當我們了解了 AI 的各種手法,就可以知道哪些想法在 AI 技術上是可行的,也能針對我們的目標知道需要什麼資料和要使用什麼演算法來建立模型(Model)。
使用演算法從資料找出函數,就是一般常說的建立模型。建立模型很花時間,但拿建好的模型做預測只需要一瞬間。就好像我們花很多時間從 ABC 開始學習英文的單字和文法,等到學完後看英文文章就很快一樣。
要讓 AI 落地應用,需要普及 AI 知識,讓不是工程師的人知道可以用 AI 做什麼,然後和工程師討論。甚至是自己捲起袖子當 AI 工程師,因為這些學習演算法其實被包裝得很好,是很方便使用的工具,有興趣的人可以參考之後範例程式的程式碼。
機器學習根據學習方式的不同,主要有以下幾個種類:
簡單說就是資料有給答案的學習。上一篇有講過讓機器去學習輸入和輸出的關係,透過演算法找出函數來做預測。
就像是老師教小孩一樣,小孩指著貓咪說是狗狗,老師會給答案糾正他說不對,這是貓咪,這樣小孩子就知道長這個樣子的動物是貓咪。之後就懂得辨識貓與狗的外觀。
這種資料和答案成對的數據,稱為標籤資料(labeled data)
如同衣服上面貼品牌標籤一樣,對著動物的圖片給一個動物名稱的標籤。例如:
{ :"貓"}
:"貓"}
—— 圖片出處:ねこちゃんホンポ
監督式學習可以解決回歸和分類問題

| 名稱 | 用途 |
|---|---|
| 線性回歸 | 回歸 |
| 邏輯回歸 | 分類 |
| K 近鄰 | 兩者皆可 |
| 隨機森林 | 兩者皆可 |
| 梯度提升 | 兩者皆可 |
| 支持向量機 | 兩者皆可 |
| 神經網路 | 兩者皆可 |
兩者皆可的演算法通常是基本構成一樣只是做了微調做預測對象的切換。列表上的演算法後面會一一介紹。這邊有個印象即可。
資料沒有答案的學習,資料上面沒有給標籤。
就像是小孩在沒有老師給答案的情況下,自己透過資訊把一些東西歸納在一起。比如說小孩還不知道什麼是植物和動物,但是會自然而然把靜態的花和樹分同一類,而動態的狗狗和貓咪分同一類。
非監督式學習通常有三種用法:
聚類(Clustering)
在不知道答案的情況下找出資料間的相似程度。把相似的資料聚在一起成一個類別,所以叫做聚類。 例如針對購買傾向相似和不相似的客戶做市場區隔,又或是反過來做異常偵測,去抓出和平常特別不一樣的資料,例如突然出現的大量國外信用卡消費,有可能是被盜刷。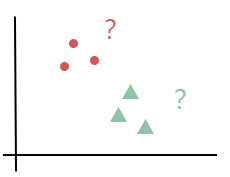
推薦系統(Recommendation System)
針對購物籃分析,客戶一次購物會買哪些東西,推薦類似或附屬商品給客戶刺激消費。
降維(Dimension Reduction)
當特徵太多,計算量太大,把一些關係不大的特徵去除掉。
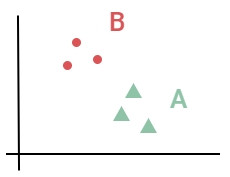
