還記得我們在第三天第四天做了的情感分析嗎?判斷句子是 Positive 還是 Negative 這是屬於 text classification 的範圍,算是自然語言處理最入門的範疇。接下來我們就會用 text classification 作為範例,一步步來了解 Hugging Face。
我們都知道做 AI 最重要的就是 dataset ,沒有資料就很難以訓練 AI 模型。因此我們今天就先從 dataset 的部份開始吧!
我們可以在 Hugging Face Hub 的網站上,找到 Datasets 的頁面。
在這裡有近萬個(可能過再過不久就破萬) datasets,大家可以在可以這裡看到許多不同的 datasets ,如下圖所示。
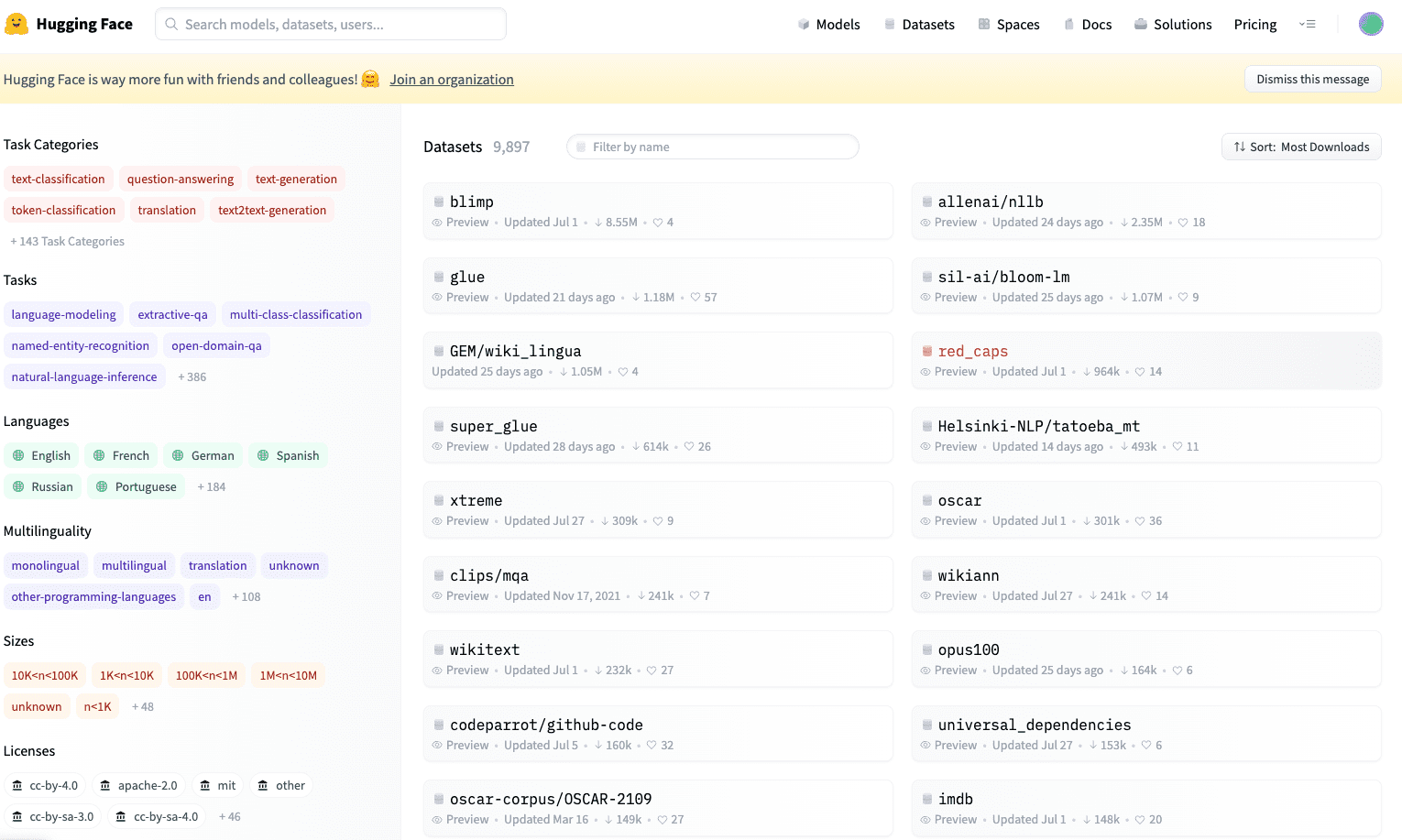
