資料視覺會是最常被使用的方法之一,除了樞紐分析快速幫助原始資料來進行分組與分類外,另外一種執行的方式是直接進行原始資料搜尋來做視覺化,視覺化能夠讓閱讀者更加的直覺了解資料彼此之間的相關聯以及其與其他資料集的關聯性,快速的進行相關性分析與轉換。
「資料間的關聯性」可以說是資料分析中最重要的一件事情之一,我們進行數據分析可以了解售價與購買意願的差別,可以了解商品成交量與顧客評價的差異,在這篇文章中也能了解鐵達尼號各項指標與存活率的關聯性。關聯性的應用程面甚至遠到未來機器學習與深度學習中,也是藉由資料與資料間的關聯性來找出其中的機會。
一般來說直方圖(histogram chart)對於分析連續數值變量(如年齡)很有用,其中帶狀或範圍將有助於識別有用的模式。直方圖可以觀察樣本的分佈,這有助於我們回答與特定波段相關的問題
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20)
我們可以注意到的觀察點
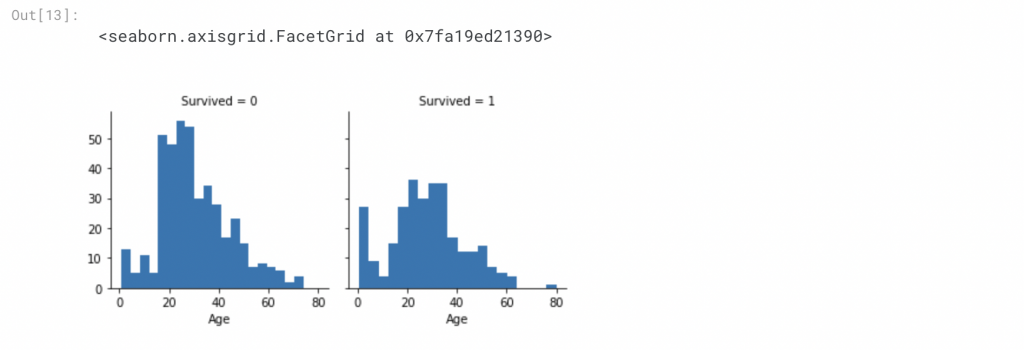
我們可以使用單個圖組合多個特徵來識別相關性。這可以通過具有數值的數值和分類特徵來完成。
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', height=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend();
我們可以注意到的觀察點
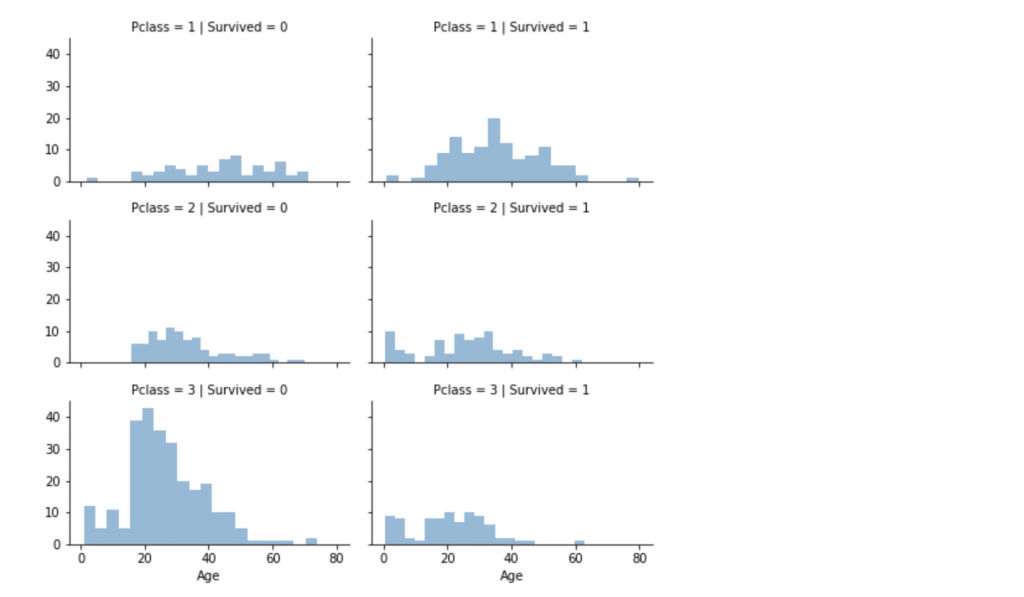
或者是說將分類特徵與我們的解決方案目標相關聯。
grid = sns.FacetGrid(train_df, col='Embarked')
