大家晚安~今天要繼續講解深度學習在NLP領域的應用。開始之前讓我們先再次呼喚最default的神經網路模型出來:
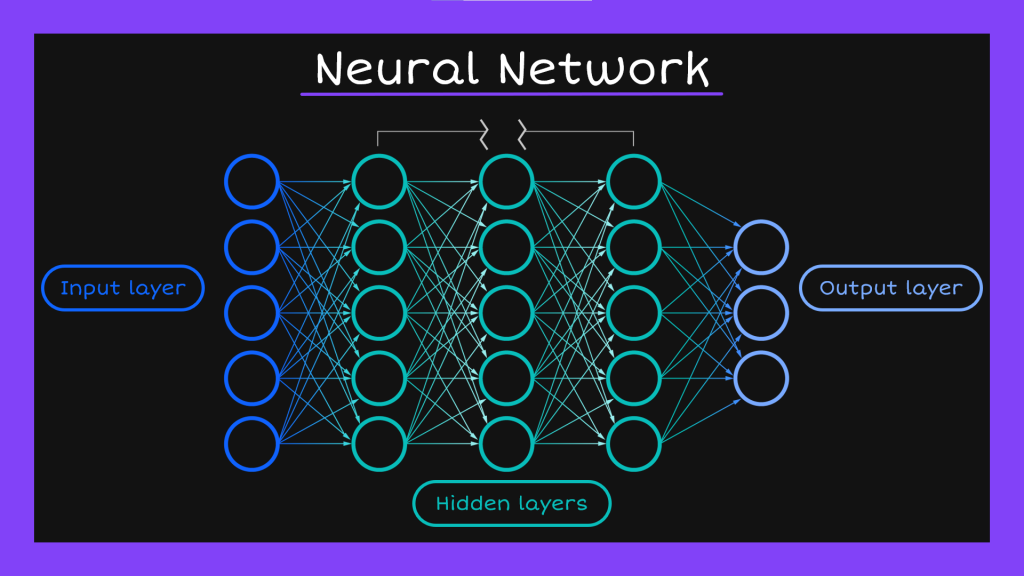
這是最經典簡單的深度神經網路模型,我們可以用它來做一些分類任務。但是這個模型雖然看起來很不錯,對處理語言資料來說卻有著致命的缺點。現在大家可以回想一下我在這個系列文章裡面已經講了N次的自然語言的特徵,那個詞袋模型沒有辦法表現出來的特徵-順序性。說得更白話一點,就是「上下文」。因為所有資料都是以同等的身分進到input layer,各自經過hidden layer的處理後被輸出,所以我們沒辦法考量到他們之間的順序性。這對具有時間先後順序的資料來說也是一樣的問題。以昨天word2vec舉過的例子再更仔細一點說明的話:
我去速食店的時候,都叫漢堡來吃。
我去小吃店的時候,都叫陽春麵來吃。
如果不考慮上下文,那叫漢堡來吃跟叫陽春麵來吃對模型來說都是一樣的,他會覺得當「叫...來吃」的句式出現的時候,不管放漢堡還是陽春麵進去都沒問題。但事實上根本不會有人去速食店叫陽春麵來吃。就算有,他大概也吃不到(?)。所以為了解決這樣的問題,就有了循環神經網路(Recurrent Neural Network, RNN)的出現。
RNN跟一般神經網路模型不一樣的地方在於,他會把前一個輸入的結果記下來,而這個結果會進一步對現在這個state造成影響。就像下面這張圖一樣,原本hidden layer的每個state之間是沒有關係的,他們不會互相影響。但我們在使用RNN的時候會把一個hidden state輸出的數值交給他的下一個hidden state。