排名第一個的是目前下載量最多的是dataset: BLiMP。這個是目前最受歡迎的,評估自然語言處理模型的表現的 dataset。有興趣的朋友可以參考這篇論文。
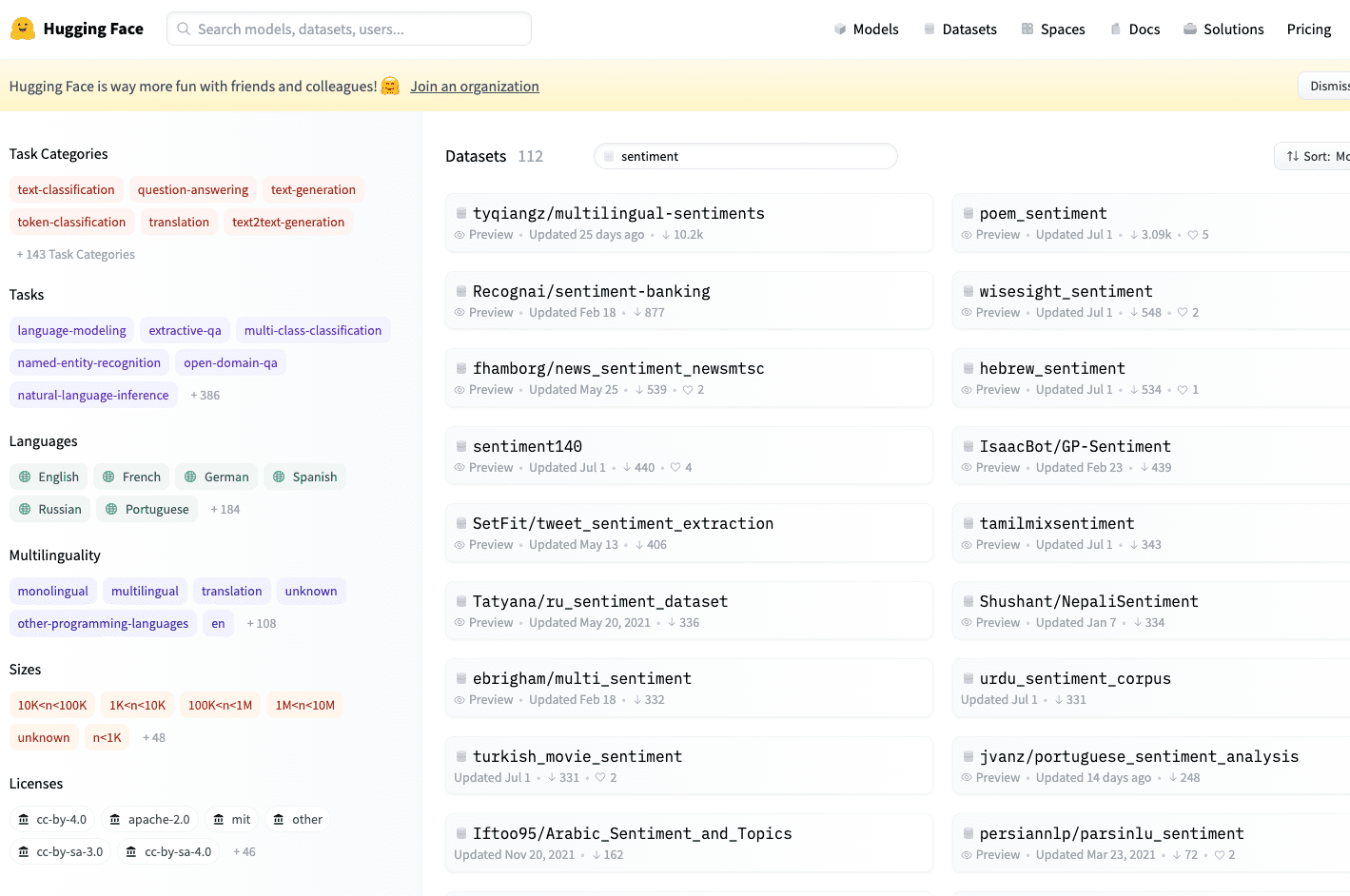
我們也可以在上方的搜尋欄,尋找我們想要的模型。像我們這幾天試玩的是 sentiment,我們就輸入 sentiment ,就會看到很多相關的 datasets 出現了。如下圖。
我們可以選擇 poem_sentiment 這個 dataset 來看看,可以看到這個 dataset 除了 positive 和 negative 之外,還有 no_impact 和 mix 等 label,如下圖。也是啦,一首詩句有時候不一定是正面或是負面的情緒,也有可能多種混在一起。我們就來選用這個 dataset 吧!
