我們介紹過DataFrame表現得既像二維數組又像由共同的索引值組成的Series對象的字典。這能幫助你學習如何在DataFrame裡面進行數據選擇。
前面內容介紹的Series和DataFrame對像都包含著一個顯式定義的索引index對象,它的作用就是讓你快速訪問和修改數據。
indA.size # returns the size
indA.shape # returns the shape
indA.ndim # returns the number of dimensions in the data
indA.dtype # returns the data type
indA.nbytes # returns the number of bytes in the data
indA.empty # checks if the series is empty or not
indA.hasnans # checks if the series has any nan value
indA.intersection(indB) #indA & indB # 交集
indA.union(indB) #indA | indB # 聯集
indA.symmetric_difference(indB) #indA ^ indB # 互斥差集
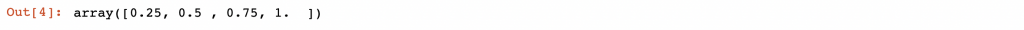
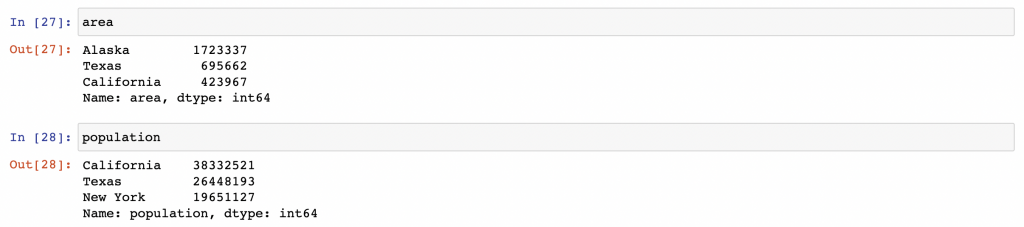
對於兩個Series或DataFrame進行二元運算操作,Pandas會在運算過程中會自動將兩個數據集的索引進行對齊操作。這對於我們處理不完整的數據集的情況下非常方便,下面我們來看一些例子,假設我們從兩個不同的數據源分別獲得美國的州大小和人口。
area = pd.Series({'Alaska': 1723337, 'Texas': 695662,'California': 423967}, name='area')
population = pd.Series({'California': 38332521, 'Texas': 26448193,'New York': 19651127}, name='population')
我可以利用 union 來尋找其聯集,利用這個方式可以找出索引
area.index.union(population.index) # union
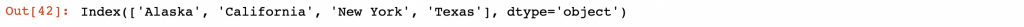
兩個任意輸入數據集中對應的另一個數據集不存在的元素都會被設置為 NaN(非數字的縮寫),也就是Pandas標示缺失數據的方法:如果填充成NaN值不是你需要的結果,你可以使用相應的ufunc函數來計算,然後在函數中設置相應的填充值參數。例如,調用A.add(B)等同於調用A + B,但是可以提供額外的參數來設置用來缺失的替換值:
area + population

area.add(population, fill_value=0)

下面列出了Python的運算操作及其對應的Pandas方法:

今年沒組團,每一筆一字矢志不渝的獻身精神都是為歷史書寫下新頁,有空的話可以走走逛逛我們去年寫的文章。
Jerry 據說是個僅佔人口的 4% 人口的 INFP 理想主義者,總是從最壞的生活中尋找最好的一面,想方設法讓世界更好,內心的火焰和熱情可以光芒四射,畢業後把人生暫停了半年,緩下腳步的同時找了份跨領域工作。偶而散步、愛跟小動物玩耍。曾立過很多志,最近是希望當一個有夢想的人。
謝謝你的時間「訂閱,追蹤和留言」都是陪伴我走過 30 天鐵人賽的精神糧食。

