資料中不同變數往往有不同的單位、不同的數值範圍,例如:加速度計所記錄的加速度值單位為m/(s^2),若資料內有光照計的紀錄資料,則單位為0~100不等。若將原始資料直接放入模型中,可能會影響分析的結果。在需要計算變數之間的距離(distance)之模型中就會產生影響,如:KNN,因為距離的數值就會和變數的尺度(scale)非常相關,scale越大對於distance的計算就會有越大的影響。而在tree-based的模型中則不會受到影響,如:決策樹(decision tree)、隨機森林(random forest)等,但在進行模型預測時,往往會使用多個不同的模型來進行比較,因此使用校正後的資料放入模型中是常見的作法,以避免出現不同模型放入不同資料的問題。
為了消除不同單位可能會帶來的影響,因此需要將數據進行正規化(Normalization)與標準化(Standardization)處理,使得不同變項之間具有可比性。
*若要進行模型訓練,則需要分別對訓練資料集以及測試資料集個別進行正規化和標準化
正規化為將原始資料的數據按比例縮放至[0,1]的區間中,且不改變原本的分佈情形。而標準化則會使資料的平均值為0,標準差為1,經過標準化之後,資料會較符合常態分佈,並可以減小離群值對於模型的影響。
Min-Max normalization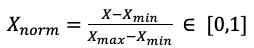
Z-score standardization
假設資料的平均數和標準差為μ,σ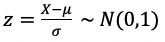
R: 參考
使用套件:caret
library(caret)
norm_data <- dataset2
# 資料包含2個加速度計之數值(6軸)及2個陀螺儀之數值(6軸),由於單位不同,因此需要進行normalization
process <- preProcess(norm_data[,c(1:12)], method=c("range"))
norm_data[,c(1:12)] <- predict(process, norm_data[,c(1:12)])
以下為normalize後的資料,可看到加速度數值和陀螺儀數值皆介於0和1之間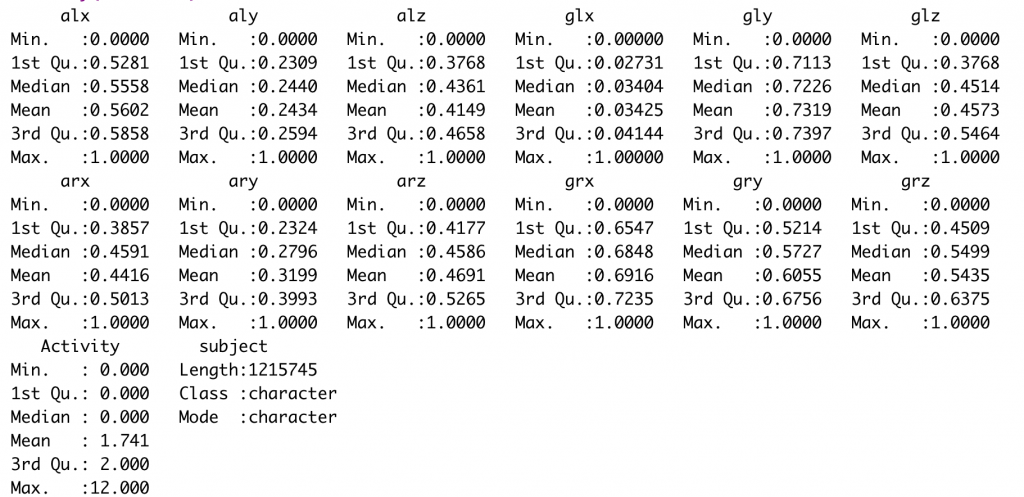