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend()
我們可以注意到的觀察點
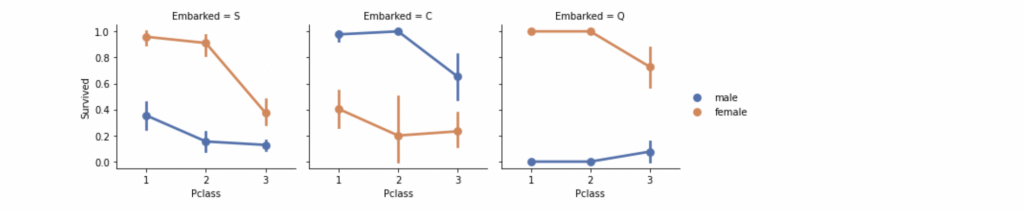
我們可能還希望將分類特徵(具有非數字值)和數字特徵相關聯。 我們可以考慮將 Embarked(分類非數字)、Sex(分類非數字)、Fare(連續數字)與 Survived(分類數字)關聯。
grid = sns.FacetGrid(train_df, row='Embarked', col='Survived', height=2.2, aspect=1.6)
grid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)
grid.add_legend()
我們可以注意到的觀察點
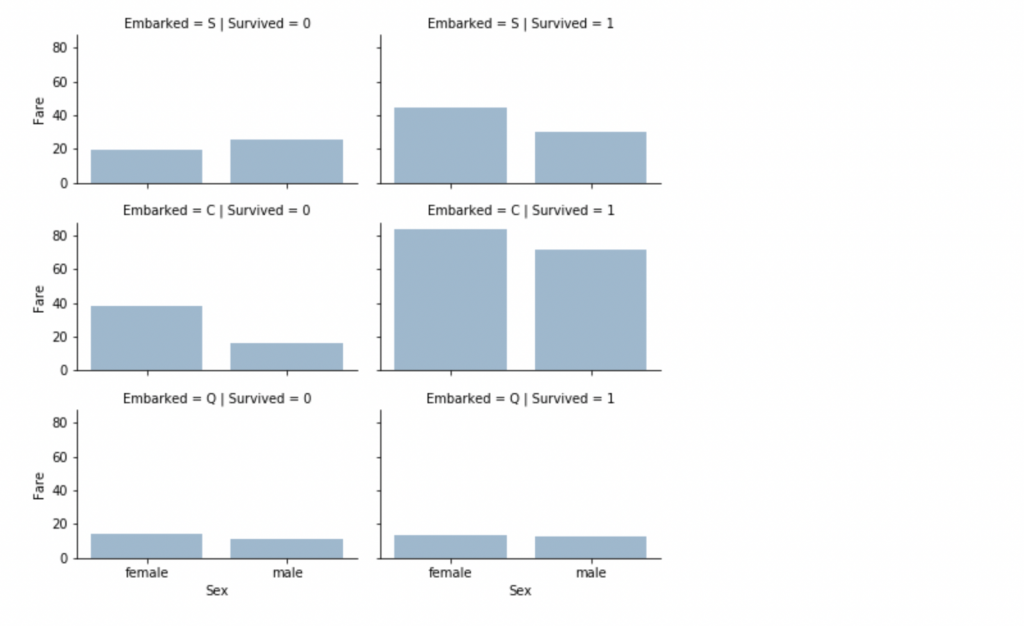
以上主要是根據現有的資料集來做特徵辨識,我們根據已有的資料來做視覺化分析與解讀,可視化大大的幫助了我們降低對於數據解讀的難度,而且能夠更有利的驗證我們本身的假設。但是值得注意的是在實際的資料集中,更有可能會有缺值的狀況發生,因此下一篇文章我們將會討論放棄特徵議題,來優化整體數據分析,或是進行資料糾正。
今年沒組團,每一筆一字矢志不渝的獻身精神都是為歷史書寫下新頁,有空的話可以走走逛逛我們去年寫的文章。
Jerry 據說是個僅佔人口的 4% 人口的 INFP 理想主義者,總是從最壞的生活中尋找最好的一面,想方設法讓世界更好,內心的火焰和熱情可以光芒四射,畢業後把人生暫停了半年,緩下腳步的同時找了份跨領域工作。偶而散步、愛跟小動物玩耍。曾立過很多志,最近是希望當一個有夢想的人。
謝謝你的時間「訂閱,追蹤和留言」都是陪伴我走過 30 天鐵人賽的精神糧食。

