大家有一個新的介係詞叫做"fap",如果有東西放在桌上的時候就可以說"The book is fap the table.",這個時候應該就會有點異樣感了。
我特地在這邊提出實詞跟虛詞區別的原因是,在處理斷詞的時候,有一個叫做「停止詞」的存在。剛剛在前面提到,我們斷詞是為了幫助理解內容或是找出重點嘛。如果我們是為了找出重點做斷詞的話,應該是不會需要虛詞出現在斷詞結果裡面。但不巧的是,通常在一篇文章裡面,虛詞作為連接實詞的重要橋梁,出現的次數出奇地高(大家可以找一個中文網頁跟一個英文網頁,然後分別用crtl+G找找看有多少「的」跟"the"。因為這些虛詞實在太過陰魂不散,我們可以在斷詞的時候設置停止詞,讓python幫我們在斷詞的時候就先把這些停止詞排除掉,這樣就可以得到比較乾淨的結果。
這邊需要注意的是,停止詞並不是一個固定不變的群組,我們要根據斷詞的目的去決定哪些東西應該被拿掉,哪些東西應該被留下來。虛詞也不一定就必須被獵到停止詞裡面。如果我們想研究定指(the)對顧客消費的影響,那勢必就得把the留下來。
&esmp;好啦既然英文斷詞是一塊蛋糕,只要從空格的地方把詞分開就好,那我們是不是用split()就可以結束了?當然不是!
string = "I'm fine thank you and you?"
# 輸出
["I'm", 'fine', 'thank', 'you', 'and', 'you?']
如果用split()就可以結束了,那you後面的問號怎麼辦?你說要用regex去掉?也是可以啦,那停止詞呢?不覺得這樣很麻煩嗎?我來介紹一個更棒的東西給你。
NLTK是大家在python裡面做自然語言處理的時候常用的工具,它除了有資料庫可以直接引進python用之外,也有很多小工具可以幫我們事半功倍。今天我們就是要用裡面的tokenize套件來進行斷詞。
因為NLTK不是python內建的套件,所以我們要先把他下載下來。
!pip install nltk
接下來把它引進來之後,要用NLTK裡面的下載器下載nltk裡面的工具。(因為資料龐大,所以會需要一點時間,我自己是花了大概1分鐘左右)
import nltk
nltk.download("all")
完成上面的前置工作之後,我們就可以正式開始斷詞了。先來看看用word_tokenize()斷詞的結果。
nltk.word_tokenize(string)
# 輸出
['I', "'m", 'fine', 'thank', 'you', 'and', 'you', '?']
讚讚!它不只幫我們把問號分離了,還把I跟am分開來,真的不要這麼方便。但你如果以為它只會斷詞的話,你就錯了,它還可以斷句!以下用這篇文章的一個段落來做示範。
paragraph = "A recent TIME investigation into the pregnancy centers found that they have collected vast troves of sensitive personal information about their clients that legal experts say pose a major privacy risk, especially as more states criminalize abortion. Despite presenting themselves in ways that evoke medical clinics and asking clients to sign intake forms that look like those someone might find at a doctor’s office, these crisis pregnancy centers (CPCs) are typically not licensed medical facilities. Their forms and websites often contain fine print that explain they are not bound by federal privacy laws and can share client information with a range of other partners and organizations. Now, citing TIME’s story in their letter, Warren and six other Democrats including Senators Mazie Hirono, Cory Booker, Bernie Sanders, Ron Wyden, Ed Markey, and Richard Blumenthal, want to further examine the centers’ handling of this data."
nltk.sent_tokenize()
# 輸出
['A recent TIME investigation into the pregnancy centers found that they have collected vast troves of sensitive personal information about their clients that legal experts say pose a major privacy risk, especially as more states criminalize abortion.',
'Despite presenting themselves in ways that evoke medical clinics and asking clients to sign intake forms that look like those someone might find at a doctor’s office, these crisis pregnancy centers (CPCs) are typically not licensed medical facilities.',
'Their forms and websites often contain fine print that explain they are not bound by federal privacy laws and can share client information with a range of other partners and organizations.',
'Now, citing TIME’s story in their letter, Warren and six other Democrats including Senators Mazie Hirono, Cory Booker, Bernie Sanders, Ron Wyden, Ed Markey, and Richard Blumenthal, want to further examine the centers’ handling of this data.']