Python: 參考
使用套件:from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
norm_data = dataset2.copy()
scaler = MinMaxScaler()
scaler = scaler.fit(norm_data.iloc[:,0:12])
norm_data.iloc[:,0:12] = scaler.transform(norm_data.iloc[:,0:12]
norm_data.describe()
以下為normalize後的資料,可看到加速度數值和陀螺儀數值皆介於0和1之間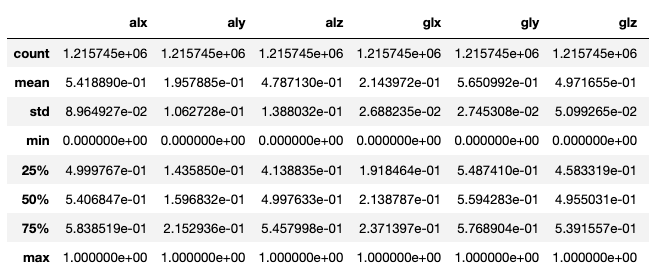
R: 參考
使用函數:scale()
norm_data <- dataset2
# 資料包含2個加速度計之數值(6軸)及2個陀螺儀之數值(6軸)
norm_data[,c(1:12)] <- scale(norm_data[,c(1:12)])
summary(norm_data)
sd(norm_data$alx) # 計算標準差
以下為standardize後的資料,可看到加速度數值和陀螺儀數值的平均值為0,標準差為1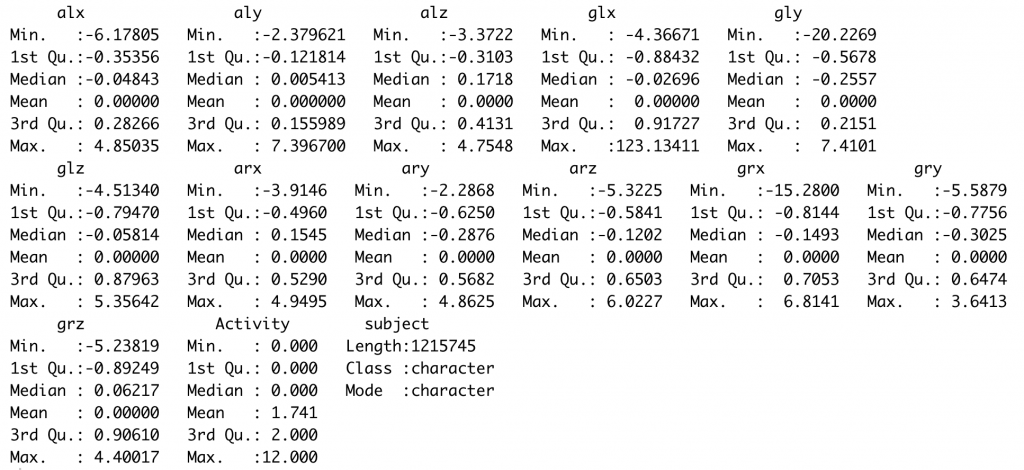

Python: 參考
使用套件:from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import StandardScaler
norm_data = dataset2.copy()
scaler = StandardScaler()
scaler = scaler.fit(norm_data.iloc[:,0:12])
norm_data.iloc[:,0:12] = scaler.transform(norm_data.iloc[:,0:12])
norm_data.describe()
以下為standardize後的資料,可看到加速度數值和陀螺儀數值的平均值接近0,標準差為1,而平均值並不等於0的原因為浮點數進位的問題,但計算出的平均值仍非常接近0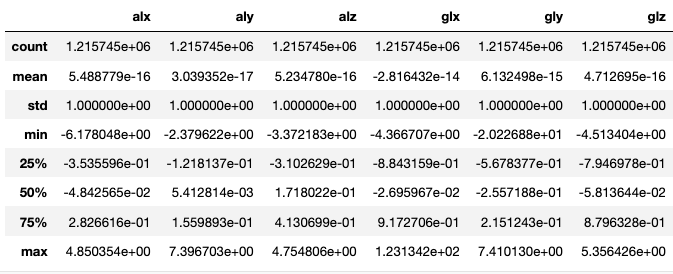


 iThome鐵人賽
iThome鐵人賽