而監督式學習的分類和無監督式的聚類差別在:
Google 採用無監督式辨識出貓,就是在沒有標籤資料,不懂貓這個類別的情況下,還是能把貓的圖片都歸在同一類,只是這個類別是未知類別(沒有答案),但是人類一看就知道這個類別是貓。
| 名稱 | 用途 |
|---|---|
| K 平均 | 無階層聚類 |
| 沃德法(Ward) | 有階層聚類 |
| 主題模型 | 一份資料有多個聚類 |
| 關聯規則 | 推薦系統 |
| 主成分分析(PCA) | 降維 |
介於監督式和無監督式之間。資料有的有標籤,有的沒標籤。
就像是老師教小孩學發音,一開始教了「糖」的發音、並告訴小孩白白的甜甜的這個叫做「糖」,之後小孩聽到「糖果」,「糖粉」,「糖漿」,儘管老師沒有告訴小孩這些是什麼,小孩也會從發音的相似性把這些詞歸在一類,並和甜甜白白的聯想在一起。
上面是語音辨識的半監督式學習例子。其實小孩從小到大的學習都是屬於半監督式學習,畢竟父母和老師不會隨時給小孩全部的答案。
監督式學習可以用答案矯正所以準確率很高,但是很多時候資料一開始沒有答案,如果把所有的圖像或聲音貼上標籤,人力成本就太高,而無監督式雖然成本低但自行做的聚類不一定正確,這時候使用一部分有標籤的資料先找出好的特徵可以讓預測比起全部使用無監督式來得精準。
使用懲罰和獎勵邊做邊修正,做了動作之後透過環境回饋的獎懲來修正自已下一步的動作。
就像教育小孩的行為一樣,如果做錯事就懲罰他,做對事就獎勵他,於是小孩學習到哪些事不能做,哪些事做了會有好處,逐漸形成他的行為模式。
| 名稱 | 用途 |
|---|---|
| 吃角子老虎機 | 策略平衡 |
| 價值函數 | 導入了價值概念 |
| 策略梯度 | 用函數找出更好的策略 |
使用深度學習做的強化學習,會在深度學習模型篇章講解。
適合做一連串決策的動作。
例如棋盤遊戲(知名的 AlphaGo 就是採用強化學習)、機器手臂和自動駕駛汽車。
在監督式學習裏有一個天下沒有免費的午餐定理(No Free Lunch Theorem),用來說明沒有一個演算法可以完美對應所有問題。特別是深度學習流行的現在,我們可能會誤以為神經網路可以1個打10個,但其實神經網路需要的資料量和計算遠比其他的演算法要多,AI 的可解釋性也沒有決策樹來的簡單,所以還是要針對我們的問題來選擇演算法。
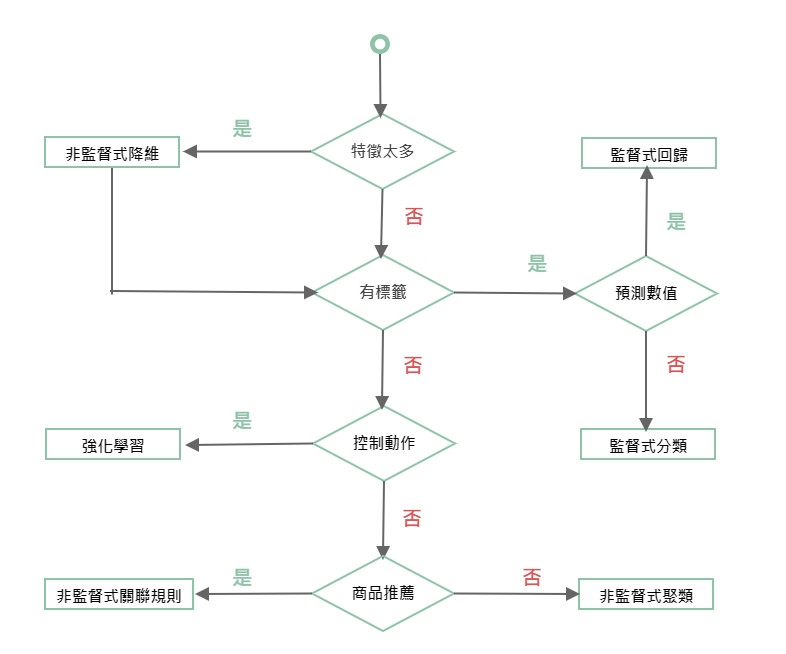
這邊做了一個學習選擇流程圖幫助了解使用的時機。
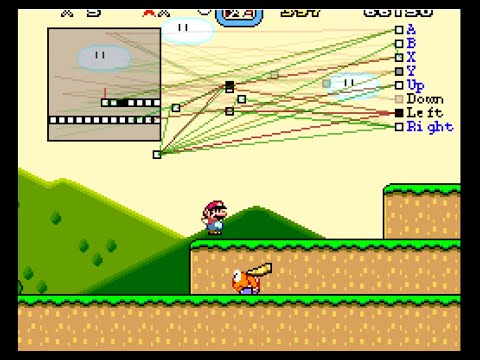
還記得 Day1 一開始提到的親身經歷嗎,那時候的遊戲雖然沒用上強化學習,但是影像辨識加上 Rule Based 的條件設定也達到類似的效果。


 iThome鐵人賽
iThome鐵人賽