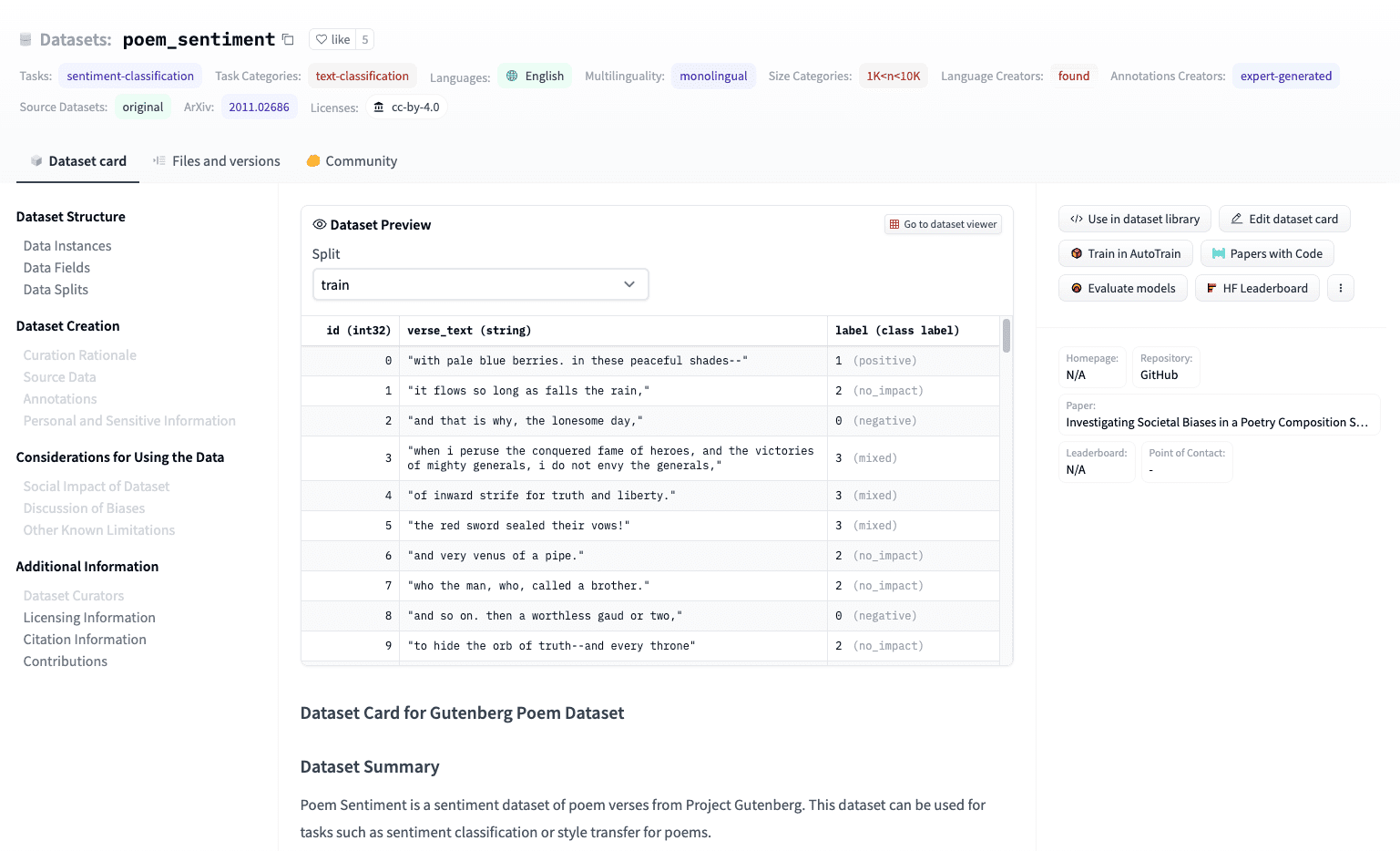
另外我們還可以從這個頁面,得到更多的資訊。像是這個 dataset 是出自這篇論文:Investigating Societal Biases in a Poetry Composition System。還有它是英文的 dataset、資料的數量、授權等等的。像是頁面的最下方,還有引用這個 dataset 時需要附上的引用資訊。
@misc{sheng2020investigating,
title={Investigating Societal Biases in a Poetry Composition System},
author={Emily Sheng and David Uthus},
year={2020},
eprint={2011.02686},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
大家在使用時一定也要特別留意這些地方!
明天我們就來開始看 Hugging Face Datasets Library 的使用吧!


 iThome鐵人賽
iThome鐵人賽