那一個hidden state收到上一個hidden state傳過來的數值要怎麼讓這個數值發揮作用呢?用數學的角度想的話就是把他加進公式裡面,想得更簡單一點其實就是除了現階段進來的input之外又多了新的input。假設我們每個時間點t都會輸入兩個字給模型,然後模型的hidden layer有三個state。因為每個hidden state都會有一個輸出,所以每個時間點的輸入都會有兩個字加上三個t-1的時候,hidden state輸出的數值,就像下面這張圖畫的一樣。
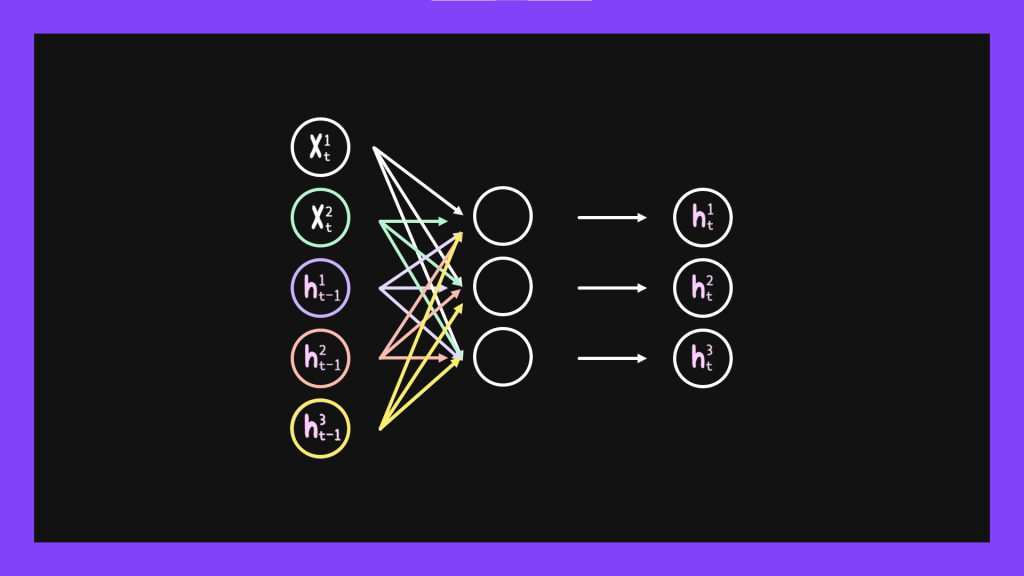
既然前一個hidden state的數值只是做為比較特別的input輸入進來,我們當然就要給他們權重值囉,只是這個權重值跟一般input的權重值會區分開來。因此我們可以得到下面的式子: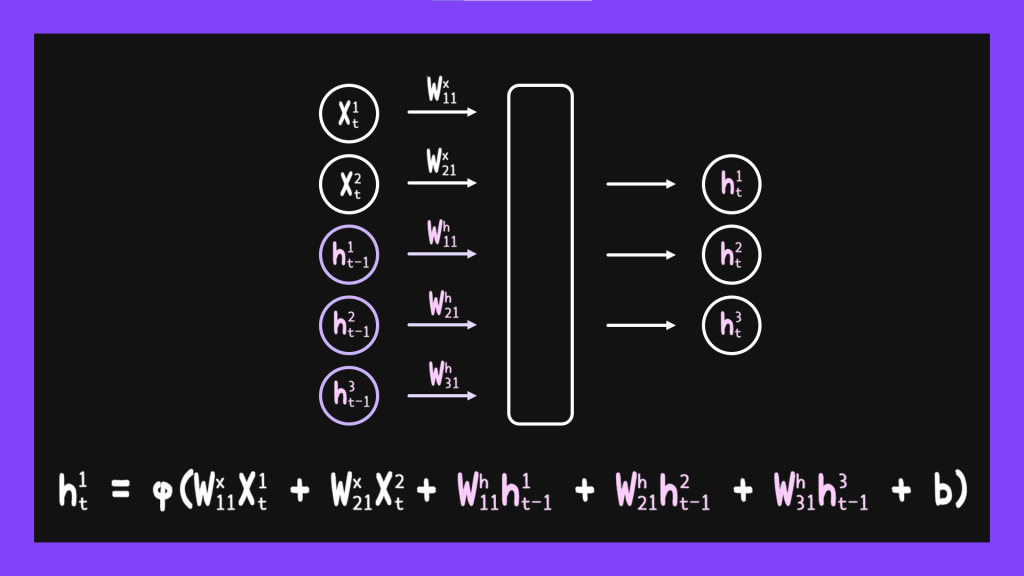
如何?聽起來還滿理想的吧?但模型終究都是有缺點的,RNN的缺點會是什麼呢?這涉及到一些微積分的運算所以在這邊沒辦法詳細說明。簡單說起來就是當前一個hidden state輸出的權重值小於1的時候,會造成訓練越到後面,數值就乘得越小,因此導致前面的權重值沒辦法更新,這樣的結果就會導致分類的準確率下降很多。我們把這樣的情況稱為梯度下降。另外一種情況是當權重值大於1的時候,因為數字越乘越大的關係,就讓模型訓練的結果變得很不穩定,這種狀況叫做梯度爆炸。總之我們可以把他視為RNN記太多前面的東西所造成的,不容小覷的問題。而至於後來專家們是如何試圖要解決這兩個問題的,就留到下一篇再說明了,明天見!


 iThome鐵人賽
iThome鐵人賽