大家午安~昨天講解RNN的時候提到RNN的缺點就是容易產生梯度消失或梯度爆炸的問題,所以今天要介紹為了解決這兩個問題而產生的RNN變體-長短期記憶(Long Short Term Memory)。
因為RNN會一直把前面輸入的東西透過hidden state給出的數值留給下一個state,權重值就很容易越乘越小或越乘越大而造成問題,所以我們在LSTM裡要做的事情就是讓模型適當地忘記一些東西。這其實也比較像是人會做的事情啦,時間久了東西就會被忘掉。就是因為這樣,模型的名字才會叫做長短期記憶。新的input屬於短期記憶,印象鮮明,但是前一個state傳下來的東西屬於長期記憶,所以細節應該被忘掉一點。基本上整個LSTM模型可以用這句話概括,也就是我們讓他運作得更像人類的大腦一樣,對於輸入的東西具有選擇性。
對於如何選擇這些資料,我們可以先想像原本的神經元裡面有一個一個的小工作區,這些工作區分別在進對不同輸入的選擇工作,就像下圖一樣: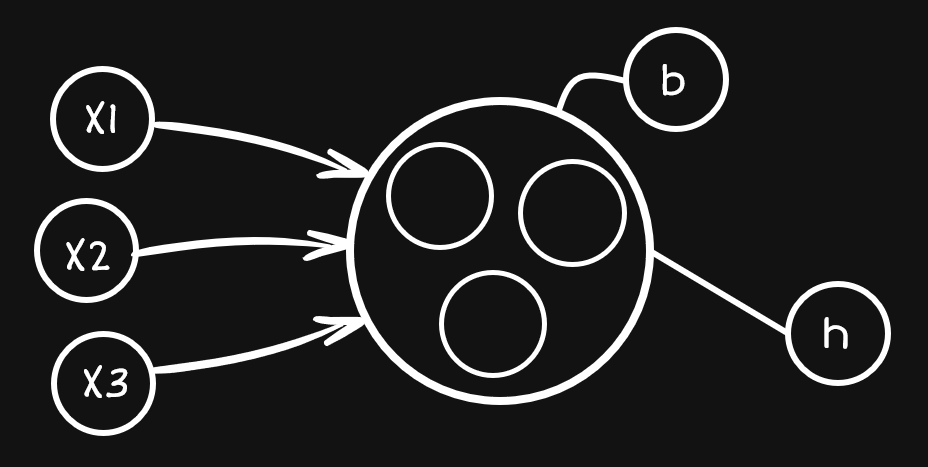
在LSTM模型裡面,我們可以把工作區分成三個:輸入區、忘記區跟輸出區。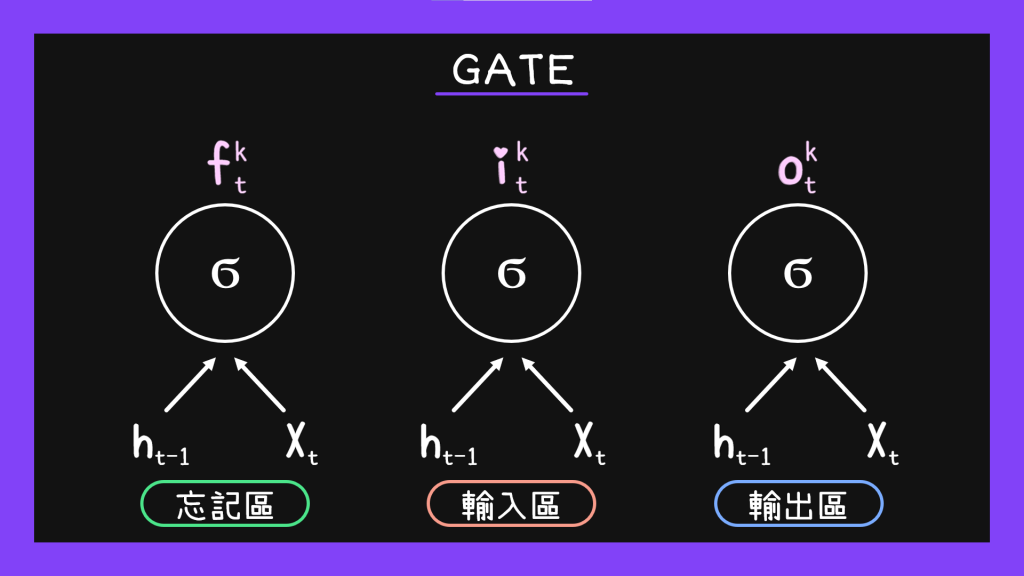