小試身手之後,我們要開始正式進入資料清洗(aka 去掉雜質 aka 拿掉不需要的資料)的步驟。首先我們要把標點符號拿掉,因為這顯然對我們了解段落內容沒有什麼幫助。各位可能在想:「喔天啊,NLTK不是很厲害嗎?為什麼不幫我把標點符號一起拿掉,還要我自己來啊?」這確實可以算是它的一個小缺點(因為R裡面的套件就可以直接調參數拿掉),但NLTK身為家喻戶曉的套件(我是說在用python做NLP的人裡面)當然不是浪得虛名。誠如我一直在強調的,對目的不同的人來說,資料前處理會需要留下跟拿掉的東西都不一樣,所以為了滿足大家各式各樣的需求,NLTK提供了客製化regex斷詞器的功能!下面就讓我來示範一下怎麼應用這個客製化功能除掉標點符號。
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+', gaps = False)
clean_sent = tokenizer.tokenize(string)
print(clean_sent)
這裡出現了之前在介紹套件引入的時候沒有提到的語法,所以稍微說明一下。因為一個套件裡面會包含很多東西,但有的時候我們只需要某個特定功能,而且覺得每次使用這個功能的時候還要一起把套件名字打上去很麻煩的話,可以用from套件import函式的語法來進行。因為RegexpTokenizer是tokenize裡面的功能,如果按照正常程序,我們要打nltk.tokenize.RegexpTokenizer()才能用這個功能,真的太落落長了,所以這邊運用這樣的語法來讓我們的程式碼更簡潔一點(其實是在偷懶)。
接下來簡單說明一下RegexpTokenizer()需要的參數跟用法。裡面放的第一個參數會是你希望它留下來的東西。也就是說,你要告訴它每次遇到非什麼條件的東西就要停下來分割字串。沒錯,基本上跟split()的用法剛好相反,但split()不會幫我們記錄下被拿掉了哪些東西。這也是為什麼會有第二個參數的原因。因為RegexpTokenizer()不只是按照我們的要求把字串斷開,還把被拿掉的東西記起來了,所以我們要用第二的參數gaps告訴它我們想留的到底是第一個參數指涉的東西還是第一個參數以外的東西。基本上這邊default值就是False,只是為了說明地更仔細一點才打出來而已。因此,只有在我們難得想要留下這些東西的時候才會加上gaps = True讓它告訴我們哪些東西被拿來當分割依據了。
然後為了可能還沒完全熟悉正規表達式的朋友們,這邊簡單說明一下,因為\w指涉的是所有英文字母跟數字,所以用\w+當參數剛好可以讓斷詞器既在空白的地方斷掉,又拿掉標點符號。
# 輸出
['I', 'm', 'fine', 'thank', 'you', 'and', 'you']
這邊可以看到標點符號都消失不見了。當然這麼做還是有缺點的,就是I'm的'也不見了。為了保留它的原意,可能還是留著它比較好,所以這邊我們可以針對第一個參數稍作調整。
tokenizer = RegexpTokenizer(r'\w+|\'\w+', gaps = False)
clean_sent = tokenizer.tokenize(string)
print(clean_sent)
# 輸出
['I', "'m", 'fine', 'thank', 'you', 'and', 'you']
完美,這才是我要的結果!咳,我是說清掉標點符號的部分,不要忘記我們還有停止詞要拿掉。
接下來我們要加入停止詞的限制。如果你只是單純想知道文章重點又剛好在煩惱要把哪些詞列為停止詞的話,不用擔心!NLTK有提供我們停止詞字典。NLTK提供的英文停止詞字典裡面有179停止詞。我們把它存出來之後先看一下前50個。
from nltk.corpus import stopwords
stopword = stopwords.words('english')
print(stopword[1:50])
# 輸出
['me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be']
這邊可以看到大部分都是代名詞跟介係詞這些比較沒有實際意義的詞彙。比較可惜的是,NLTK沒有提供一個直接移除停止詞的功能,所以我們要自己寫幾行程式碼。(順便再練習一下if跟迴圈的使用)
BTW,為了等一下可以更直觀地讓大家感受資料清洗的重要性,這邊會多存一個只做過標點符號清理的結果跟完全沒做資料清洗的結果。
raw_result = nltk.word_tokenize(paragraph)
punct_result = tokenizer.tokenize(paragraph)
result = []
for i in punct_result:
if i not in stopword:
token = i
result.append(token)
print(result[1:50])
# 輸出
['recent', 'TIME', 'investigation', 'pregnancy', 'centers', 'found', 'collected', 'vast', 'troves', 'sensitive', 'personal', 'information', 'clients', 'legal', 'experts', 'say', 'pose', 'major', 'privacy', 'risk', 'especially', 'states', 'criminalize', 'abortion', 'Despite', 'presenting', 'ways', 'evoke', 'medical', 'clinics', 'asking', 'clients', 'sign', 'intake', 'forms', 'look', 'like', 'someone', 'might', 'find', 'doctor', 'office', 'crisis', 'pregnancy', 'centers', 'CPCs', 'typically', 'licensed', 'medical']
成功拿掉停止詞之後,我們要用FreqDist()統計一下每個詞到底出現了幾次。使用FreqDist()統計完的資料會被存在字典裡面。
from nltk.probability import FreqDist
fdist = FreqDist(result)
fdist_raw = FreqDist(raw_result)
fdist_nonstop = FreqDist(raw_result)
之前在介紹資料型態的文章裡面也說過,字典本身是沒有順序限制的,所以每次教出來的資料排序都可能會不同。但是我們之所以統計這些東西的數量就是為了知道誰出現的頻率最高嘛,所以這個時候可以使用most_common()來幫忙。(這個命名真的是很直覺,想不記得都難)因為這是FreqDist製作出的字典裡面內建的函式,我們只要在字典後面加上點點,然後在括號裡面輸入我們想看到前幾名的詞就行。
print(fdist.most_common(5))
print(fdist_raw.most_common(5))
print(fdist_nonstop.most_common(5))
[('centers', 3), ('TIME', 2), ('pregnancy', 2), ('information', 2), ('clients', 2)]
[(',', 10), ('and', 6), ('that', 5), ('.', 4), ('centers', 3)]
[('and', 6), ('that', 5), ('centers', 3), ('of', 3), ('a', 3)]
Ta-dah~這就是資料清洗的魔法~以上就是在python裡面運用NLTK做英文斷詞、初步資料清理跟統計結果的方法。明天會繼續針對中文斷詞的方法做介紹,也教大家怎麼畫出酷炫的文字雲騙一下不會程式的朋友XDD 那就明天見了~


 iThome鐵人賽
iThome鐵人賽