從上面的圖我們可以看到,前一個hidden state傳下來的東西跟input的資料會一起分別進到這三個區域,讓他們可以生出忘記用的權重、input用的權重跟輸出用的權重。接著我們按照正常步驟,以hyperbolic tangent為轉換函數算出一般輸出值。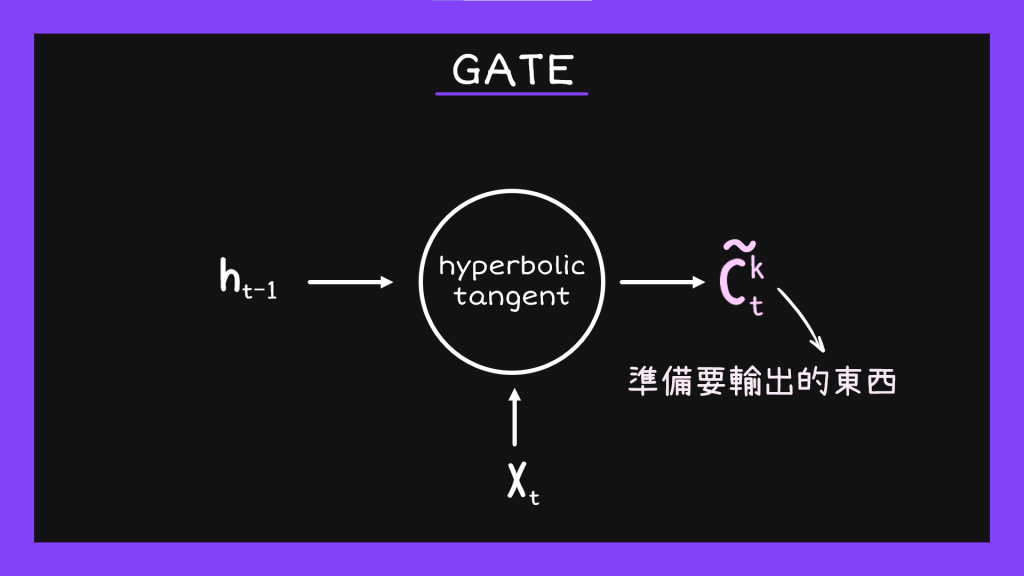
有了上面這些數值之後就可以正式開始工作了。我們先把上面算出來的一般輸出值乘上前面得到的input權重再加上前一個state給我們的數值乘上忘記權重就可以得到我們要交給下一個hidden state的值了。
最後我們把這個值乘上output權重跟激發函數就會得到hidden state真的要輸出的值。以上就是LSTM在做的事情。可能會需要一點時間消化,反正我也是看了很多次才懂的XDD
LSTM的缺點在於,因為他的步驟繁雜所以會需要比較多計算時間。除此之外,加上忘記的機制雖然對於簡單句子來說是有用的,對於結構比較複雜的句子來說(例:有用到關係代名詞的句子),就沒有辦法抓到距離比較遠卻關係強烈的文字。所以為了解決這樣的問題就有了BiLSTM的出現。有興趣的話,大家可以再去研究看看。
那麼今天對LSTM的介紹就到這邊結束了,明天見!


 iThome鐵人賽
iThome鐵人賽